david wrote:
Blueskull wrote:
我跑的是简单的几何图形检测(贴片捡放机,找零件位置和pin1圆圈)
这感觉挺好,啥时候出产品。
遥遥无期。业余爱好,时间不多。天天公司早九晚六,通勤吃饭健身到家就9点了,再处理一下邮件,做做明天的材料,看会傻缺视频,就该洗澡睡觉了。
]]>Blueskull wrote:
我跑的是简单的几何图形检测(贴片捡放机,找零件位置和pin1圆圈)
这感觉挺好,啥时候出产品。
]]>jiangchun9981 wrote:
但缺点好像就是内存太小,我训练50张图片出来的模型都很大了? ?? 更别说那些训练几千张的模型(一般有几百M了),这点不知道大家如何解决的?
不需要也别快的话可以从SPI加载模型,然后往KPU里面倒腾。K210有MMU,可以SPI映射内存,但是K210用的RiscV版本有bug,MMU看现在的RV手册不好使,得参考某个特定版本的MMU手册。有个日本人搞出来了,可以把完整的16MB NOR映射成内存。
我用K210不跑实际训练的模型,所以不是很在乎内存大小。我跑的是简单的几何图形检测(贴片捡放机,找零件位置和pin1圆圈),都有数学表达式的,可以直接推出来卷积核,pooling参数和激活函数,模型特别简单。
]]>
但缺点好像就是内存太小,我训练50张图片出来的模型都很大了? ?? 更别说那些训练几千张的模型(一般有几百M了),这点不知道大家如何解决的?
还有个方案是外挂AI芯片,国内有"光矛"这个,通过SD接口可以和任意芯片连接,算力也有个1T吧 ,价格也是几十块钱 ,但这个方案好像不如RK1808内置的,都的上LINUX+外接DDR内存芯片,有点复杂
]]>armstrong wrote:
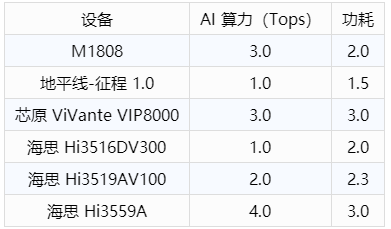
请问:算力的具体意义是什么,有统一标准吗?
对AI来说,算力一般指的是计算8比特数据的能力。先乘后加算两次运算。
所以一个400MHz主频,576个乘加器的NPU就有0.45762=0.46T的算力(K210)。
K210可以超频到800MHz,但是要加压,功耗和稳定性都炸了。现实点说600MHz没问题,也就是0.69T算力。
K210的所有内存都是单周期片上SRAM,这一点比外挂内存的芯片强太多了。6MB用于CPU程序和NPU模型,2MB用于NPU数据。
CPU可以寻址全部8MB空间,NPU只能寻址2MB的NPU数据内存,NPU的模型要逐层由CPU加载到NPU里面。
NPU模型内存只存储当前计算层的参数,独立于上述8MB之外。
容量小是硬伤,但是速度快很爽。
如果你的模型能压缩到6MB以下,而且层数据(当前+下一层)能做到2MB以下,K210应该实际速度比那些号称1T/2T/3T的基于外部DRAM的方案快的多。
这芯片潜力很大,但是就是文档太日狗了。没有内部人士帮忙想跑tinyyolo以外的任何东西基本上都不可能。
jiangchun9981 wrote:
搞深度学习的吗?
可以关注K210这个芯片,基本算裸机的,算力好像有1T OPS,基本是秒杀目前大部分SOC的GPU了,包括骁龙845,855这种等级的
RK1808也有3T的算力,目前好像的跑LINUX,但基本也算轻量级
请问:算力的具体意义是什么,有统一标准吗?
]]>可以关注K210这个芯片,基本算裸机的,算力好像有1T OPS,基本是秒杀目前大部分SOC的GPU了,包括骁龙845,855这种等级的
RK1808也有3T的算力,目前好像的跑LINUX,但基本也算轻量级
]]>Blueskull wrote:
几乎不可能。shader要编译的,编译器一般是jit的,驱动里面实现的。一般gpu的驱动超级复杂,是一个完整的编译器+优化器,而且还得负责分配gpu资源。
多谢!
]]>