楼主 #1 2020-05-26 22:53:42 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
f1c100s spi不能使用burst模式???
坛子里,f1c100s例程操作spiflash的做法都是都是通过spi单次收发的方式模拟03命令序列,这种做法很低效,坛子里很多网友说过这个问题了
我仔细研读手册,发现f1c100s支持spi突发模式,和双线模式,如果能用上这两个特点的话,程序加载会增长一倍以上
Armstrong兄的例程spiflash加载程序只需要不到1秒就能显示画面,如果再优化一下,估计不到0.5秒就可以了,真正做到秒开
现在的问题,以下代码在用户程序中是完好的,在spl代码中却不行,不知道谁能发现其中奥妙?
void sys_spi_flash_read(int addr, void* buf, int count)
{
uint8_t *p = (uint8_t *)buf;
SPI0->TXD = 0x03 | util_rev(addr);
SPI0->MBC = 4 + count;
SPI0->MTC = 4;
SPI0->BCC = 4;
SPI0->TCR |= SPI_TCR_XCH;
while (count > 0) {
if((SPI0->FSR & SPI_FSR_RXFIFO_CNT) >= 1)
{
*p++ = *(uint8_t *)&SPI0->RXD;
count -= 1;
}
}
}离线
楼主 #2 2020-05-28 12:02:40 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
Re: f1c100s spi不能使用burst模式???
没有人对这个问题有兴趣?
离线
#3 2020-05-28 17:36:42 分享评论
- shaoxi2010
- 会员
- 注册时间: 2019-06-13
- 已发帖子: 399
- 积分: 338
Re: f1c100s spi不能使用burst模式???
没看懂这个问题,我记得没错uboot的spl不就是burst么,一次性就读取完了并非一个个发地址阿。
还是你说的是DMA的burst?双线读取我试过内核驱动没什么问题,理论上也能在spl中用。
离线
楼主 #4 2020-05-28 20:09:18 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
Re: f1c100s spi不能使用burst模式???
shaoxi2010 wrote:
没看懂这个问题,我记得没错uboot的spl不就是burst么,一次性就读取完了并非一个个发地址阿。
还是你说的是DMA的burst?双线读取我试过内核驱动没什么问题,理论上也能在spl中用。
以下是Armstrong兄的例程代码,读取flash的具体过程,应该也是xboot的
static int sys_spi_transfer(void* txbuf, void* rxbuf, int len)
{
uint32_t addr = 0x01c05000;
int count = len;
uint8_t* tx = txbuf;
uint8_t* rx = rxbuf;
uint8_t val;
int n, i;
while (count > 0) {
n = (count <= 64) ? count : 64;
write32(addr + SPI_MBC, n);
sys_spi_write_txbuf(tx, n);
write32(addr + SPI_TCR, read32(addr + SPI_TCR) | (1UL << 31));
while ((read32(addr + SPI_FSR) & 0xff) < n);
for (i = 0; i < n; i++) {
val = read8(addr + SPI_RXD);
if (rx)
*rx++ = val;
}
if (tx)
tx += n;
count -= n;
}
return len;
}明显这里是有多次spi burst的
离线
#5 2020-05-28 21:32:20 分享评论
- armstrong
- 会员

- 注册时间: 2019-04-10
- 已发帖子: 295
- 积分: 189.5
Re: f1c100s spi不能使用burst模式???
F1C100s的SPI模块有64字节接收FIFO和64字节发送FIFO。
上面的代码把count分成多份接收,每份最多接收64字节,这是充分利用接收FIFO;发送同理。
每次往TXD寄存器只写1个字节,没试过你这样往TXD一次写4字节。
其实即便一次写4字节,也不能提高速度的;因为处理器写1字节的时间远小于SPI传送1字节的时间,所以最终瓶颈还是在SPI传输上。
最近编辑记录 armstrong (2020-05-28 21:39:54)
离线
楼主 #6 2020-05-29 09:49:50 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
Re: f1c100s spi不能使用burst模式???
armstrong wrote:
F1C100s的SPI模块有64字节接收FIFO和64字节发送FIFO。
上面的代码把count分成多份接收,每份最多接收64字节,这是充分利用接收FIFO;发送同理。
每次往TXD寄存器只写1个字节,没试过你这样往TXD一次写4字节。
其实即便一次写4字节,也不能提高速度的;因为处理器写1字节的时间远小于SPI传送1字节的时间,所以最终瓶颈还是在SPI传输上。
感谢Armstrong的亲临指导,我今天再去测试一下原来代码spi读写的情况,spi频率太高了示波器太烂丢脉冲,不过应该可以发现问题的
原来的代码相当于将总的数据收发切割成64字节成组收发,并且读取rxfifo时候还是spi停止的
64+4字节收发->读rxfiofo,然后再重复这个过程
由于spi频率是ahb的1/4,因此一个字节spi相当于32次ahb操作, fifo读刚好等效2个字节的收发
最近编辑记录 myxiaonia (2020-05-29 10:20:33)
离线
#7 2020-05-29 10:07:54 分享评论
- armstrong
- 会员
- 注册时间: 2019-04-10
- 已发帖子: 295
- 积分: 189.5
Re: f1c100s spi不能使用burst模式???
myxiaonia wrote:
感谢Armstrong的亲临指导,我今天再去测试一下原来代码spi读写的情况,spi频率太高了示波器太烂丢脉冲,不过应该可以发现问题的
原来的代码相当于将总的数据收发切割成64字节成组收发,并且读取rxfifo时候还是spi停止的
64+4字节收发->读rxfiofo,然后再重复这个过程
读FIFO时,SPI是停止的;这里的确浪费了传输机会。
不过,count循环中并不会重复发送4字节命令和地址,因为在读取数据时,sys_spi_transfer函数的txbuf参数是NULL,所以循环内的sys_spi_write_txbuf函数会立即返回,没有实际数据发送的。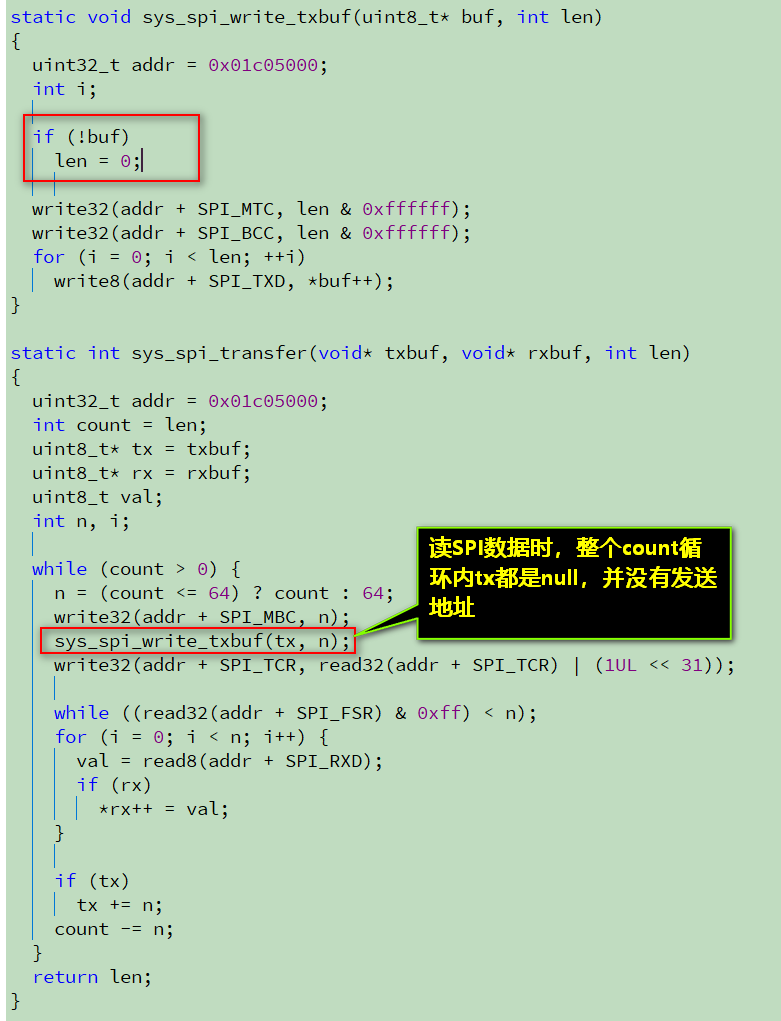
上层的flash读函数实际上这样解释:
static int sys_spi_write_then_read(void* txbuf, int txlen, void* rxbuf, int rxlen)
{
// 发送命令+地址
if (sys_spi_transfer(txbuf, NULL, txlen) != txlen)
return -1;
// 连续接收纯数据
if (sys_spi_transfer(NULL, rxbuf, rxlen) != rxlen)
return -1;
return 0;
}离线
楼主 #8 2020-05-29 10:21:12 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
Re: f1c100s spi不能使用burst模式???
这个确实是,那就是只有2个字节的开销,看上去也比较小
离线
#9 2020-05-29 12:06:42 分享评论
- armstrong
- 会员
- 注册时间: 2019-04-10
- 已发帖子: 295
- 积分: 189.5
Re: f1c100s spi不能使用burst模式???
myxiaonia wrote:
这个确实是,那就是只有2个字节的开销,看上去也比较小
我看了手册,F1C100s不支持SPI双线接收模式【即4个clk传输8位的模式】,所以没多少优化空间了。
离线
#10 2020-05-29 20:14:45 分享评论
- jou_1703
- 会员
- 注册时间: 2019-10-13
- 已发帖子: 12
- 积分: 12
Re: f1c100s spi不能使用burst模式???
不是有个SPI DMA吗?可以加速吗?
离线
楼主 #11 2020-06-02 08:24:12 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
Re: f1c100s spi不能使用burst模式???
armstrong wrote:
读FIFO时,SPI是停止的;这里的确浪费了传输机会。
不过,count循环中并不会重复发送4字节命令和地址,因为在读取数据时,sys_spi_transfer函数的txbuf参数是NULL,所以循环内的sys_spi_write_txbuf函数会立即返回,没有实际数据发送的。
/files/members/1592/2020-05-29_100040.png
上层的flash读函数实际上这样解释:static int sys_spi_write_then_read(void* txbuf, int txlen, void* rxbuf, int rxlen) { // 发送命令+地址 if (sys_spi_transfer(txbuf, NULL, txlen) != txlen) return -1; // 连续接收纯数据 if (sys_spi_transfer(NULL, rxbuf, rxlen) != rxlen) return -1; return 0; }
这两天忙其它事情一直没时间测试,刚刚我测试结果,每64字节收发中间有3.6us停顿,相当于22.5个字节收发,这个开销比我预计的还要大bu shao
离线
#12 2020-06-02 17:28:37 分享评论
- armstrong
- 会员
- 注册时间: 2019-04-10
- 已发帖子: 295
- 积分: 189.5
Re: f1c100s spi不能使用burst模式???
myxiaonia wrote:
读FIFO时,SPI是停止的;这里的确浪费了传输机会。
不过,count循环中并不会重复发送4字节命令和地址,因为在读取数据时,sys_spi_transfer函数的txbuf参数是NULL,所以循环内的sys_spi_write_txbuf函数会立即返回,没有实际数据发送的。
/files/members/1592/2020-05-29_100040.png
我还没用逻辑分析仪测量过。要把这些时间省下来,就只能靠DMA了。
离线
楼主 #13 2020-06-03 08:55:48 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
Re: f1c100s spi不能使用burst模式???
armstrong wrote:
我还没用逻辑分析仪测量过。要把这些时间省下来,就只能靠DMA了。
可以用类似我开头那种做法,完全可以一次性读完,不需要64字节分组收发嘛,就是不知道为何不对:(
离线
#14 2020-06-03 10:09:06 分享评论
- armstrong
- 会员
- 注册时间: 2019-04-10
- 已发帖子: 295
- 积分: 189.5
Re: f1c100s spi不能使用burst模式???
myxiaonia wrote:
可以用类似我开头那种做法,完全可以一次性读完,不需要64字节分组收发嘛,就是不知道为何不对:(
试试看这样写行不?
void sys_spi_flash_read(int addr, void* buf, int count)
{
uint8_t *p = (uint8_t *)buf;
sys_spi_select();
SPI0->MBC = 4;
SPI0->MTC = 4;
SPI0->BCC = 4;
SPI0->TXD = 0x03 | util_rev(addr);
SPI0->TCR |= SPI_TCR_XCH;
while (SPI0->FSR & 0xff) < 4);
read8((uint32_t)&SPI0->RXD);
read8((uint32_t)&SPI0->RXD);
read8((uint32_t)&SPI0->RXD);
read8((uint32_t)&SPI0->RXD);
SPI0->MBC = count;
SPI0->MTC = 0;
SPI0->BCC = 0;
SPI0->TCR |= SPI_TCR_XCH;
while (count > 0) {
if((SPI0->FSR & 0xFF) > 0)
{
*p++ = read8((uint32_t)&SPI0->RXD);
count -= 1;
}
}
sys_spi_deselect();
}最近编辑记录 armstrong (2020-06-03 10:13:43)
离线
楼主 #15 2020-06-03 11:00:01 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
Re: f1c100s spi不能使用burst模式???
armstrong wrote:
试试看这样写行不?
void sys_spi_flash_read(int addr, void* buf, int count) { uint8_t *p = (uint8_t *)buf; sys_spi_select(); SPI0->MBC = 4; SPI0->MTC = 4; SPI0->BCC = 4; SPI0->TXD = 0x03 | util_rev(addr); SPI0->TCR |= SPI_TCR_XCH; while (SPI0->FSR & 0xff) < 4); read8((uint32_t)&SPI0->RXD); read8((uint32_t)&SPI0->RXD); read8((uint32_t)&SPI0->RXD); read8((uint32_t)&SPI0->RXD); SPI0->MBC = count; SPI0->MTC = 0; SPI0->BCC = 0; SPI0->TCR |= SPI_TCR_XCH; while (count > 0) { if((SPI0->FSR & 0xFF) > 0) { *p++ = read8((uint32_t)&SPI0->RXD); count -= 1; } } sys_spi_deselect(); }
我尝试后汇报结论
离线
#16 2020-06-04 10:58:47 分享评论
- chenshengwei
- 会员
- 注册时间: 2020-06-04
- 已发帖子: 7
- 积分: 7
Re: f1c100s spi不能使用burst模式???
这个可以通过DMA加快速度吗?
离线
#17 2020-06-04 12:50:18 分享评论
- armstrong
- 会员
- 注册时间: 2019-04-10
- 已发帖子: 295
- 积分: 189.5
Re: f1c100s spi不能使用burst模式???
chenshengwei wrote:
这个可以通过DMA加快速度吗?
能减少传输的空隙时间,从而加快加载速度。
离线
楼主 #18 2020-06-08 17:07:19 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
Re: f1c100s spi不能使用burst模式???
myxiaonia wrote:
我尝试后汇报结论
还是不行,真的是见鬼了。。。为什么uboot引导的就可以呢,spl引导的就是不行
void sys_spi_flash_read(int addr, void* buf, int count)
{
uint8_t *p = (uint8_t *)buf;
sys_spi_select();
SPI0->MBC = 4;
SPI0->MTC = 4;
SPI0->BCC = 4;
SPI0->TXD = 0x03 | util_rev(addr);
SPI0->TCR |= SPI_TCR_XCH;
while (SPI0->FSR & 0xff) < 4);
read8((uint32_t)&SPI0->RXD);
read8((uint32_t)&SPI0->RXD);
read8((uint32_t)&SPI0->RXD);
read8((uint32_t)&SPI0->RXD);
SPI0->MBC = count;
SPI0->MTC = 0;
SPI0->BCC = 0;
SPI0->TCR |= SPI_TCR_XCH;
while (count > 0) {
if((SPI0->FSR & 0xFF) > 0)
{
*p++ = read8((uint32_t)&SPI0->RXD);
count -= 1;
}
}
sys_spi_deselect();
}离线
楼主 #19 2020-06-10 08:47:10 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
Re: f1c100s spi不能使用burst模式???
很遗憾,将flash复制这段代码放到dram运行,也是一样的问题,spi没有工作
毫无疑问,uboot一定是做了一些与spl不同的工作
最近编辑记录 myxiaonia (2020-06-10 08:47:41)
离线
楼主 #20 2020-06-12 13:06:00 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
Re: f1c100s spi不能使用burst模式???
不再纠结这个问题了,本身这个spi速度读取1m字节也才200ms左右,根本不是瓶颈
离线
东莞哇酷科技有限公司开发