楼主 #1 2020-09-21 18:50:58 分享评论
- henman
- 会员
- 注册时间: 2020-09-10
- 已发帖子: 23
- 积分: 8
有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
我做了个频繁浮点的运算,代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <malloc.h>
#include <time.h>
#include <string.h>
int main(int argc, char* argv[])
{
//ok
//double x=2, z=2;
//int a=1, b=3;
//while(z>1e-15)
//{
// z = z*a/b;
// x += z;
// a++;
// b+=2;
//}
//printf("x %.13f\n", x);
clock_t ttBegin = clock();
int i;
int DISPCNT;
if (argc < 2)
{
DISPCNT = 10000;
}
else
{
DISPCNT = atoi(argv[1]);
}
printf("DISPCNT %d\n", DISPCNT);
int ARRSIZE = DISPCNT + 100;
char* x = (char*)malloc(ARRSIZE);
char* z = (char*)malloc(ARRSIZE);
//const int ARRSIZE=10100, DISPCNT=10000; //定义数组大小,显示位数
//char x[ARRSIZE], z[ARRSIZE]; //x[0] x[1] . x[2] x[3] x[4] .... x[ARRSIZE-1]
int a=1, b=3, c, d, Run=1, Cnt=0;
memset(x,0,ARRSIZE);
memset(z,0,ARRSIZE);
x[1] = 2;
z[1] = 2;
clock_t ttLastPrint = 0;
while(Run && (++Cnt<200000000))
{
clock_t ttCurr = clock();
#if __linux__ == 1
if (ttCurr - ttLastPrint > 1000000)
#else
if (ttCurr - ttLastPrint > 1000)
#endif
{
printf("Cnt %d\n", Cnt);
ttLastPrint = ttCurr;
}
//z*=a;
d = 0;
for(i=ARRSIZE-1; i>0; i--)
{
c = z[i]*a + d;
z[i] = c % 10;
d = c / 10;
}
//z/=b;
d = 0;
for(i=0; i<ARRSIZE; i++)
{
c = z[i]+d*10;
z[i] = c / b;
d = c % b;
}
//x+=z;
Run = 0;
for(i=ARRSIZE-1; i>0; i--)
{
c = x[i] + z[i];
x[i] = c%10;
x[i-1] += c/10;
Run |= z[i];
}
a++;
b+=2;
}
clock_t ttEnd = clock();
clock_t ttTotal = ttEnd - ttBegin;
#if __linux__ == 1
printf("%lu.%03lu秒\n", ttTotal / 1000000, (ttTotal % 1000000) / 1000);
#else
printf("%lu.%03lu秒\n", ttTotal / 1000, ttTotal % 1000);
#endif
char s[4 * 1024];
memset(s, 0, sizeof(s));
sprintf(s + strlen(s), "计算了 %d 次\r\n", Cnt);
//sprintf(s + strlen(s), "Pi=%d%d.\r\n", x[0], x[1]);
//for(i=0; i<DISPCNT; i++)
//{
// if(i && ((i%100)==0))
// {
// sprintf(s + strlen(s), "\r\n");
// }
// sprintf(s + strlen(s), "%d", (int)x[i+2]);
//}
//printf("%s\n", s);
return 0;
}结论如下:
虚拟机:x86,2.6G
gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/i686-linux-gnu/4.8/lto-wrapper
Target: i686-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 4.8.4-2ubuntu1~14.04.4' --with-bugurl=file:///usr/share/doc/gcc-4.8/README.Bugs --enable-languages=c,c++,java,go,d,fortran,objc,obj-c++ --prefix=/usr --program-suffix=-4.8 --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --with-gxx-include-dir=/usr/include/c++/4.8 --libdir=/usr/lib --enable-nls --with-sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --enable-gnu-unique-object --disable-libmudflap --enable-plugin --with-system-zlib --disable-browser-plugin --enable-java-awt=gtk --enable-gtk-cairo --with-java-home=/usr/lib/jvm/java-1.5.0-gcj-4.8-i386/jre --enable-java-home --with-jvm-root-dir=/usr/lib/jvm/java-1.5.0-gcj-4.8-i386 --with-jvm-jar-dir=/usr/lib/jvm-exports/java-1.5.0-gcj-4.8-i386 --with-arch-directory=i386 --with-ecj-jar=/usr/share/java/eclipse-ecj.jar --enable-objc-gc --enable-targets=all --enable-multiarch --disable-werror --with-arch-32=i686 --with-multilib-list=m32,m64,mx32 --with-tune=generic --enable-checking=release --build=i686-linux-gnu --host=i686-linux-gnu --target=i686-linux-gnu
Thread model: posix
gcc version 4.8.4 (Ubuntu 4.8.4-2ubuntu1~14.04.4)
gcc main.c
DISPCNT 5000
Cnt 6735
Cnt 13493
2.496秒
gcc -O2 main.c
DISPCNT 5000
Cnt 12608
1.331秒rts3905n,mips,600M
rsdk-linux-gcc -v
Using built-in specs.
COLLECT_GCC=/root/sdb1/rts3903_sdk_v3.2/toolchain/rsdk-6.4.1-5281-EL-4.9-u1.0-m32fut-190408p1/bin/mips-linux-uclibc-xgcc
COLLECT_LTO_WRAPPER=/root/sdb1/rts3903_sdk_v3.2/toolchain/rsdk-6.4.1-5281-EL-4.9-u1.0-m32fut-190408p1/bin/../libexec/gcc/mips-linux-uclibc/6.4.1/lto-wrapper
Target: mips-linux-uclibc
Configured with: Realtek SDK Builder release 5
Thread model: posix
gcc version 6.4.1 20180425 (Realtek RSDK-6.4.1 Build 3058)
rsdk-linux-gcc main.c
DISPCNT 5000
Cnt 701
Cnt 1393
Cnt 2092
Cnt 2782
Cnt 3476
Cnt 4169
Cnt 4865
Cnt 5557
Cnt 6253
Cnt 6954
Cnt 7656
Cnt 8354
Cnt 9062
Cnt 9771
Cnt 10481
Cnt 11189
Cnt 11901
Cnt 12617
Cnt 13328
Cnt 14048
Cnt 14770
Cnt 15492
Cnt 16222
24.210秒
rsdk-linux-gcc -O2 main.c
DISPCNT 5000
Cnt 1710
Cnt 3390
Cnt 5092
Cnt 6786
Cnt 8498
Cnt 10236
Cnt 11968
Cnt 13736
Cnt 15500
9.880秒v3s,cortex-a7,1.2G,带硬浮点fpv4-sp-d16
arm-linux-gnueabihf-gcc -v
使用内建 specs。
COLLECT_GCC=arm-linux-gnueabihf-gcc
COLLECT_LTO_WRAPPER=/opt/gcc-linaro-6.3.1-2017.05-x86_64_arm-linux-gnueabihf/bin/../libexec/gcc/arm-linux-gnueabihf/6.3.1/lto-wrapper
目标:arm-linux-gnueabihf
配置为:'/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/snapshots/gcc.git~linaro-6.3-2017.05/configure' SHELL=/bin/bash --with-mpc=/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/_build/builds/destdir/x86_64-unknown-linux-gnu --with-mpfr=/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/_build/builds/destdir/x86_64-unknown-linux-gnu --with-gmp=/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/_build/builds/destdir/x86_64-unknown-linux-gnu --with-gnu-as --with-gnu-ld --disable-libmudflap --enable-lto --enable-shared --without-included-gettext --enable-nls --disable-sjlj-exceptions --enable-gnu-unique-object --enable-linker-build-id --disable-libstdcxx-pch --enable-c99 --enable-clocale=gnu --enable-libstdcxx-debug --enable-long-long --with-cloog=no --with-ppl=no --with-isl=no --disable-multilib --with-float=hard --with-fpu=vfpv3-d16 --with-mode=thumb --with-tune=cortex-a9 --with-arch=armv7-a --enable-threads=posix --enable-multiarch --enable-libstdcxx-time=yes --enable-gnu-indirect-function --with-build-sysroot=/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/_build/sysroots/arm-linux-gnueabihf --with-sysroot=/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/_build/builds/destdir/x86_64-unknown-linux-gnu/arm-linux-gnueabihf/libc --enable-checking=release --disable-bootstrap --enable-languages=c,c++,fortran,lto --build=x86_64-unknown-linux-gnu --host=x86_64-unknown-linux-gnu --target=arm-linux-gnueabihf --prefix=/home/tcwg-buildslave/workspace/tcwg-make-release/builder_arch/amd64/label/tcwg-x86_64-build/target/arm-linux-gnueabihf/_build/builds/destdir/x86_64-unknown-linux-gnu
线程模型:posix
gcc 版本 6.3.1 20170404 (Linaro GCC 6.3-2017.05)
arm-linux-gnueabihf-gcc -mcpu=cortex-a7 -mtune=cortex-a7 -mfpu=fpv4-sp-d16 -mfloat-abi=hard -O2 main.c
DISPCNT 5000
Cnt 1698
Cnt 3410
Cnt 5127
Cnt 6852
Cnt 8581
Cnt 10310
Cnt 12054
Cnt 13804
Cnt 15560
9.776秒
arm-linux-gnueabihf-gcc -O2 main.c
DISPCNT 5000
Cnt 593
Cnt 1197
Cnt 1810
Cnt 2434
Cnt 3068
Cnt 3707
Cnt 4359
Cnt 5031
Cnt 5711
Cnt 6402
Cnt 7104
Cnt 7816
Cnt 8550
Cnt 9308
Cnt 10081
Cnt 10871
Cnt 11680
Cnt 12512
Cnt 13367
Cnt 14247
Cnt 15154
Cnt 16094
22.868秒
arm-linux-gnueabi-gcc -static main.c //由于系统库不一致,所以加了-static参数
DISPCNT 5000
Cnt 195
Cnt 389
Cnt 584
Cnt 779
Cnt 974
Cnt 1170
Cnt 1366
^C //太慢了,不等了
arm-linux-gnueabi-gcc -static -O2 main.c //由于系统库不一致,所以加了-static参数
DISPCNT 5000
Cnt 595
Cnt 1199
Cnt 1811
Cnt 2433
Cnt 3067
Cnt 3703
Cnt 4352
Cnt 5020
Cnt 5696
Cnt 6380
Cnt 7075
Cnt 7781
Cnt 8506
Cnt 9255
Cnt 10016
Cnt 10792
Cnt 11588
Cnt 12401
Cnt 13233
Cnt 14086
Cnt 14964
Cnt 15872
Cnt 16810
23.350秒
arm-linux-gnueabi-gcc -static -mcpu=cortex-a7 -mtune=cortex-a7 -mfpu=fpv4-sp-d16 -mfloat-abi=soft -O2 main.c
DISPCNT 5000
Cnt 1612
Cnt 3235
Cnt 4863
Cnt 6498
Cnt 8135
Cnt 9781
Cnt 11432
Cnt 13087
Cnt 14748
Cnt 16414
10.410秒离线
楼主 #2 2020-09-21 18:52:16 分享评论
- henman
- 会员
- 注册时间: 2020-09-10
- 已发帖子: 23
- 积分: 8
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
这个1.2G的主频是不是太虚了。。。还是说我哪里没搞好?
离线
楼主 #3 2020-09-21 19:09:42 分享评论
- henman
- 会员
- 注册时间: 2020-09-10
- 已发帖子: 23
- 积分: 8
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
再贴两个海思的。
hi3518ev200,arm926,600m
arm-hisiv300-linux-gcc -v
Using built-in specs.
COLLECT_GCC=arm-hisiv300-linux-gcc
COLLECT_LTO_WRAPPER=/opt/hisi-linux/x86-arm/arm-hisiv300-linux/bin/../libexec/gcc/arm-hisiv300-linux-uclibcgnueabi/4.8.3/lto-wrapper
Target: arm-hisiv300-linux-uclibcgnueabi
Configured with: '../gcc~linaro-4.8-2013.12/configure' --host=i386-redhat-linux --build=i386-redhat-linux --target=arm-hisiv300-linux-uclibcgnueabi --prefix=/home/sying/wucaiyuan_toolchain/v300/uclibc_gcc4.8_linaro_toolchain_optimized/install/arm-hisiv300-linux --enable-threads --disable-libmudflap --disable-libssp --disable-libstdcxx-pch --with-arch=armv5te --with-gnu-as --with-gnu-ld --enable-languages=c,c++ --enable-shared --enable-lto --enable-symvers=gnu --enable-__cxa_atexit --enable-nls --enable-clocale=gnu --enable-extra-hisi-multilibs --with-sysroot=/home/sying/wucaiyuan_toolchain/v300/uclibc_gcc4.8_linaro_toolchain_optimized/install/arm-hisiv300-linux/target --with-build-sysroot=/home/sying/wucaiyuan_toolchain/v300/uclibc_gcc4.8_linaro_toolchain_optimized/install/arm-hisiv300-linux/target --with-gmp=/home/sying/wucaiyuan_toolchain/v300/uclibc_gcc4.8_linaro_toolchain_optimized/install/host_lib --with-mpfr=/home/sying/wucaiyuan_toolchain/v300/uclibc_gcc4.8_linaro_toolchain_optimized/install/host_lib --with-mpc=/home/sying/wucaiyuan_toolchain/v300/uclibc_gcc4.8_linaro_toolchain_optimized/install/host_lib --with-ppl=/home/sying/wucaiyuan_toolchain/v300/uclibc_gcc4.8_linaro_toolchain_optimized/install/host_lib --with-cloog=/home/sying/wucaiyuan_toolchain/v300/uclibc_gcc4.8_linaro_toolchain_optimized/install/host_lib --with-libelf=/home/sying/wucaiyuan_toolchain/v300/uclibc_gcc4.8_linaro_toolchain_optimized/install/host_lib --enable-libgomp --disable-libitm --enable-poison-system-directories --with-libelf=/home/sying/wucaiyuan_toolchain/v300/uclibc_gcc4.8_linaro_toolchain_optimized/install/host_lib --with-pkgversion=Hisilicon_v300 --with-bugurl=http://www.hisilicon.com/cn/service/claim.html
Thread model: posix
gcc version 4.8.3 20131202 (prerelease) (Hisilicon_v300)
arm-hisiv300-linux-gcc main.c
DISPCNT 5000
Cnt 369
Cnt 739
...
Cnt 16483
Cnt 16903
43.490秒
arm-hisiv300-linux-gcc -O2 main.c
DISPCNT 5000
Cnt 667
Cnt 1343
...
Cnt 15760
Cnt 16626
22.560秒hi3516ev200,cortex-a7,900m,浮点运算能力未知
arm-himix100-linux-gcc -v
Using built-in specs.
COLLECT_GCC=arm-himix100-linux-gcc
COLLECT_LTO_WRAPPER=/opt/hisi-linux/x86-arm/arm-himix100-linux/host_bin/../libexec/gcc/arm-linux-uclibceabi/6.3.0/lto-wrapper
Target: arm-linux-uclibceabi
Configured with: /home/sying/SDK_CPU_UNIFIED/build/script/arm-himix100-linux/arm_himix100_build_dir/src/gcc-6.3.0/configure --host=i386-redhat-linux --build=i386-redhat-linux --target=arm-linux-uclibceabi --prefix=/home/sying/SDK_CPU_UNIFIED/build/script/arm-himix100-linux/arm_himix100_build_dir/install --enable-threads --disable-libmudflap --disable-libssp --disable-libstdcxx-pch --with-gnu-as --with-gnu-ld --enable-languages=c,c++ --enable-shared --enable-lto --enable-symvers=gnu --enable-__cxa_atexit --disable-libatomic --disable-nls --enable-clocale=gnu --enable-extra-hisi-multilibs --with-sysroot=/home/sying/SDK_CPU_UNIFIED/build/script/arm-himix100-linux/arm_himix100_build_dir/install/target --with-build-sysroot=/home/sying/SDK_CPU_UNIFIED/build/script/arm-himix100-linux/arm_himix100_build_dir/install/target --with-gmp=/home/sying/SDK_CPU_UNIFIED/build/script/arm-himix100-linux/arm_himix100_build_dir/obj/host-libs/usr --with-mpfr=/home/sying/SDK_CPU_UNIFIED/build/script/arm-himix100-linux/arm_himix100_build_dir/obj/host-libs/usr --with-mpc=/home/sying/SDK_CPU_UNIFIED/build/script/arm-himix100-linux/arm_himix100_build_dir/obj/host-libs/usr --disable-libgomp --disable-libquadmath --disable-fixed-point --disable-libsanitizer --disable-libitm --enable-poison-system-directories --with-pkgversion='HC&C V100R002C00B032_20190114'
Thread model: posix
gcc version 6.3.0 (HC&C V100R002C00B032_20190114)
arm-himix100-linux-gcc main.c
DISPCNT 5000
Cnt 656
Cnt 1316
...
Cnt 15596
Cnt 16374
23.940秒
arm-himix100-linux-gcc -O2 main.c
DISPCNT 5000
Cnt 1435
Cnt 2921
...
Cnt 13228
Cnt 15279
9.850秒
arm-himix100-linux-gcc -mcpu=cortex-a7 -mfloat-abi=softfp -mfpu=neon-vfpv4 -O2 main.c
DISPCNT 5000
Cnt 3806
Cnt 7654
Cnt 11535
Cnt 15447
4.420秒离线
#4 2020-09-21 19:46:31 分享评论
- 微凉VeiLiang
- 会员

- 所在地: 深圳
- 注册时间: 2018-10-28
- 已发帖子: 649
- 积分: 539
- 个人网站
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
arm-linux-gnueabi-gcc -static -mcpu=cortex-a7 -mtune=cortex-a7 -mfpu=fpv4-sp-d16 -mfloat-abi=soft这里有问题。应该是-mfloat-abi=hard
离线
#5 2020-09-21 19:48:33 分享评论
- 微凉VeiLiang
- 会员
- 所在地: 深圳
- 注册时间: 2018-10-28
- 已发帖子: 649
- 积分: 539
- 个人网站
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
还有就是单拿浮点来运算评估不出cpu运算能力。
离线
#6 2020-09-21 22:13:35 分享评论
- 阿黄
- 会员
- 注册时间: 2018-10-03
- 已发帖子: 299
- 积分: 134
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
关注
离线
#7 2020-09-21 22:17:56 分享评论
- tpu
- 会员
- 注册时间: 2020-06-15
- 已发帖子: 40
- 积分: 42.5
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
微凉VeiLiang wrote:
arm-linux-gnueabi-gcc -static -mcpu=cortex-a7 -mtune=cortex-a7 -mfpu=fpv4-sp-d16 -mfloat-abi=soft这里有问题。应该是-mfloat-abi=hard
float-abi参数只控制如何传参数等,对性能基本上没影响的。
离线
楼主 #8 2020-09-22 09:33:16 分享评论
- henman
- 会员
- 注册时间: 2020-09-10
- 已发帖子: 23
- 积分: 8
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
和一群小伙伴探讨了挺久的,又得到了一个工具,量化flops。
/*
* Linpack 100x100 Benchmark In C/C++ For PCs
*
********************************************************************
*
* Original Source from NETLIB
*
* Translated to C by Bonnie Toy 5/88 (modified on 2/25/94 to fix
* a problem with daxpy for unequal increments or equal increments
* not equal to 1. Jack Dongarra)
*
* To obtain rolled source BLAS, add -DROLL to the command lines.
* To obtain unrolled source BLAS, add -DUNROLL to the command lines.
*
* You must specify one of -DSP or -DDP to compile correctly.
*
* You must specify one of -DROLL or -DUNROLL to compile correctly.
*
********************************************************************
*
* Changes in this version
*
* 1. Function prototypes are declared and function headers have
* embedded parameter types to produce code for C and C++
*
* 2. Arrays aa and a are declared as [200*200] and [200*201] to
* allow compilation with prototypes.
*
* 3. Function second changed (compiler dependent).
*
* 4. Timing method changed due to inaccuracy of PC clock (see below).
*
* 5. Additional date function included (compiler dependent).
*
* 6. Additional code used as a standard for a series of benchmarks:-
* Automatic run time calibration rather than fixed parameters
* Initial calibration with display to show linearity
* Results displayed at reasonable rate for viewing (5 seconds)
* Facilities for typing in details of system used etc.
* Compiler details in code in case .exe files used elsewhere
* Results appended to a text file (Linpack.txt)
*
* Roy Longbottom 101323.2241@compuserve.com 14 September 1996
*
************************************************************************
*
* Timing
*
* The PC timer is updated at about 18 times per second or resolution of
* 0.05 to 0.06 seconds which is similar to the time taken by the main
* time consuming function dgefa on a 100 MHz Pentium. Thus there is no
* point in running the dgefa/dges1 combination three times as in the
* original version. Main timing for the latter, in the loop run NTIMES,
* executes matgen/dgefa, summing the time taken by matgen within the
* loop for later deduction from the total time. On a modern PC this sum
* can be based on a random selection of 0 or 0.05/0.06. This version
* executes the single pass once and the main timing loop five times,
* calculating the matgen overhead separately.
*
*************************************************************************
*
* Example of Output
*
* Rolled Double Precision Linpack Benchmark - PC Version in 'C/C++'
*
* Compiler Watcom C/C++ 10.5 Win 386
* Optimisation -zp4 -otexan -fp5 -5r -dDP -dROLL
*
*
* norm resid resid machep x[0]-1 x[n-1]-1
* 0.4 7.41628980e-014 1.00000000e-015 -1.49880108e-014 -1.89848137e-014
*
*
* Times are reported for matrices of order 100
* 1 pass times for array with leading dimension of 201
*
* dgefa dgesl total Mflops unit ratio
* 0.06000 0.00000 0.06000 11.44 0.1748 1.0714
*
*
* Calculating matgen overhead
*
* 10 times 0.11 seconds
* 20 times 0.22 seconds
* 40 times 0.44 seconds
* 80 times 0.87 seconds
* 160 times 1.76 seconds
* 320 times 3.52 seconds
* 640 times 7.03 seconds
*
* Overhead for 1 matgen 0.01098 seconds
*
*
* Calculating matgen/dgefa passes for 5 seconds
*
* 10 times 0.71 seconds
* 20 times 1.38 seconds
* 40 times 2.80 seconds
* 80 times 5.66 seconds
*
* Passes used 70
*
* This is followed by output of the normal data for dgefa, dges1,
* total, Mflops, unit and ratio with five sets of results for each.
*
************************************************************************
*
* Example from output file Linpack.txt
*
* LINPACK BENCHMARK FOR PCs 'C/C++' n @ 100
*
* Month run 9/1996
* PC model Escom
* CPU Pentium
* Clock MHz 100
* Cache 256K
* Options Neptune chipset
* OS/DOS Windows 95
* Compiler Watcom C/C++ 10.5 Win 386
* OptLevel -zp4 -otexan -fp5 -5r -dDP -dROLL
* Run by Roy Longbottom
* From UK
* Mail 101323.2241@compuserve.com
*
* Rolling Rolled
* Precision Double
* norm. resid 0.4
* resid 7.41628980e-014
* machep 1.00000000e-015 (8.88178420e-016 NON OPT)
* x[0]-1 -1.49880108e-014
* x[n-1]-1 -1.89848137e-014
* matgen 1 seconds 0.01051
* matgen 2 seconds 0.01050
* Repetitions 70
* Leading dimension 201
* dgefa dgesl total Mflops
* 1 pass seconds 0.06000 0.00000 0.06000
* Repeat seconds 0.06092 0.00157 0.06249 10.99
* Repeat seconds 0.06077 0.00157 0.06234 11.01
* Repeat seconds 0.06092 0.00157 0.06249 10.99
* Repeat seconds 0.06092 0.00157 0.06249 10.99
* Repeat seconds 0.06092 0.00157 0.06249 10.99
* Average 10.99
* Leading dimension 200
* Repeat seconds 0.05936 0.00157 0.06093 11.27
* Repeat seconds 0.05936 0.00157 0.06093 11.27
* Repeat seconds 0.05864 0.00157 0.06021 11.40
* Repeat seconds 0.05936 0.00157 0.06093 11.27
* Repeat seconds 0.05864 0.00157 0.06021 11.40
* Average 11.32
*
************************************************************************
*
* Examples of Results
*
* Precompiled codes were produced via a Watcom C/C++ 10.5 compiler.
* Versions are available for DOS, Windows 3/95 and NT/Win 95. Both
* non-optimised and optimised programs are available. The latter has
* options as in the above example. Although these options can place
* functions in-line, in this case, daxpy is not in-lined. Optimisation
* reduces 18 instructions in the loop in this function to the following:
*
* L85 fld st(0)
* fmul qword ptr [edx]
* add eax,00000008H
* add edx,00000008H
* fadd qword ptr -8H[eax]
* inc ebx
* fstp qword ptr -8H[eax]
* cmp ebx,esi
* jl L85
*
* Results produced are not consistent between runs but produce similar
* speeds when executing at a particular dimension (see above). An example
* of other results is 11.4/10.5 Mflops. Most typical double precision
* rolled results are:
*
* Opt No Opt Version/
* MHz Cache Mflops Mflops Make/Options Via
*
* AM80386DX 40 128K 0.53 0.36 Clone Win/W95
* 80486DX2 66 128K 2.5 1.9 Escom SIS chipset Win/W95
* 80486DX2 66 128K 2.3 1.9 Escom SIS chipset NT/W95
* 80486DX2 66 128K 2.8 2.0 Escom SIS chipset Dos/Dos
* Pentium 100 256K 11 4.2 Escom Neptune chipset Win/W95
* Pentium 100 256K 11 5.5 Escom Neptune chipset NT/W95
* Pentium 100 256K 12 4.4 Escom Neptune chipset Dos/Dos
* Pentium Pro 200 256K 48 19 Dell XPS Pro200n NT/NT
*
* The results are as produced when compiled as Linpack.cpp. Compiling as
* Linpack.c gives similar speeds but the code is a little different.
*
***************************************************************************
*/
#define ROLL
#define SP
#ifdef SP
#define REAL float
#define ZERO 0.0
#define ONE 1.0
#define PREC "Single "
#endif
#ifdef DP
#define REAL double
#define ZERO 0.0e0
#define ONE 1.0e0
#define PREC "Double "
#endif
#ifdef ROLL
#define ROLLING "Rolled "
#endif
#ifdef UNROLL
#define ROLLING "Unrolled "
#endif
#define NTIMES 10
#include <stdio.h>
#include <math.h>
//#include "conio.h"
#include <stdio.h>
#include <stdlib.h>
static REAL atime[9][15];
static int this_month;
static int this_year;
void print_time (int row);
void matgen (REAL a[], int lda, int n, REAL b[], REAL *norma);
void dgefa (REAL a[], int lda, int n, int ipvt[], int *info);
void dgesl (REAL a[],int lda,int n,int ipvt[],REAL b[],int job);
void dmxpy (int n1, REAL y[], int n2, int ldm, REAL x[], REAL m[]);
void daxpy (int n, REAL da, REAL dx[], int incx, REAL dy[], int incy);
REAL epslon (REAL x);
int idamax (int n, REAL dx[], int incx);
void dscal (int n, REAL da, REAL dx[], int incx);
REAL ddot (int n, REAL dx[], int incx, REAL dy[], int incy);
/* TIME TIME TIME TIME TIME TIME TIME TIME TIME TIME TIME TIME TIME */
#if 1
#include <time.h> /* for following time functions only */
REAL second()
{
REAL secs;
clock_t Time;
Time = clock();
secs = (REAL)Time / (REAL)CLOCKS_PER_SEC;
return secs ;
}
#endif
/* DATE DATE DATE DATE DATE DATE DATE DATE DATE DATE DATE DATE DATE */
#if 1
#include <time.h> /* for following date functions only */
void what_date()
{
time_t *t,timer;
struct tm *tm;
timer = time(t);
tm = localtime(&timer);
this_month = tm->tm_mon;
this_year = tm->tm_year;
return;
}
#endif
main ()
{
static REAL aa[200*200],a[200*201],b[200],x[200];
REAL cray,ops,total,norma,normx;
REAL resid,residn,eps,t1,tm2,epsn,x1,x2;
REAL mflops;
static int ipvt[200],n,i,j,ntimes,info,lda,ldaa;
int Endit, pass, loop;
REAL overhead1, overhead2, time1, time2;
FILE *outfile;
char *compiler, *options, general[9][80] = {" "};
outfile = fopen("Linpack.txt","a+");
if (outfile == NULL)
{
printf ("Cannot open results file \n\n");
printf("Press any key\n");
Endit = getchar();
exit (0);
}
/************************************************************************
* Enter details of compiler and options used *
************************************************************************/
/*----------------- --------- --------- ---------*/
compiler = "INSERT COMPILER NAME HERE";
options = "INSERT OPTIMISATION OPTIONS HERE";
/* Include -dDP or -dSP and -dROLL or -dUNROLL */
lda = 201;
ldaa = 200;
cray = .056;
n = 100;
fprintf(stdout,ROLLING);fprintf(stdout,PREC);
fprintf(stdout,"Precision Linpack Benchmark - PC Version in 'C/C++'\n\n");
fprintf(stdout,"Compiler %s\n",compiler);
fprintf(stdout,"Optimisation %s\n\n",options);
ops = (2.0e0*(n*n*n))/3.0 + 2.0*(n*n);
matgen(a,lda,n,b,&norma);
t1 = second();
dgefa(a,lda,n,ipvt,&info);
atime[0][0] = second() - t1;
t1 = second();
dgesl(a,lda,n,ipvt,b,0);
atime[1][0] = second() - t1;
total = atime[0][0] + atime[1][0];
/* compute a residual to verify results. */
for (i = 0; i < n; i++) {
x[i] = b[i];
}
matgen(a,lda,n,b,&norma);
for (i = 0; i < n; i++) {
b[i] = -b[i];
}
dmxpy(n,b,n,lda,x,a);
resid = 0.0;
normx = 0.0;
for (i = 0; i < n; i++) {
resid = (resid > fabs((double)b[i]))
? resid : fabs((double)b[i]);
normx = (normx > fabs((double)x[i]))
? normx : fabs((double)x[i]);
}
eps = epslon(ONE);
residn = resid/( n*norma*normx*eps );
epsn = eps;
x1 = x[0] - 1;
x2 = x[n-1] - 1;
printf("norm resid resid machep");
printf(" x[0]-1 x[n-1]-1\n");
printf("%6.1f %17.8e%17.8e%17.8e%17.8e\n\n",
(double)residn, (double)resid, (double)epsn,
(double)x1, (double)x2);
fprintf(stderr,"Times are reported for matrices of order %5d\n",n);
fprintf(stderr,"1 pass times for array with leading dimension of%5d\n\n",lda);
fprintf(stderr," dgefa dgesl total Mflops unit");
fprintf(stderr," ratio\n");
atime[2][0] = total;
if (total > 0.0)
{
atime[3][0] = ops/(1.0e6*total);
atime[4][0] = 2.0/atime[3][0];
}
else
{
atime[3][0] = 0.0;
atime[4][0] = 0.0;
}
atime[5][0] = total/cray;
print_time(0);
/************************************************************************
* Calculate overhead of executing matgen procedure *
************************************************************************/
fprintf (stderr,"\nCalculating matgen overhead\n");
pass = -20;
loop = NTIMES;
do
{
time1 = second();
pass = pass + 1;
for ( i = 0 ; i < loop ; i++)
{
matgen(a,lda,n,b,&norma);
}
time2 = second();
overhead1 = (time2 - time1);
fprintf (stderr,"%10d times %6.2f seconds\n", loop, overhead1);
if (overhead1 > 5.0)
{
pass = 0;
}
if (pass < 0)
{
if (overhead1 < 0.1)
{
loop = loop * 10;
}
else
{
loop = loop * 2;
}
}
}
while (pass < 0);
overhead1 = overhead1 / (double)loop;
fprintf (stderr,"Overhead for 1 matgen %12.5f seconds\n\n", overhead1);
/************************************************************************
* Calculate matgen/dgefa passes for 5 seconds *
************************************************************************/
fprintf (stderr,"Calculating matgen/dgefa passes for 5 seconds\n");
pass = -20;
ntimes = NTIMES;
do
{
time1 = second();
pass = pass + 1;
for ( i = 0 ; i < ntimes ; i++)
{
matgen(a,lda,n,b,&norma);
dgefa(a,lda,n,ipvt,&info );
}
time2 = second() - time1;
fprintf (stderr,"%10d times %6.2f seconds\n", ntimes, time2);
if (time2 > 5.0)
{
pass = 0;
}
if (pass < 0)
{
if (time2 < 0.1)
{
ntimes = ntimes * 10;
}
else
{
ntimes = ntimes * 2;
}
}
}
while (pass < 0);
ntimes = 5.0 * (double)ntimes / time2;
if (ntimes == 0) ntimes = 1;
fprintf (stderr,"Passes used %10d \n\n", ntimes);
fprintf(stderr,"Times for array with leading dimension of%4d\n\n",lda);
fprintf(stderr," dgefa dgesl total Mflops unit");
fprintf(stderr," ratio\n");
/************************************************************************
* Execute 5 passes *
************************************************************************/
tm2 = ntimes * overhead1;
atime[3][6] = 0;
for (j=1 ; j<6 ; j++)
{
t1 = second();
for (i = 0; i < ntimes; i++)
{
matgen(a,lda,n,b,&norma);
dgefa(a,lda,n,ipvt,&info );
}
atime[0][j] = (second() - t1 - tm2)/ntimes;
t1 = second();
for (i = 0; i < ntimes; i++)
{
dgesl(a,lda,n,ipvt,b,0);
}
atime[1][j] = (second() - t1)/ntimes;
total = atime[0][j] + atime[1][j];
atime[2][j] = total;
atime[3][j] = ops/(1.0e6*total);
atime[4][j] = 2.0/atime[3][j];
atime[5][j] = total/cray;
atime[3][6] = atime[3][6] + atime[3][j];
print_time(j);
}
atime[3][6] = atime[3][6] / 5.0;
fprintf (stderr,"Average %11.2f\n",
(double)atime[3][6]);
fprintf (stderr,"\nCalculating matgen2 overhead\n");
/************************************************************************
* Calculate overhead of executing matgen procedure *
************************************************************************/
time1 = second();
for ( i = 0 ; i < loop ; i++)
{
matgen(aa,ldaa,n,b,&norma);
}
time2 = second();
overhead2 = (time2 - time1);
overhead2 = overhead2 / (double)loop;
fprintf (stderr,"Overhead for 1 matgen %12.5f seconds\n\n", overhead2);
fprintf(stderr,"Times for array with leading dimension of%4d\n\n",ldaa);
fprintf(stderr," dgefa dgesl total Mflops unit");
fprintf(stderr," ratio\n");
/************************************************************************
* Execute 5 passes *
************************************************************************/
tm2 = ntimes * overhead2;
atime[3][12] = 0;
for (j=7 ; j<12 ; j++)
{
t1 = second();
for (i = 0; i < ntimes; i++)
{
matgen(aa,ldaa,n,b,&norma);
dgefa(aa,ldaa,n,ipvt,&info );
}
atime[0][j] = (second() - t1 - tm2)/ntimes;
t1 = second();
for (i = 0; i < ntimes; i++)
{
dgesl(aa,ldaa,n,ipvt,b,0);
}
atime[1][j] = (second() - t1)/ntimes;
total = atime[0][j] + atime[1][j];
atime[2][j] = total;
atime[3][j] = ops/(1.0e6*total);
atime[4][j] = 2.0/atime[3][j];
atime[5][j] = total/cray;
atime[3][12] = atime[3][12] + atime[3][j];
print_time(j);
}
atime[3][12] = atime[3][12] / 5.0;
fprintf (stderr,"Average %11.2f\n",
(double)atime[3][12]);
/************************************************************************
* Use minimum average as overall Mflops rating *
************************************************************************/
mflops = atime[3][6];
if (atime[3][12] < mflops) mflops = atime[3][12];
fprintf(stderr,"\n");
fprintf(stderr,ROLLING);fprintf(stderr,PREC);
fprintf(stderr," Precision %11.2f Mflops \n\n",mflops);
what_date();
/************************************************************************
* Type details of hardware, software etc. *
************************************************************************/
printf ("Enter the following data which will be "
"appended to file Linpack.txt \n\n");
printf ("PC Supplier/model ?\n ");
scanf ("%[^\n]", general[1]);
fflush (stdin);
printf ("CPU ?\n ");
scanf ("%[^\n]", general[2]);
fflush (stdin);
printf ("Clock MHz ?\n ");
scanf ("%[^\n]", general[3]);
fflush (stdin);
printf ("Cache ?\n ");
scanf ("%[^\n]", general[4]);
fflush (stdin);
printf ("Chipset/options ?\n ");
scanf ("%[^\n]", general[5]);
fflush (stdin);
printf ("OS/DOS version ?\n ");
scanf ("%[^\n]", general[6]);
fflush (stdin);
printf ("Your name ?\n ");
scanf ("%[^\n]", general[7]);
fflush (stdin);
printf ("Where from ?\n ");
scanf ("%[^\n]", general[8]);
fflush (stdin);
printf ("Mail address ?\n ");
scanf ("%[^\n]", general[0]);
fflush (stdin);
/************************************************************************
* Add results to output file LLloops.txt *
************************************************************************/
fprintf (outfile, "----------------- ----------------- --------- "
"--------- ---------\n");
fprintf (outfile, "LINPACK BENCHMARK FOR PCs 'C/C++' n @ 100\n\n");
fprintf (outfile, "Month run %d/%d\n", this_month, this_year);
fprintf (outfile, "PC model %s\n", general[1]);
fprintf (outfile, "CPU %s\n", general[2]);
fprintf (outfile, "Clock MHz %s\n", general[3]);
fprintf (outfile, "Cache %s\n", general[4]);
fprintf (outfile, "Options %s\n", general[5]);
fprintf (outfile, "OS/DOS %s\n", general[6]);
fprintf (outfile, "Compiler %s\n", compiler);
fprintf (outfile, "OptLevel %s\n", options);
fprintf (outfile, "Run by %s\n", general[7]);
fprintf (outfile, "From %s\n", general[8]);
fprintf (outfile, "Mail %s\n\n", general[0]);
fprintf(outfile, "Rolling %s\n",ROLLING);
fprintf(outfile, "Precision %s\n",PREC);
fprintf(outfile, "norm. resid %16.1f\n",(double)residn);
fprintf(outfile, "resid %16.8e\n",(double)resid);
fprintf(outfile, "machep %16.8e\n",(double)epsn);
fprintf(outfile, "x[0]-1 %16.8e\n",(double)x1);
fprintf(outfile, "x[n-1]-1 %16.8e\n",(double)x2);
fprintf(outfile, "matgen 1 seconds %16.5f\n",overhead1);
fprintf(outfile, "matgen 2 seconds %16.5f\n",overhead2);
fprintf(outfile, "Repetitions %16d\n",ntimes);
fprintf(outfile, "Leading dimension %16d\n",lda);
fprintf(outfile, " dgefa dgesl "
" total Mflops\n");
fprintf(outfile, "1 pass seconds %16.5f %9.5f %9.5f\n",
atime[0][0], atime[1][0], atime[2][0]);
for (i=1 ; i<6 ; i++)
{
fprintf(outfile, "Repeat seconds %16.5f %9.5f %9.5f %9.2f\n",
atime[0][i], atime[1][i], atime[2][i], atime[3][i]);
}
fprintf(outfile, "Average %46.2f\n",atime[3][6]);
fprintf(outfile, "Leading dimension %16d\n",ldaa);
for (i=7 ; i<12 ; i++)
{
fprintf(outfile, "Repeat seconds %16.5f %9.5f %9.5f %9.2f\n",
atime[0][i], atime[1][i], atime[2][i], atime[3][i]);
}
fprintf(outfile, "Average %46.2f\n\n",atime[3][12]);
fclose (outfile);
printf("\nPress any key\n");
Endit = getchar();
}
/*----------------------*/
void print_time (int row)
{
fprintf(stderr,"%11.5f%11.5f%11.5f%11.2f%11.4f%11.4f\n", (double)atime[0][row],
(double)atime[1][row], (double)atime[2][row], (double)atime[3][row],
(double)atime[4][row], (double)atime[5][row]);
return;
}
/*----------------------*/
void matgen (REAL a[], int lda, int n, REAL b[], REAL *norma)
/* We would like to declare a[][lda], but c does not allow it. In this
function, references to a[i][j] are written a[lda*i+j]. */
{
int init, i, j;
init = 1325;
*norma = 0.0;
for (j = 0; j < n; j++) {
for (i = 0; i < n; i++) {
init = 3125*init % 65536;
a[lda*j+i] = (init - 32768.0)/16384.0;
*norma = (a[lda*j+i] > *norma) ? a[lda*j+i] : *norma;
/* alternative for some compilers
if (fabs(a[lda*j+i]) > *norma) *norma = fabs(a[lda*j+i]);
*/
}
}
for (i = 0; i < n; i++) {
b[i] = 0.0;
}
for (j = 0; j < n; j++) {
for (i = 0; i < n; i++) {
b[i] = b[i] + a[lda*j+i];
}
}
return;
}
/*----------------------*/
void dgefa(REAL a[], int lda, int n, int ipvt[], int *info)
/* We would like to declare a[][lda], but c does not allow it. In this
function, references to a[i][j] are written a[lda*i+j]. */
/*
dgefa factors a double precision matrix by gaussian elimination.
dgefa is usually called by dgeco, but it can be called
directly with a saving in time if rcond is not needed.
(time for dgeco) = (1 + 9/n)*(time for dgefa) .
on entry
a REAL precision[n][lda]
the matrix to be factored.
lda integer
the leading dimension of the array a .
n integer
the order of the matrix a .
on return
a an upper triangular matrix and the multipliers
which were used to obtain it.
the factorization can be written a = l*u where
l is a product of permutation and unit lower
triangular matrices and u is upper triangular.
ipvt integer[n]
an integer vector of pivot indices.
info integer
= 0 normal value.
= k if u[k][k] .eq. 0.0 . this is not an error
condition for this subroutine, but it does
indicate that dgesl or dgedi will divide by zero
if called. use rcond in dgeco for a reliable
indication of singularity.
linpack. this version dated 08/14/78 .
cleve moler, university of new mexico, argonne national lab.
functions
blas daxpy,dscal,idamax
*/
{
/* internal variables */
REAL t;
int j,k,kp1,l,nm1;
/* gaussian elimination with partial pivoting */
*info = 0;
nm1 = n - 1;
if (nm1 >= 0) {
for (k = 0; k < nm1; k++) {
kp1 = k + 1;
/* find l = pivot index */
l = idamax(n-k,&a[lda*k+k],1) + k;
ipvt[k] = l;
/* zero pivot implies this column already
triangularized */
if (a[lda*k+l] != ZERO) {
/* interchange if necessary */
if (l != k) {
t = a[lda*k+l];
a[lda*k+l] = a[lda*k+k];
a[lda*k+k] = t;
}
/* compute multipliers */
t = -ONE/a[lda*k+k];
dscal(n-(k+1),t,&a[lda*k+k+1],1);
/* row elimination with column indexing */
for (j = kp1; j < n; j++) {
t = a[lda*j+l];
if (l != k) {
a[lda*j+l] = a[lda*j+k];
a[lda*j+k] = t;
}
daxpy(n-(k+1),t,&a[lda*k+k+1],1,
&a[lda*j+k+1],1);
}
}
else {
*info = k;
}
}
}
ipvt[n-1] = n-1;
if (a[lda*(n-1)+(n-1)] == ZERO) *info = n-1;
return;
}
/*----------------------*/
void dgesl(REAL a[],int lda,int n,int ipvt[],REAL b[],int job )
/* We would like to declare a[][lda], but c does not allow it. In this
function, references to a[i][j] are written a[lda*i+j]. */
/*
dgesl solves the double precision system
a * x = b or trans(a) * x = b
using the factors computed by dgeco or dgefa.
on entry
a double precision[n][lda]
the output from dgeco or dgefa.
lda integer
the leading dimension of the array a .
n integer
the order of the matrix a .
ipvt integer[n]
the pivot vector from dgeco or dgefa.
b double precision[n]
the right hand side vector.
job integer
= 0 to solve a*x = b ,
= nonzero to solve trans(a)*x = b where
trans(a) is the transpose.
on return
b the solution vector x .
error condition
a division by zero will occur if the input factor contains a
zero on the diagonal. technically this indicates singularity
but it is often caused by improper arguments or improper
setting of lda . it will not occur if the subroutines are
called correctly and if dgeco has set rcond .gt. 0.0
or dgefa has set info .eq. 0 .
to compute inverse(a) * c where c is a matrix
with p columns
dgeco(a,lda,n,ipvt,rcond,z)
if (!rcond is too small){
for (j=0,j<p,j++)
dgesl(a,lda,n,ipvt,c[j][0],0);
}
linpack. this version dated 08/14/78 .
cleve moler, university of new mexico, argonne national lab.
functions
blas daxpy,ddot
*/
{
/* internal variables */
REAL t;
int k,kb,l,nm1;
nm1 = n - 1;
if (job == 0) {
/* job = 0 , solve a * x = b
first solve l*y = b */
if (nm1 >= 1) {
for (k = 0; k < nm1; k++) {
l = ipvt[k];
t = b[l];
if (l != k){
b[l] = b[k];
b[k] = t;
}
daxpy(n-(k+1),t,&a[lda*k+k+1],1,&b[k+1],1 );
}
}
/* now solve u*x = y */
for (kb = 0; kb < n; kb++) {
k = n - (kb + 1);
b[k] = b[k]/a[lda*k+k];
t = -b[k];
daxpy(k,t,&a[lda*k+0],1,&b[0],1 );
}
}
else {
/* job = nonzero, solve trans(a) * x = b
first solve trans(u)*y = b */
for (k = 0; k < n; k++) {
t = ddot(k,&a[lda*k+0],1,&b[0],1);
b[k] = (b[k] - t)/a[lda*k+k];
}
/* now solve trans(l)*x = y */
if (nm1 >= 1) {
for (kb = 1; kb < nm1; kb++) {
k = n - (kb+1);
b[k] = b[k] + ddot(n-(k+1),&a[lda*k+k+1],1,&b[k+1],1);
l = ipvt[k];
if (l != k) {
t = b[l];
b[l] = b[k];
b[k] = t;
}
}
}
}
return;
}
/*----------------------*/
void daxpy(int n, REAL da, REAL dx[], int incx, REAL dy[], int incy)
/*
constant times a vector plus a vector.
jack dongarra, linpack, 3/11/78.
*/
{
int i,ix,iy,m,mp1;
mp1 = 0;
m = 0;
if(n <= 0) return;
if (da == ZERO) return;
if(incx != 1 || incy != 1) {
/* code for unequal increments or equal increments
not equal to 1 */
ix = 0;
iy = 0;
if(incx < 0) ix = (-n+1)*incx;
if(incy < 0)iy = (-n+1)*incy;
for (i = 0;i < n; i++) {
dy[iy] = dy[iy] + da*dx[ix];
ix = ix + incx;
iy = iy + incy;
}
return;
}
/* code for both increments equal to 1 */
#ifdef ROLL
for (i = 0;i < n; i++) {
dy[i] = dy[i] + da*dx[i];
}
#endif
#ifdef UNROLL
m = n % 4;
if ( m != 0) {
for (i = 0; i < m; i++)
dy[i] = dy[i] + da*dx[i];
if (n < 4) return;
}
for (i = m; i < n; i = i + 4) {
dy[i] = dy[i] + da*dx[i];
dy[i+1] = dy[i+1] + da*dx[i+1];
dy[i+2] = dy[i+2] + da*dx[i+2];
dy[i+3] = dy[i+3] + da*dx[i+3];
}
#endif
return;
}
/*----------------------*/
REAL ddot(int n, REAL dx[], int incx, REAL dy[], int incy)
/*
forms the dot product of two vectors.
jack dongarra, linpack, 3/11/78.
*/
{
REAL dtemp;
int i,ix,iy,m,mp1;
mp1 = 0;
m = 0;
dtemp = ZERO;
if(n <= 0) return(ZERO);
if(incx != 1 || incy != 1) {
/* code for unequal increments or equal increments
not equal to 1 */
ix = 0;
iy = 0;
if (incx < 0) ix = (-n+1)*incx;
if (incy < 0) iy = (-n+1)*incy;
for (i = 0;i < n; i++) {
dtemp = dtemp + dx[ix]*dy[iy];
ix = ix + incx;
iy = iy + incy;
}
return(dtemp);
}
/* code for both increments equal to 1 */
#ifdef ROLL
for (i=0;i < n; i++)
dtemp = dtemp + dx[i]*dy[i];
return(dtemp);
#endif
#ifdef UNROLL
m = n % 5;
if (m != 0) {
for (i = 0; i < m; i++)
dtemp = dtemp + dx[i]*dy[i];
if (n < 5) return(dtemp);
}
for (i = m; i < n; i = i + 5) {
dtemp = dtemp + dx[i]*dy[i] +
dx[i+1]*dy[i+1] + dx[i+2]*dy[i+2] +
dx[i+3]*dy[i+3] + dx[i+4]*dy[i+4];
}
return(dtemp);
#endif
}
/*----------------------*/
void dscal(int n, REAL da, REAL dx[], int incx)
/* scales a vector by a constant.
jack dongarra, linpack, 3/11/78.
*/
{
int i,m,mp1,nincx;
mp1 = 0;
m = 0;
if(n <= 0)return;
if(incx != 1) {
/* code for increment not equal to 1 */
nincx = n*incx;
for (i = 0; i < nincx; i = i + incx)
dx[i] = da*dx[i];
return;
}
/* code for increment equal to 1 */
#ifdef ROLL
for (i = 0; i < n; i++)
dx[i] = da*dx[i];
#endif
#ifdef UNROLL
m = n % 5;
if (m != 0) {
for (i = 0; i < m; i++)
dx[i] = da*dx[i];
if (n < 5) return;
}
for (i = m; i < n; i = i + 5){
dx[i] = da*dx[i];
dx[i+1] = da*dx[i+1];
dx[i+2] = da*dx[i+2];
dx[i+3] = da*dx[i+3];
dx[i+4] = da*dx[i+4];
}
#endif
}
/*----------------------*/
int idamax(int n, REAL dx[], int incx)
/*
finds the index of element having max. absolute value.
jack dongarra, linpack, 3/11/78.
*/
{
REAL dmax;
int i, ix, itemp;
if( n < 1 ) return(-1);
if(n ==1 ) return(0);
if(incx != 1) {
/* code for increment not equal to 1 */
ix = 1;
dmax = fabs((double)dx[0]);
ix = ix + incx;
for (i = 1; i < n; i++) {
if(fabs((double)dx[ix]) > dmax) {
itemp = i;
dmax = fabs((double)dx[ix]);
}
ix = ix + incx;
}
}
else {
/* code for increment equal to 1 */
itemp = 0;
dmax = fabs((double)dx[0]);
for (i = 1; i < n; i++) {
if(fabs((double)dx[i]) > dmax) {
itemp = i;
dmax = fabs((double)dx[i]);
}
}
}
return (itemp);
}
/*----------------------*/
REAL epslon (REAL x)
/*
estimate unit roundoff in quantities of size x.
*/
{
REAL a,b,c,eps;
/*
this program should function properly on all systems
satisfying the following two assumptions,
1. the base used in representing dfloating point
numbers is not a power of three.
2. the quantity a in statement 10 is represented to
the accuracy used in dfloating point variables
that are stored in memory.
the statement number 10 and the go to 10 are intended to
force optimizing compilers to generate code satisfying
assumption 2.
under these assumptions, it should be true that,
a is not exactly equal to four-thirds,
b has a zero for its last bit or digit,
c is not exactly equal to one,
eps measures the separation of 1.0 from
the next larger dfloating point number.
the developers of eispack would appreciate being informed
about any systems where these assumptions do not hold.
*****************************************************************
this routine is one of the auxiliary routines used by eispack iii
to avoid machine dependencies.
*****************************************************************
this version dated 4/6/83.
*/
a = 4.0e0/3.0e0;
eps = ZERO;
while (eps == ZERO) {
b = a - ONE;
c = b + b + b;
eps = fabs((double)(c-ONE));
}
return(eps*fabs((double)x));
}
/*----------------------*/
void dmxpy (int n1, REAL y[], int n2, int ldm, REAL x[], REAL m[])
/* We would like to declare m[][ldm], but c does not allow it. In this
function, references to m[i][j] are written m[ldm*i+j]. */
/*
purpose:
multiply matrix m times vector x and add the result to vector y.
parameters:
n1 integer, number of elements in vector y, and number of rows in
matrix m
y double [n1], vector of length n1 to which is added
the product m*x
n2 integer, number of elements in vector x, and number of columns
in matrix m
ldm integer, leading dimension of array m
x double [n2], vector of length n2
m double [ldm][n2], matrix of n1 rows and n2 columns
----------------------------------------------------------------------
*/
{
int j,i,jmin;
/* cleanup odd vector */
j = n2 % 2;
if (j >= 1) {
j = j - 1;
for (i = 0; i < n1; i++)
y[i] = (y[i]) + x[j]*m[ldm*j+i];
}
/* cleanup odd group of two vectors */
j = n2 % 4;
if (j >= 2) {
j = j - 1;
for (i = 0; i < n1; i++)
y[i] = ( (y[i])
+ x[j-1]*m[ldm*(j-1)+i]) + x[j]*m[ldm*j+i];
}
/* cleanup odd group of four vectors */
j = n2 % 8;
if (j >= 4) {
j = j - 1;
for (i = 0; i < n1; i++)
y[i] = ((( (y[i])
+ x[j-3]*m[ldm*(j-3)+i])
+ x[j-2]*m[ldm*(j-2)+i])
+ x[j-1]*m[ldm*(j-1)+i]) + x[j]*m[ldm*j+i];
}
/* cleanup odd group of eight vectors */
j = n2 % 16;
if (j >= 8) {
j = j - 1;
for (i = 0; i < n1; i++)
y[i] = ((((((( (y[i])
+ x[j-7]*m[ldm*(j-7)+i]) + x[j-6]*m[ldm*(j-6)+i])
+ x[j-5]*m[ldm*(j-5)+i]) + x[j-4]*m[ldm*(j-4)+i])
+ x[j-3]*m[ldm*(j-3)+i]) + x[j-2]*m[ldm*(j-2)+i])
+ x[j-1]*m[ldm*(j-1)+i]) + x[j] *m[ldm*j+i];
}
/* main loop - groups of sixteen vectors */
jmin = (n2%16)+16;
for (j = jmin-1; j < n2; j = j + 16) {
for (i = 0; i < n1; i++)
y[i] = ((((((((((((((( (y[i])
+ x[j-15]*m[ldm*(j-15)+i])
+ x[j-14]*m[ldm*(j-14)+i])
+ x[j-13]*m[ldm*(j-13)+i])
+ x[j-12]*m[ldm*(j-12)+i])
+ x[j-11]*m[ldm*(j-11)+i])
+ x[j-10]*m[ldm*(j-10)+i])
+ x[j- 9]*m[ldm*(j- 9)+i])
+ x[j- 8]*m[ldm*(j- 8)+i])
+ x[j- 7]*m[ldm*(j- 7)+i])
+ x[j- 6]*m[ldm*(j- 6)+i])
+ x[j- 5]*m[ldm*(j- 5)+i])
+ x[j- 4]*m[ldm*(j- 4)+i])
+ x[j- 3]*m[ldm*(j- 3)+i])
+ x[j- 2]*m[ldm*(j- 2)+i])
+ x[j- 1]*m[ldm*(j- 1)+i])
+ x[j] *m[ldm*j+i];
}
return;
}离线
楼主 #9 2020-09-22 09:38:06 分享评论
- henman
- 会员
- 注册时间: 2020-09-10
- 已发帖子: 23
- 积分: 8
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
然后侧重的比较了v3s和3516ev200,最后发现,3516ev200的浮点运算性能,真的是v3s的两倍还多一点。两个工具测算出来的比例是一样的。我觉得这个可能它们的fpu是不一样的。3516ev200的参数是-mfpu=neon-vfpv4,而v3s的参数是-mfpu=fpv4-sp-d16。
另外我还试过用海思的gcc编译,在全志上面跑,反正怎么折腾,全志的浮点性能就是起不来。
当然cpu性能不能光看浮点运算,但算法型的程序确实挺依赖浮点运算的。
至于针对主频的测试工具我还没有找到合适的。不知道有没有小伙伴有类似的技术或者代码?
离线
#10 2020-09-22 14:56:25 分享评论
- Blueskull
- 会员
- 注册时间: 2020-02-20
- 已发帖子: 458
- 积分: 444.5
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
A7强制NEON和VFPv4,你试试全志开这个选项能不能跑。
离线
#11 2020-09-22 15:17:33 分享评论
- hameyou
- 会员
- 注册时间: 2018-04-15
- 已发帖子: 262
- 积分: 43.5
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
可能是哪里没设置好吧,如果果真是这样,V3S的1.2G真是太虚了
离线
#12 2020-09-22 15:46:41 分享评论
- kekemuyu
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 857
- 积分: 698
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
https://whycan.com/t_3148.html这是之前sysbench的测试结果,同样是1G频率,v3s竟然比pizerow还要慢,要知道pizerow可是arm11架构的
离线
楼主 #13 2020-09-22 18:22:18 分享评论
- henman
- 会员
- 注册时间: 2020-09-10
- 已发帖子: 23
- 积分: 8
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
又做了一个实验,硬件不变,换了内核以及工具链,这个表现比海思好一些了:D,到底是为什么呢?
环境:
gcc version 4.6.3 20120201 (prerelease) (crosstool-NG linaro-1.13.1-2012.02-20120222 - Linaro GCC 2012.02)
Linux sun8i 3.4.39 #5 Tue Sep 22 18:06:11 CST 2020 armv7l GNU/Linux
arm-linux-gnueabi-gcc -mcpu=cortex-a7 -mtune=cortex-a7 -mfpu=fpv4-sp-d16 -mfloat-abi=soft -static -O2 main.c
结果:
DISPCNT 5000
Cnt 3997
Cnt 8040
Cnt 12118
Cnt 16227
4.210秒
离线
#14 2020-09-23 00:03:01 分享评论
- zzm24
- 会员
- 注册时间: 2018-05-07
- 已发帖子: 131
- 积分: 93
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
我特意测试了一下,主线linux 4.13.16
/opt/gcc-linaro-6.3.1-2017.05-x86_64_arm-linux-gnueabihf/bin/arm-linux-gnueabihf-gcc -mcpu=cortex-a7 -mtune=cortex-a7 -mfpu=fpv4-sp-d16 -mfloat-abi=hard -O3 main.c
./a.out 5000
DISPCNT 5000
Cnt 4303
Cnt 8659
Cnt 13060
3.870秒
怀疑就是 -mfloat-abi=soft的问题,但是gcc-linaro-6.3.1-2017.05-x86_64_arm-linux-gnueabihf无法使用-mfloat-abi=soft,所以无法测试
离线
#15 2020-09-23 10:52:35 分享评论
- kekemuyu
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 857
- 积分: 698
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
树莓派zero的950mhz测试结果,由于pizero的硬浮点是VFPv2,比v3s落后,没有可比性参考一下即可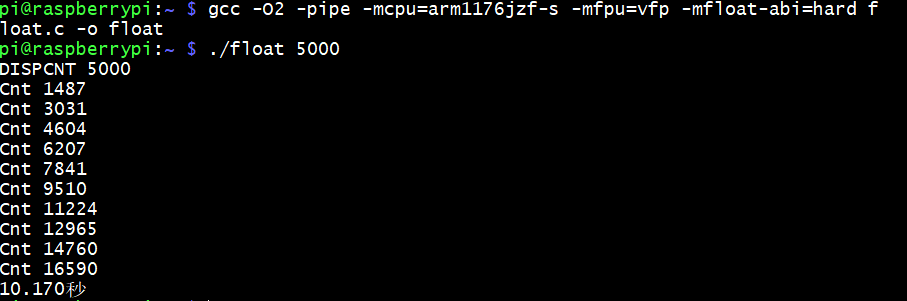
最近编辑记录 kekemuyu (2020-09-23 10:53:08)
离线
#16 2020-09-23 11:04:34 分享评论
- yomkk
- 会员
- 注册时间: 2020-09-23
- 已发帖子: 12
- 积分: 12
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
用手边的A20板子试了下, 频率 1.080GHz, 分别用带浮点和不带浮点两种方式跑了下。
user@M2:~$ gcc float_benchmark.c -static -mcpu=cortex-a7 -mtune=cortex-a7 -mfpu=neon-vfpv4 -mfloat-abi=hard -O2
user@M2:~$ ./a.out 5000
DISPCNT 5000
Cnt 4683
Cnt 9442
Cnt 14255
3.547秒user@M2:~$ gcc float_benchmark.c
user@M2:~$ ./a.out 5000
DISPCNT 5000
Cnt 510
Cnt 1022
Cnt 1538
......
Cnt 15704
Cnt 16280
Cnt 16860
31.143秒最近编辑记录 yomkk (2020-09-23 11:10:44)
离线
#17 2020-09-24 08:34:28 分享评论
- linac
- 会员
- 注册时间: 2019-05-28
- 已发帖子: 12
- 积分: 12
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
rts3905n是什么东东? 有datasheet吗? 难道有FPU?
不然的话,都用浮点库,性能比A7快这么多?
离线
楼主 #18 2020-09-24 18:44:38 分享评论
- henman
- 会员
- 注册时间: 2020-09-10
- 已发帖子: 23
- 积分: 8
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
rts3905n是瑞昱的一款mips,主频600m。原厂说是硬浮点,默认开启,无需填写编译参数。
我现在都搞不懂v3s的性能到底是怎么了。我最近一直在编译3.4版本的内核,反正每次启动新内核我都会做一次测试,性能基本都在Cnt 4000的水平,暂时还摸不到性能下降的规律。
离线
#19 2024-01-30 17:02:22 分享评论
- dsp2000
- 会员
- 注册时间: 2024-01-21
- 已发帖子: 29
- 积分: 4
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
@henman
现在确认性能了吗?
离线
#20 2024-08-30 17:59:19 分享评论
- dsp2000
- 会员
- 注册时间: 2024-01-21
- 已发帖子: 29
- 积分: 4
Re: 有没有人关注过cpu性能?我发现v3s的1.2G,比不过mips的600m,有没有高手来看看我是不是做错了?
ARM CortexTM-A7 MP1 Processor
Thumb-2 Technology
Support NEON Advanced SIMD(Single Instruction Multiple Data)instruction for acceleration of media and signal processing functions
Support Large Physical Address Extensions(LPAE)
VFPv4 Floating Point Unit
32KB L1 Instruction cache and 32KB L1 Data cache
128KB L2 cache
离线
东莞哇酷科技有限公司开发