楼主 # 2021-06-04 21:22:40 分享评论
- kekemuyu
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 857
- 积分: 698
玩一玩avr汇编,探究计算机的本质
avr单片机是很经典的8位mcu,因为arduino的火爆,直到现在依然很流行。在8位单片机开创性的引入了32个寄存器,两级流水线,risc结构直接降维打击了同时代的8051。以avr为例,探究一下计算机的本质。研究计算机原理可以看书,也可以做试验。我选择从试验开始,这样更有趣一些。现在做实验简单多了,各种虚拟环境和ide非常丰富。我选择用真机做实验,这样更实用和真实一些。
首先介绍一下用到的工具:
1.atmel studio,主要用它编译和仿真汇编代码
2.硬件,一个avr最小系统,我选择attiny13,研究汇编够用了
3.烧写器usb isp,以及烧写工具智峰下载器
4.avr汇编指令集手册,以及attiny13的手册
开篇上点灯程序:
.cseg
.org $0
rjmp start
.org $000A
start:
sbi DDRB,DDB0
sbi PORTB,PB0
Loop:
rjmp loop机器码对照:
.cseg
.org $0
000000 c009 rjmp start
.org $000A
start:
00000a 9ab8 sbi DDRB,DDB0
00000b 9ac0 sbi PORTB,PB0
Loop:
00000c cfff rjmp loophex格式
:020000020000FC
:0200000009C035
:06001400B89AC09AFFCF6C
:00000001FFflash memery快照:
prog 0x0000 09 c0 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff b8 9a c0 9a
prog 0x0018 ff cf ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ffhex格式解释:
数据个数 地址 类型 数据 crc校验
: 00 0000 00 000000... 00
下载器使用hex文件烧录数据到avr,中间经过了解析hex文件的过程。主要是取出机器码并烧录到flash。
avr的汇编格式是:
操作码---操作数/地址/空---操作数/地址/空
整条指令是16位或是32位(32位很少)
avr整个工作过程是,从mcu上电开始,pc指向flash的0地址,开始取指-执行重复下去,直至结束。我们每天使用的电脑办公、手机刷视频,在cpu看来都是一堆01010101。
我们可以用汇编开发mcu,也可以直接用机器码开发。上古计算机就是机器码编程,那时候是没有falsh,直接把01代码用纸带打孔的方式来表示,也就是说纸带相当于falsh。即使现在用机器码开发,比那时候也简单多了,直接在电脑上查询寄存器的地址并转为相应的机器码,然后烧进falsh即可。
离线
楼主 #1 2021-06-04 21:29:13 分享评论
- kekemuyu
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 857
- 积分: 698
Re: 玩一玩avr汇编,探究计算机的本质
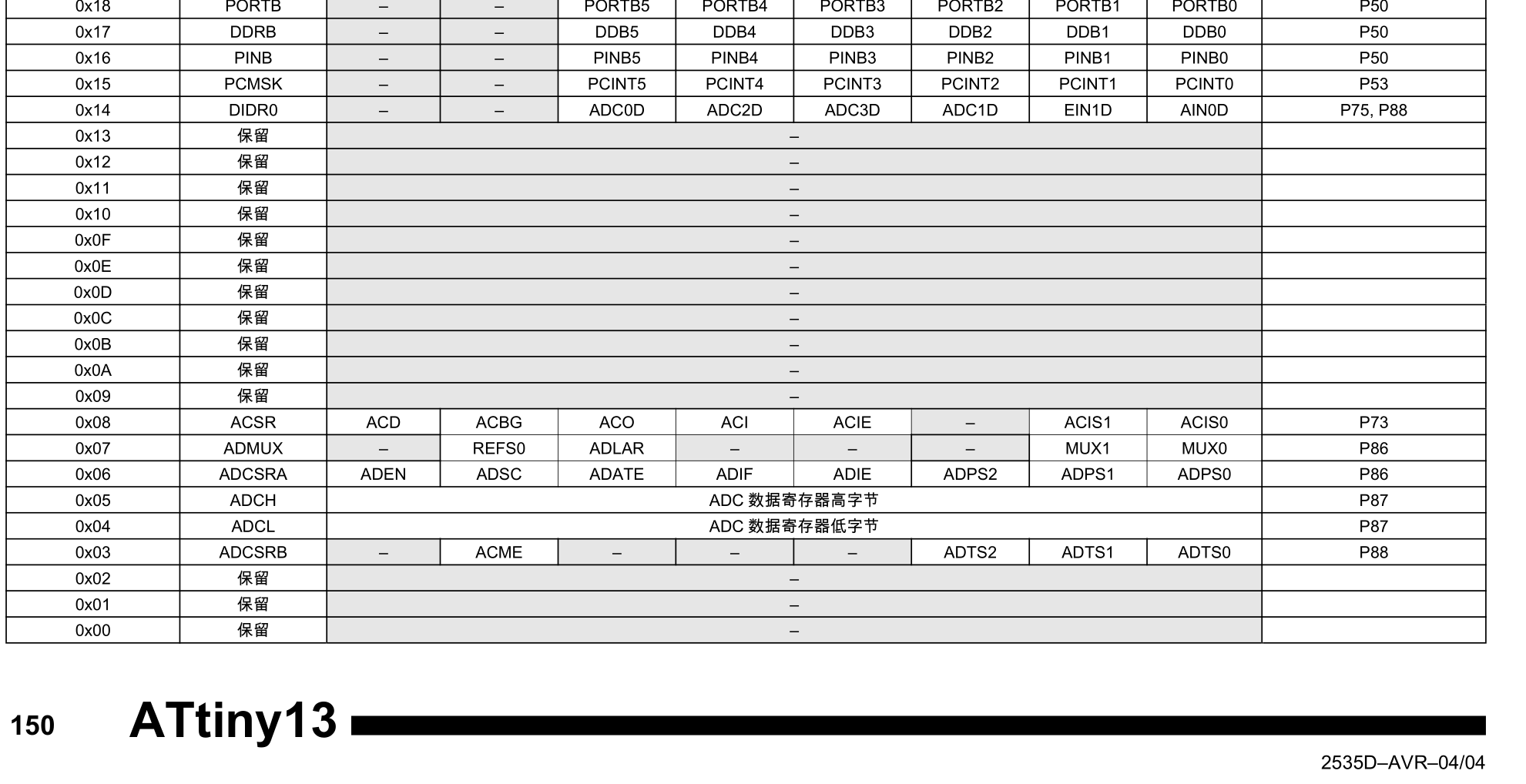
挖掘avr手册,发现保留寄存器,可以当作普通寄存器存储数据。
离线
#2 2021-06-04 22:00:09 分享评论
- cube
- 会员
- 注册时间: 2021-03-11
- 已发帖子: 288
- 积分: 202.5
Re: 玩一玩avr汇编,探究计算机的本质
欢迎进入裸机的世界, 我最近也在玩 arm9 gcc 汇编.
离线
楼主 #3 2021-06-04 22:30:28 分享评论
- kekemuyu
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 857
- 积分: 698
Re: 玩一玩avr汇编,探究计算机的本质
最近想研究一下单片机的汇编器,发现开源的汇编器非常少,基本上只有gnu家的,看来底层的东西很少人碰了。gcc的汇编器太复杂,毕竟他需要统筹考虑众多架构芯片,提取出了很多共有代码,看起来太费力。arm自家的汇编器又不开源,只能自己慢慢研究。可能cpu厂家也是为了省事,直接基于gcc写个新cpu的目标代码生成器就马上上市。没必要再单独再开发一个汇编器,毕竟现在最低层有人用的也是c语言。
离线
#4 2021-06-04 22:37:29 分享评论
- cube
- 会员
- 注册时间: 2021-03-11
- 已发帖子: 288
- 积分: 202.5
Re: 玩一玩avr汇编,探究计算机的本质
想要玩深入一点这是必经之路,汇编,Makefile, Linkscript, 体系结构都要涉猎。
离线
楼主 #5 2021-06-04 22:46:25 分享评论
- kekemuyu
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 857
- 积分: 698
Re: 玩一玩avr汇编,探究计算机的本质
从开始学编程就对操作系统、编译器这些东西感兴趣,大学时学8051汇编时就想用汇编写个调度器,最后写出了个简单的虚拟机跑在8051上
离线
#6 2021-06-05 00:51:22 分享评论
- novice
- 会员
- 注册时间: 2019-07-26
- 已发帖子: 126
- 积分: 107
Re: 玩一玩avr汇编,探究计算机的本质
8位机的汇编还是很简单的吧?x86才复杂。
离线
楼主 #7 2021-06-14 19:25:45 分享评论
- kekemuyu
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 857
- 积分: 698
Re: 玩一玩avr汇编,探究计算机的本质
单独学一种汇编不过瘾,顺便和其他架构汇编对比学习更有意思。今天看到arm架构比较有意思,37个寄存器,但有很多同名的寄存器,在不同工作模式加以区分。不知道为什么当初这样设计,7种工作模式,不同模式可访问寄存器是一般是不一样的。
离线
#8 2021-06-14 20:14:46 分享评论
- 孤星泪
- 会员
- 注册时间: 2020-03-18
- 已发帖子: 235
- 积分: 231
Re: 玩一玩avr汇编,探究计算机的本质
@kekemuyu
当然是为了效率, 这样入栈出栈就不用保存那么多寄存器了.
离线
#9 2021-06-15 22:05:04 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 367
- 积分: 373.5
Re: 玩一玩avr汇编,探究计算机的本质
要是没有Arduino续命,AVR坟头的草得20米高了吧
离线
楼主 #10 2021-06-17 16:50:58 分享评论
- kekemuyu
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 857
- 积分: 698
Re: 玩一玩avr汇编,探究计算机的本质
atiny13没有硬件串口,用软件模拟。发送模拟比较简单,接收就有点复杂了,先做发送。汇编模拟串口发送:
;
; ***********************************
; * (Add program task here) *
; * (Add AVR type and version here) *
; * (C)2019 by Gerhard Schmidt *
; ***********************************
;
.nolist
.include "tn13adef.inc" ; Define device ATtiny13A
.list
;
; **********************************
; H A R D W A R E
; **********************************
;
; (F2 adds ASCII pin-out for device here)
;
; **********************************
; P O R T S A N D P I N S
; **********************************
;
; (Add symbols for all ports and port pins with ".equ" here)
; (e.g. .equ pDirD = DDRB ; Define a direction port
; or
; .equ bMyPinO = PORTB0 ; Define an output pin)
;
; **********************************
; A D J U S T A B L E C O N S T
; **********************************
;
; (Add all user adjustable constants here, e.g.)
.equ clock=9600000 ; Define the clock frequency
.equ baudRate=115200
.equ TX_DELAY = (clock / baudRate - 9) / 3;
;.equ cycle_t = 1000000 / clock
.equ wait_cnt_10us = 10 ;10 / cycle_t / 10
;
; **********************************
; F I X & D E R I V. C O N S T
; **********************************
;
; (Add symbols for fixed and derived constants here)
;
; **********************************
; R E G I S T E R S
; **********************************
;
; free: R0 to R14
.def rSreg = R15 ; Save/Restore status port
.def rmp = R16 ; Define multipurpose register
; free: R17 to R29
; used: R31:R30 = Z for ...
;
.def TX_BITS_NBR_TMP = R18
.def WAIT_NBR_TMP = R19
.def BYTE_TO_TRANSMIT = R24
.def WAIT_NBR = R22
; **********************************
; S R A M
; **********************************
;
.dseg
.org SRAM_START
; (Add labels for SRAM locations here, e.g.
; sLabel1:
; .byte 16 ; Reserve 16 bytes)
;
; **********************************
; C O D E
; **********************************
;
.cseg
.org 000000
;
; **********************************
; R E S E T & I N T - V E C T O R S
; **********************************
rjmp Main ; Reset vector
reti ; INT0
reti ; PCI0
reti ; OVF0
reti ; ERDY
reti ; ACI
reti ; OC0A
reti ; OC0B
reti ; WDT
reti ; ADCC
;
; **********************************
; I N T - S E R V I C E R O U T .
; **********************************
;
; (Add all interrupt service routines here)
;
; **********************************
; M A I N P R O G R A M I N I T
; **********************************
;
Main:
ldi rmp,Low(RAMEND)
out SPL,rmp ; Init LSB stack pointer
; ...
; sei ; Enable interrupts
;
; **********************************
; P R O G R A M L O O P
; **********************************
;
ldi WAIT_NBR,TX_DELAY
ldi BYTE_TO_TRANSMIT,0x0A
rcall SerialAsmTx_4
Loop:
ldi WAIT_NBR,TX_DELAY
ldi BYTE_TO_TRANSMIT,0x0A
rcall SerialAsmTx_4
ldi r28,50
rcall delay_500ms
rjmp loop
;
; End of source code
SerialAsmTx_4:
cli
sbi DDRB, PB4
ldi TX_BITS_NBR_TMP, 10
com BYTE_TO_TRANSMIT
TxLoop_4:
brcc Tx1_4
cbi PORTB, PB4
Tx1_4:
brcs TxDone_4
sbi PORTB, PB4
TxDone_4:
mov WAIT_NBR_TMP, WAIT_NBR
TxDelay_4:
dec WAIT_NBR_TMP
brne TxDelay_4
lsr BYTE_TO_TRANSMIT
dec TX_BITS_NBR_TMP
brne TxLoop_4
reti
;10 cycles,per loop
delay_500ms:
ldi r25,wait_cnt_10us
ldi r26,100
ldi r27,10
loop1:
nop
nop
nop
nop
nop
nop
nop
dec r25
brne loop1
dec r26
ldi r25, wait_cnt_10us
brne loop1
ldi r26,100
dec r27
brne loop1
ldi r27,10
dec r28
brne loop1
ret
;
; (Add Copyright information here, e.g.
; .db "(C)2019 by Gerhard Schmidt " ; Source code readable
; .db "C(2)10 9ybG reahdrS hcimtd " ; Machine code format
;离线
#11 2021-06-23 16:50:07 分享评论
- szchen2006
- 会员
- 注册时间: 2019-10-09
- 已发帖子: 216
- 积分: 166.5
Re: 玩一玩avr汇编,探究计算机的本质
离线
- 不通过:与技术无关
楼主 #12 2021-07-19 19:22:20 分享评论
- kekemuyu
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 857
- 积分: 698
Re: 玩一玩avr汇编,探究计算机的本质
go语言开发的avr汇编器之词法分析已完成,主要流程是建立词法的状态转换表,表建成工作基本完成80%,整个流程就是表驱动。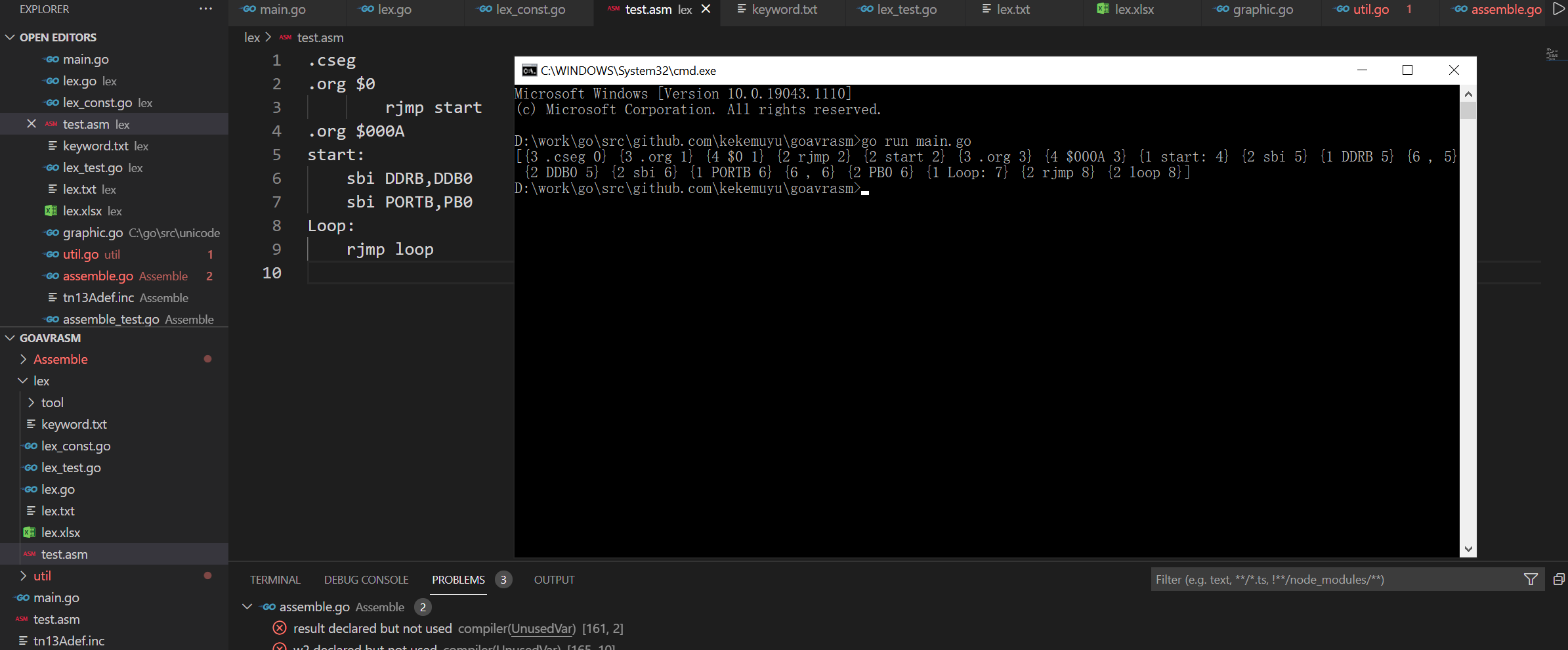
离线
#13 2021-07-20 09:09:55 分享评论
- touchey
- 会员
- 注册时间: 2020-05-18
- 已发帖子: 143
- 积分: 16
Re: 玩一玩avr汇编,探究计算机的本质
离线
- 不通过:其他
楼主 #14 2021-07-23 00:14:55 分享评论
- kekemuyu
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 857
- 积分: 698
Re: 玩一玩avr汇编,探究计算机的本质
后面的跟贴内容可能会一直涉及编译原理的内容,有些晦涩,只有对编译原理感兴趣的同学才会感兴趣吧!无论如何编译原理是了解计算机本质的一种途径,它涉及到计算体系的各个方面,学之受益无穷。今天就让编译原理这个大棒降维打击一下表达式的求解。
让程序求解一个表达式如123+234*(12/2),应该如何出处理呢?不同的思路可能有不同的答案,这里用编译原理这把牛刀宰它。
整体思路:
词法分析->语法分析->语义分析
其中需要说明的是语义分析是包含在语法分析中的,因为用的是语法制导翻译方法。
0.文法
E->T E1
E1->op1|T fun1 E1|null
T->F T1
T1->op2 F fun1 T1| null
F->(E)|-F fun2|I
I->const fun3
op1->+fun4|-fun5
op2->*fun6|/fun6
1.词法分析
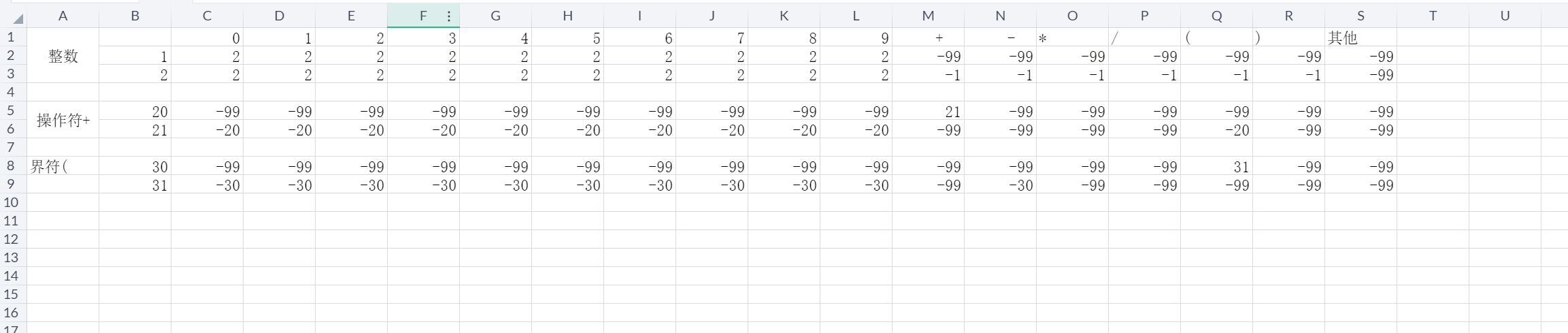
词法分析是比较简单,主要分为三类:
数字:0-9
界符:( )
运算符:+,-,*,/
建立词法分析表(只是举例和代码并不匹配):
由词法分析表驱动词法解析程序,效果如下:
token结构是:
type Token struct {
Kind int //类型
Content string //值
RowNum int //行数
}
[{1 123 0} {2 + 0} {1 234 0} {2 * 0} {3 ( 0} {1 12 0} {2 / 0} {1 2 0} {3 ) 0}]
2.语法分析
核心框图:
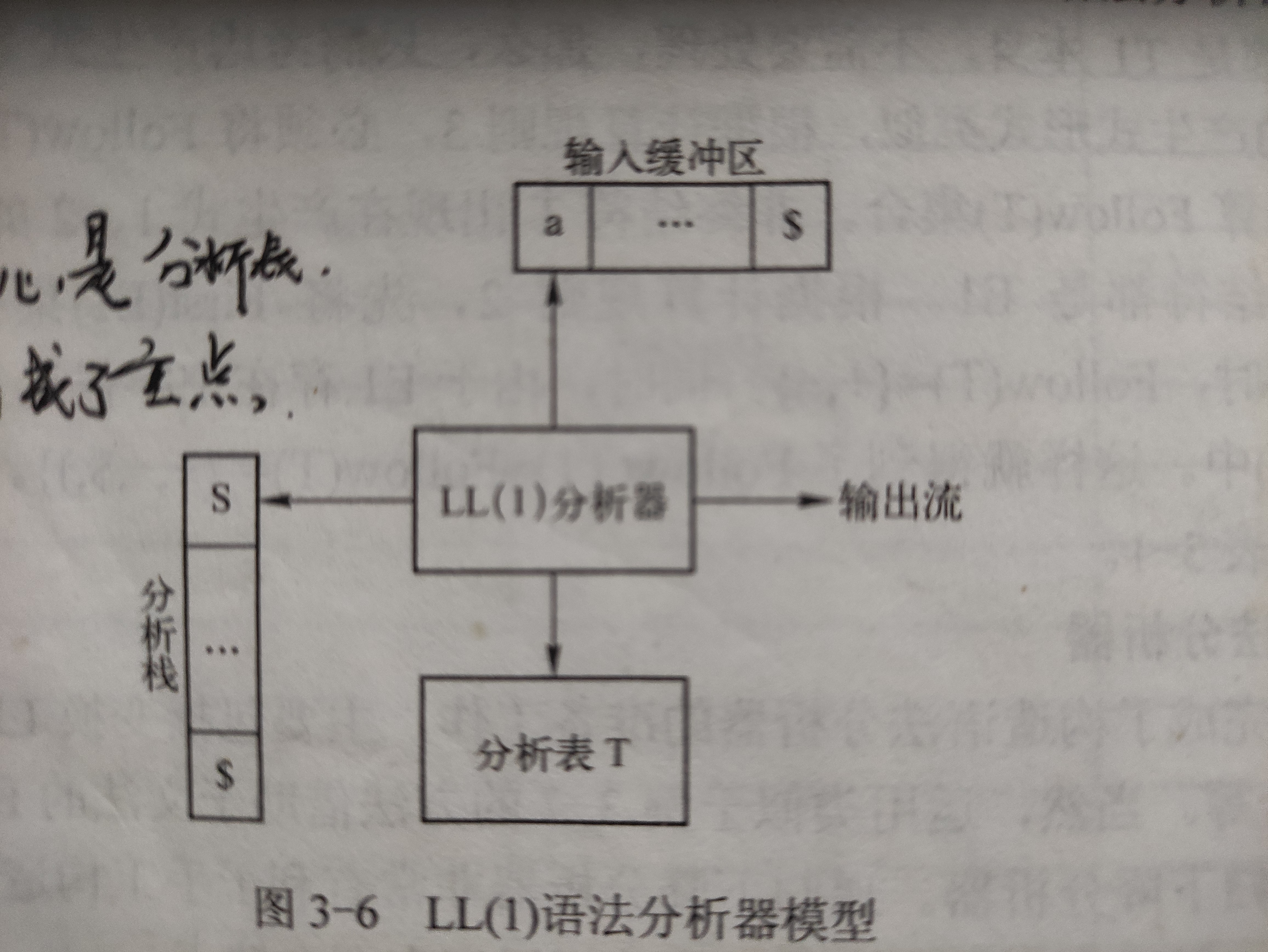
由文法规则获取first集和follow集,进而建立语法分析表:
var sParseTable = [8][8]string{
// + - * / const ( ) $
{"err", "T,E1", "err", "err", "T,E1", "T,E1", "err", "err"}, //E
{"op1,T,fun1,E1", "op1,T,fun1,E1", "err", "err", "err", "err", "null", "null"}, //E1
{"err", "F,T1", "err", "err", "F,T1", "F,T1", "err", "err"}, //T
{"null", "null", "op2,F,fun1,T1", "op2,F,fun1,T1", "err", "err", "null", "null"}, //T1
{"err", "-,F,fun2", "err", "err", "I", "(,E,)", "err", "err"}, //F
{"err", "err", "err", "err", "const,fun3", "err", "err", "err"}, //I
{"+,fun4", "-,fun5", "err", "err", "err", "err", "err", "err"}, //op1
{"err", "err", "*,fun6", "/,fun7", "err", "err", "err", "err"}, //op2
}分析器核心程序:
func (c *Calc) Parse() bool {
iListPos := 0
var ival DataStack
for c.ParseStack.Len() != 0 && iListPos < len(c.TokenList) {
el := c.ParseStack.Back()
ival = el.Value.(DataStack)
c.ParseStack.Remove(el)
if ival.Kind == "VT" { //非终结符
icol := "$"
if c.TokenList[iListPos].Kind == TOKEN_KIND_CONST {
icol = "const"
} else if c.TokenList[iListPos].Kind == TOKEN_KIND_OPRATOR {
icol = c.TokenList[iListPos].Content
} else if c.TokenList[iListPos].Kind == TOKEN_KIND_SPLITE {
icol = c.TokenList[iListPos].Content
}
if v, ok := c.ParseTables[Pcell{ival.Data, icol}]; ok { //查询语法分析表
if v.Data == "err" {
log.Fatal("row,col:", ival.Data, c.TokenList[iListPos])
} else if v.Data == "null" {
continue
} else {
tmp := strings.Split(v.Data, ",")
for k, _ := range tmp {
re := tmp[len(tmp)-k-1]
kind := ""
if isVT(re) {
kind = "VT" //非终结
} else if isFUN(re) {
kind = "FUN" //语义部分
} else {
kind = "VN" //终结
}
ds := DataStack{
Data: re,
Kind: kind,
}
c.ParseStack.PushBack(ds) //反序入栈
}
}
} else {
log.Fatal("row,col:", ival.Data, c.TokenList[iListPos])
}
} else if ival.Kind == "VN" { //终结符
fmt.Println("VN:", ival)
iListPos += 1 //下一个输入流
} else if ival.Kind == "FUN" { //语义处理
fmt.Println("FUN:", ival)
switch ival.Data {
case "fun1":
c.fun1()
case "fun2":
c.fun2()
case "fun3":
c.fun3(c.TokenList[iListPos-1].Content)
case "fun4":
c.fun4()
case "fun5":
c.fun5()
case "fun6":
c.fun6()
case "fun7":
c.fun7()
}
// fmt.Println("FUN END:", c.OprateDataStack.Back().Value, c.OprateSplitStack.Back().Value)
}
ps := make([]string, 0)
for i := c.ParseStack.Back(); i != nil; i = i.Prev() {
ps = append(ps, i.Value.(DataStack).Data)
}
fmt.Println("ps:", ps)
}
if c.ParseStack.Len() == 0 && iListPos == len(c.TokenList) {
c.Result = c.OprateDataStack.Back().Value.(string)
return true
} else {
return false
}
}现在代码还有点乱,等整理后会上传至github。有词法分析和语法制导翻译的知识可以基本写一个简单的avr汇编器了。
最近编辑记录 kekemuyu (2021-07-23 00:19:33)
离线
东莞哇酷科技有限公司开发