楼主 #1 2020-04-25 00:28:20 分享评论
- Quotation
- 会员
- 注册时间: 2018-10-04
- 已发帖子: 307
- 积分: 266.5
调通F1C100s的SPI DMA
初步调通SPI DMA,成果喜人。
SPI Tx和Rx都用上DMA,接示波器看CLK信号。当通过寄存器设置SPI速率设为100MHz的时候,CLK信号实际能跑到96MHz。SPI速率设为50MHz的时候,实际CLK为49.xMHz。
(用XBoot不管怎么设速率,实际的只能到25MHz。一方面是没用DMA,一方面是XBoot的代码不够优化。)实验用DMA加持的SPI驱动ST7789串口屏。240x240分辨率、RGB565,SPI跑满50MHz,屏幕帧率可以到54。非常满意了。
实验时是用杜邦线接的屏,也许走线好一点的话还能支持更高速率。我现在是只能跑到50MHz了,多1M显示就开始乱了。实验DMA做内存拷贝,结果如下。DMA拷贝内存,速度并没比memcpy快多少。
有几个参数能影响DMA拷贝速度:1) DMA的种类,用NDMA还是DDMA;2) data width 3) burst length。
而memcpy速度受CPU主频影响(一点点)。
拷贝128KB数据比较:
memcpy 2.4ms(640MHz主频)
DDMA 1.9ms(data width = 32-bit,burst length = 4)
NDMA 2.6ms(data width = 32-bit,burst length = 4)
DDMA拷贝内存最快能到memcpy的1.25倍。
另外,发现DDMA拷贝较大的数据会出错,比如拷贝1MB数据,第一次成功,第二次就从1020KB开始数据不正确了。可能是缓存的原因,待研究。
离线
#2 2020-04-26 09:20:41 分享评论
- 泡在妞里的Feel
- 会员
- 注册时间: 2019-09-09
- 已发帖子: 49
- 积分: 44
Re: 调通F1C100s的SPI DMA
666,DMA部分的代码可否分享一下。
离线
#3 2020-04-26 10:43:44 分享评论
- asdfa
- 会员
- 注册时间: 2020-04-26
- 已发帖子: 6
- 积分: 6
Re: 调通F1C100s的SPI DMA
DMS和正常拷贝的数据,速率可以对比下
离线
#4 2020-04-26 11:19:44 分享评论
- 泡在妞里的Feel
- 会员
- 注册时间: 2019-09-09
- 已发帖子: 49
- 积分: 44
Re: 调通F1C100s的SPI DMA
求赐教,这两个寄存器是什么功能?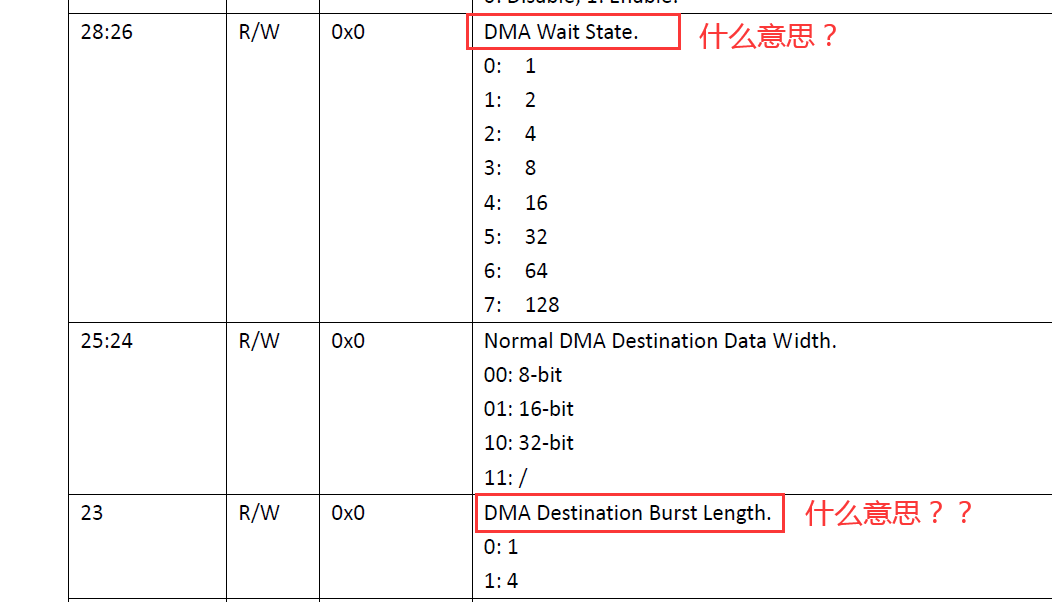
离线
#5 2020-04-26 11:23:32 分享评论
- ntmusic
- 会员
- 注册时间: 2020-02-24
- 已发帖子: 43
- 积分: 28
Re: 调通F1C100s的SPI DMA
水一贴,DMA结合操作系统才能比较好发挥优势,在等待DMA传输结束时CPU可以很方便的切换出去做别的事情,而裸机则一般要通过设置状态结合中断来使用,程序结构也会变得奇奇怪怪,若使用查询等待的话可能还不如直接使用CPU操作来的快,因为CPU一般拥有总线最高优先权
离线
#6 2020-04-26 11:37:08 分享评论
- armstrong
- 会员

- 注册时间: 2019-04-10
- 已发帖子: 295
- 积分: 189.5
Re: 调通F1C100s的SPI DMA
ntmusic wrote:
水一贴,DMA结合操作系统才能比较好发挥优势,在等待DMA传输结束时CPU可以很方便的切换出去做别的事情,而裸机则一般要通过设置状态结合中断来使用,程序结构也会变得奇奇怪怪,若使用查询等待的话可能还不如直接使用CPU操作来的快,因为CPU一般拥有总线最高优先权
说的很对,一点都不水!
离线
楼主 #7 2020-04-26 17:09:13 分享评论
- Quotation
- 会员
- 注册时间: 2018-10-04
- 已发帖子: 307
- 积分: 266.5
Re: 调通F1C100s的SPI DMA
Quotation wrote:
另外,发现DDMA拷贝较大的数据会出错,比如拷贝1MB数据,第一次成功,第二次就从1020KB开始数据不正确了。可能是缓存的原因,待研究。
这个问题是简单的cache问题,从另一个帖子里@armstrong 的回复明白了。正确invalidate和clean缓存后就没有传输错误了。DDMA一次可以传16M,NDMA一次可以256KB(文档上说是128KB)。
离线
楼主 #8 2020-04-26 17:16:52 分享评论
- Quotation
- 会员
- 注册时间: 2018-10-04
- 已发帖子: 307
- 积分: 266.5
Re: 调通F1C100s的SPI DMA
泡在妞里的Feel wrote:
666,DMA部分的代码可否分享一下。
现在还有点玄学问题没有解决,以后解决了再分享……
代码里有时候多一行少一行无关代码,显示屏就花屏了。可能是时序的问题,也可能是字节对齐的问题,还没弄明白。
另外,我是很想分享代码,但是代码混在项目里,要分享出来还得抠,抠出来又不能直接跑。
要是全志有一套像STM32那样的标准库,分享资料会更方便。
离线
楼主 #9 2020-04-26 17:24:38 分享评论
- Quotation
- 会员
- 注册时间: 2018-10-04
- 已发帖子: 307
- 积分: 266.5
Re: 调通F1C100s的SPI DMA
泡在妞里的Feel wrote:
求赐教,这两个寄存器是什么功能?
/files/members/1964/test.png
Wait State意思不知道。
Burst Length大约是每次传输数据,在总线上连续传几个“Data Width”那么大的数据。
对于从内存到内存,Burst Length设为4直接就可以用。
对于从内存到外设或外设到内存的DMA,如果Burst Length设为4,外设的FIFO一般有trigger level也要对应改。比如trigger level默认为1,表示FIFO里只要有1个数据就发送DRQ,让DMA来拷走。当Burst Length为4,trigger level也要>=4。
反过来,如果是从内存到外设拷数据的,FIFO的trigger level需要 <= (FIFO总长度 - 4)。
离线
楼主 #10 2020-04-26 17:29:19 分享评论
- Quotation
- 会员
- 注册时间: 2018-10-04
- 已发帖子: 307
- 积分: 266.5
Re: 调通F1C100s的SPI DMA
ntmusic wrote:
水一贴,DMA结合操作系统才能比较好发挥优势,在等待DMA传输结束时CPU可以很方便的切换出去做别的事情,而裸机则一般要通过设置状态结合中断来使用,程序结构也会变得奇奇怪怪,若使用查询等待的话可能还不如直接使用CPU操作来的快,因为CPU一般拥有总线最高优先权
确实,有OS抽象出线程或task的概念会方便使用。不过如果代码写得巧,裸奔也清爽的:D。
比如把中断封装成回调,用C++的lambda写回调实在很方便。
离线
#11 2020-04-29 09:49:14 分享评论
- a3748622
- 会员
- 注册时间: 2019-09-04
- 已发帖子: 8
- 积分: 3
Re: 调通F1C100s的SPI DMA
这个强悍了,如果跑100m,开机速度能提升很多的。不用花好几秒傻傻等数据复制了
离线
#12 2020-05-21 10:29:20 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
Re: 调通F1C100s的SPI DMA
Quotation wrote:
Wait State意思不知道。
Burst Length大约是每次传输数据,在总线上连续传几个“Data Width”那么大的数据。
对于从内存到内存,Burst Length设为4直接就可以用。
对于从内存到外设或外设到内存的DMA,如果Burst Length设为4,外设的FIFO一般有trigger level也要对应改。比如trigger level默认为1,表示FIFO里只要有1个数据就发送DRQ,让DMA来拷走。当Burst Length为4,trigger level也要>=4。
反过来,如果是从内存到外设拷数据的,FIFO的trigger level需要 <= (FIFO总长度 - 4)。
这个Burst Length是不是应该理解为一次总线占用,Burst Length次总线传输,实际等效为Burst Length * Data Width
我记得stm32后续版本(非f1系列)的dma就有这种概念
离线
#13 2020-05-27 19:00:53 分享评论
- myxiaonia
- 会员
- 注册时间: 2019-06-18
- 已发帖子: 83
- 积分: 51.5
Re: 调通F1C100s的SPI DMA
请问楼主有没有遇到spi在用户程序可行,spl代码不行的问题
向这个代码,能不能看出有什么问题?
void sys_spi_flash_read(int addr, void* buf, int count)
{
uint8_t p = (uint8_t )buf;
SPI0->TXD = 0x03 | util_rev(addr);
SPI0->MBC = 4 + count;
SPI0->MTC = 4;
SPI0->BCC = 4;
SPI0->TCR |= SPI_TCR_XCH;
while (count > 0) {
if((SPI0->FSR & SPI_FSR_RXFIFO_CNT) >= 1)
{
p++ = (uint8_t *)&SPI0->RXD;
count -= 1;
}
}
}
离线
#14 2020-09-15 17:22:28 分享评论
- liuyuedong
- 会员
- 注册时间: 2020-02-09
- 已发帖子: 38
- 积分: 28
Re: 调通F1C100s的SPI DMA
楼主能大概说一下,程序是怎样配置的吗?现在正在做spi + DMA,没有调通
离线
#15 2020-09-16 13:50:40 分享评论
- liuyuedong
- 会员
- 注册时间: 2020-02-09
- 已发帖子: 38
- 积分: 28
Re: 调通F1C100s的SPI DMA
参考了坑网的其他的spi dma程序,还是没有调通。。。单独的spi 和 dma m2m都通了,不知道哪里配置错了,楼主可否分享一下源码或者配置
离线
#16 2020-09-18 14:57:00 分享评论
- david
- 会员
- 注册时间: 2018-03-05
- 已发帖子: 397
- 积分: 328.5
Re: 调通F1C100s的SPI DMA
liuyuedong wrote:
参考了坑网的其他的spi dma程序,还是没有调通。。。单独的spi 和 dma m2m都通了,不知道哪里配置错了,楼主可否分享一下源码或者配置
你的DMA怎么搞的,有没有代码可以参考,想把DMA裸奔单独弄个驱动。摸黑搞代码不容易,一来靠经验,二来靠朋友。楼主提供的测试数据很有参考价值。
离线
#17 2020-09-19 09:33:36 分享评论
- liuyuedong
- 会员
- 注册时间: 2020-02-09
- 已发帖子: 38
- 积分: 28
Re: 调通F1C100s的SPI DMA
david wrote:
liuyuedong wrote:
参考了坑网的其他的spi dma程序,还是没有调通。。。单独的spi 和 dma m2m都通了,不知道哪里配置错了,楼主可否分享一下源码或者配置
你的DMA怎么搞的,有没有代码可以参考,想把DMA裸奔单独弄个驱动。摸黑搞代码不容易,一来靠经验,二来靠朋友。楼主提供的测试数据很有参考价值。
你参考这三个:
https://whycan.com/t_1514.html
https://whycan.com/t_3405.html
https://whycan.com/t_5298.html
离线
#18 2022-09-27 17:19:07 分享评论
- lfs911
- 会员
- 注册时间: 2020-09-24
- 已发帖子: 38
- 积分: 23
Re: 调通F1C100s的SPI DMA
楼主的代码能分享下嘛,调了多天了,上面的资料都参考了,现在的问题是dma发送只能发送一个字节就结束了
离线
#19 2023-01-17 14:44:35 分享评论
- QJJAXSP
- 会员
- 注册时间: 2023-01-10
- 已发帖子: 5
- 积分: 0
Re: 调通F1C100s的SPI DMA
请问 寄存器设置SPI速率设为100MHz 如何实现的
离线
#20 2023-02-09 15:33:33 分享评论
- wj8331585
- 会员
- 注册时间: 2023-02-07
- 已发帖子: 44
- 积分: 19
Re: 调通F1C100s的SPI DMA
要是有像ST那样有代码生成的IDE就爽歪歪了。
离线
#21 2023-06-09 00:16:18 分享评论
- jiabuda
- 会员
- 注册时间: 2023-06-05
- 已发帖子: 24
- 积分: 9
Re: 调通F1C100s的SPI DMA
我也在做f1c100s驱动ST7789,跑lvgl还不如esp32,画面撕扯严重,想问一下是不是dma问题,还是说芯片性能就那样
离线
#22 2023-06-09 09:38:57 分享评论
- dykxjh
- 会员
- 注册时间: 2020-03-25
- 已发帖子: 190
- 积分: 150
Re: 调通F1C100s的SPI DMA
弱弱的问一句,DDMA也能和NDAM一样使用吗?我一直没搞清楚这2者的区别。
离线
#23 2023-06-09 09:40:13 分享评论
- dykxjh
- 会员
- 注册时间: 2020-03-25
- 已发帖子: 190
- 积分: 150
Re: 调通F1C100s的SPI DMA
@Quotation
DDMA一次可以传16M,NDMA一次可以256KB(文档上说是128KB)。我看文档上是128KB,那么你说的256KB是基于什么得出的结论呢?
离线
#25 2023-07-10 16:47:21 分享评论
- kenshin067
- 会员
- 注册时间: 2023-06-07
- 已发帖子: 4
- 积分: 4
Re: 调通F1C100s的SPI DMA
DMA的拷贝速度和直接CPU的拷贝速度,理论上是跟CLK挂钩,用DMA的关键是可以解放CPU,所以配合操作系统就可以在DMA拷贝的过程中,让CPU切到其他任务,等数据拷贝完成,再切回来继续任务
离线
#26 2023-10-12 17:17:23 分享评论
- wenjiu
- 会员
- 注册时间: 2023-10-12
- 已发帖子: 6
- 积分: 1
Re: 调通F1C100s的SPI DMA
楼主能再分享一下spi + dma的启动代码?
离线
东莞哇酷科技有限公司开发