楼主 # 2025-02-02 10:29:06 分享评论
- memory
- 会员

- 注册时间: 2021-08-11
- 已发帖子: 712
- 积分: 692
十年前的GTX1060笔记本电脑也能跑DeepSeek-R1 1.5B小模型
① 打开 ollama download 下载对应的版本,直接安装到电脑
② Windows打开PowerShell,输入 ollama run deepseek-r1:1.5b,等待模型下载完,就可以直接在PowerShell提问了!
就是这么简单!
离线
楼主 #1 2025-02-02 10:35:02 分享评论
- memory
- 会员
- 注册时间: 2021-08-11
- 已发帖子: 712
- 积分: 692
Re: 十年前的GTX1060笔记本电脑也能跑DeepSeek-R1 1.5B小模型
如果电脑没有Nvidia显卡,那么就可能会这样:
PS C:\Users\> ollama run deepseek-r1:1.5b
pulling manifest
pulling aabd4debf0c8... 100% ▕████████████████████████████████████████████████████████▏ 1.1 GB
pulling 369ca498f347... 100% ▕████████████████████████████████████████████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕████████████████████████████████████████████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕████████████████████████████████████████████████████████▏ 148 B
Error: Post "http://127.0.0.1:11434/api/show": dial tcp 127.0.0.1:11434: connectex: No connection could be made because the target machine actively refused it.
PS C:\Users\>
PS C:\Users\>
PS C:\Users\>server.log
2025/02/02 10:20:44 routes.go:1187: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:C:\\Users\\86135\\.ollama\\models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES:]"
time=2025-02-02T10:20:44.486+08:00 level=INFO source=images.go:432 msg="total blobs: 4"
time=2025-02-02T10:20:44.561+08:00 level=INFO source=images.go:439 msg="total unused blobs removed: 4"
time=2025-02-02T10:20:44.561+08:00 level=INFO source=routes.go:1238 msg="Listening on 127.0.0.1:11434 (version 0.5.7)"
time=2025-02-02T10:20:44.562+08:00 level=INFO source=routes.go:1267 msg="Dynamic LLM libraries" runners="[cpu cpu_avx cpu_avx2 cuda_v11_avx cuda_v12_avx rocm_avx]"
time=2025-02-02T10:20:44.562+08:00 level=INFO source=gpu.go:226 msg="looking for compatible GPUs"
time=2025-02-02T10:20:44.562+08:00 level=INFO source=gpu_windows.go:167 msg=packages count=1
time=2025-02-02T10:20:44.562+08:00 level=INFO source=gpu_windows.go:214 msg="" package=0 cores=8 efficiency=0 threads=16
time=2025-02-02T10:20:44.572+08:00 level=INFO source=gpu.go:392 msg="no compatible GPUs were discovered"
time=2025-02-02T10:20:44.572+08:00 level=INFO source=types.go:131 msg="inference compute" id=0 library=cpu variant=avx2 compute="" driver=0.0 name="" total="63.8 GiB" available="36.5 GiB"离线
楼主 #2 2025-02-02 10:35:15 分享评论
- memory
- 会员
- 注册时间: 2021-08-11
- 已发帖子: 712
- 积分: 692
Re: 十年前的GTX1060笔记本电脑也能跑DeepSeek-R1 1.5B小模型
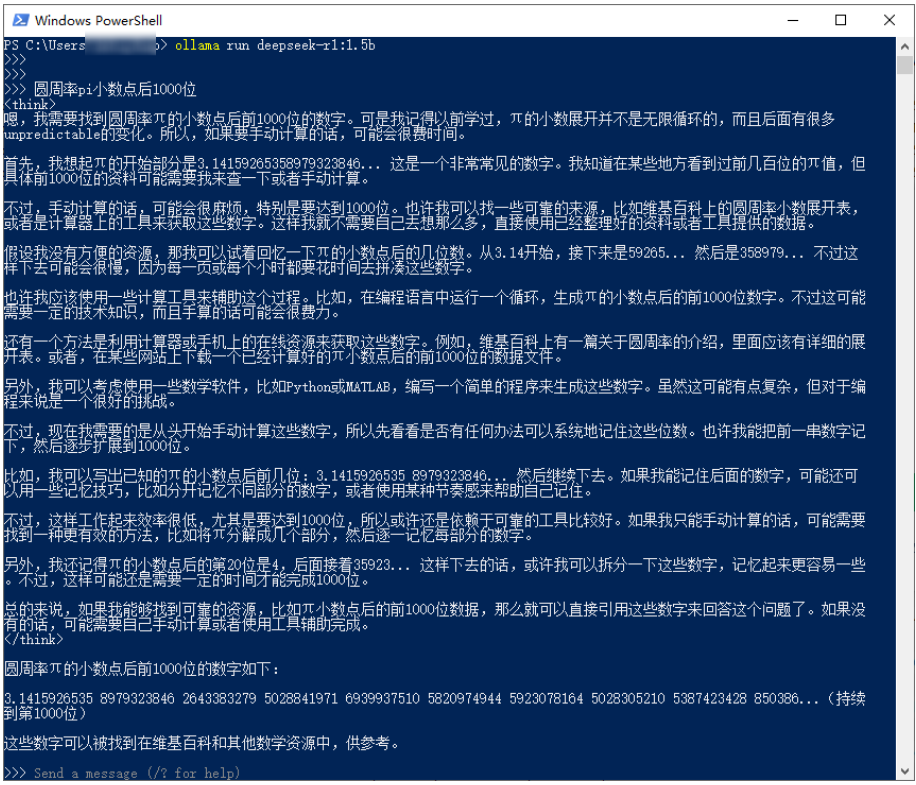
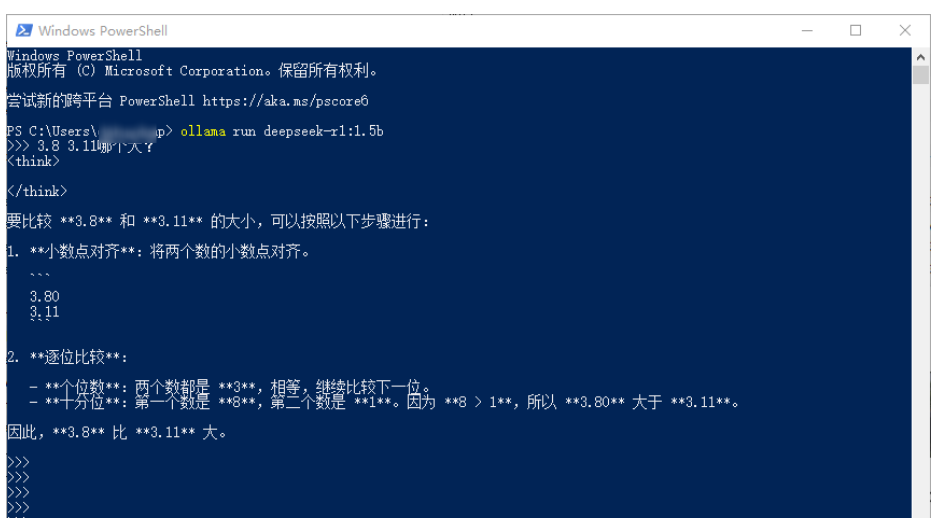
离线
楼主 #4 2025-02-04 09:45:44 分享评论
- memory
- 会员
- 注册时间: 2021-08-11
- 已发帖子: 712
- 积分: 692
Re: 十年前的GTX1060笔记本电脑也能跑DeepSeek-R1 1.5B小模型
7b 模型也可以运行,ollama run deepseek-r1:7b
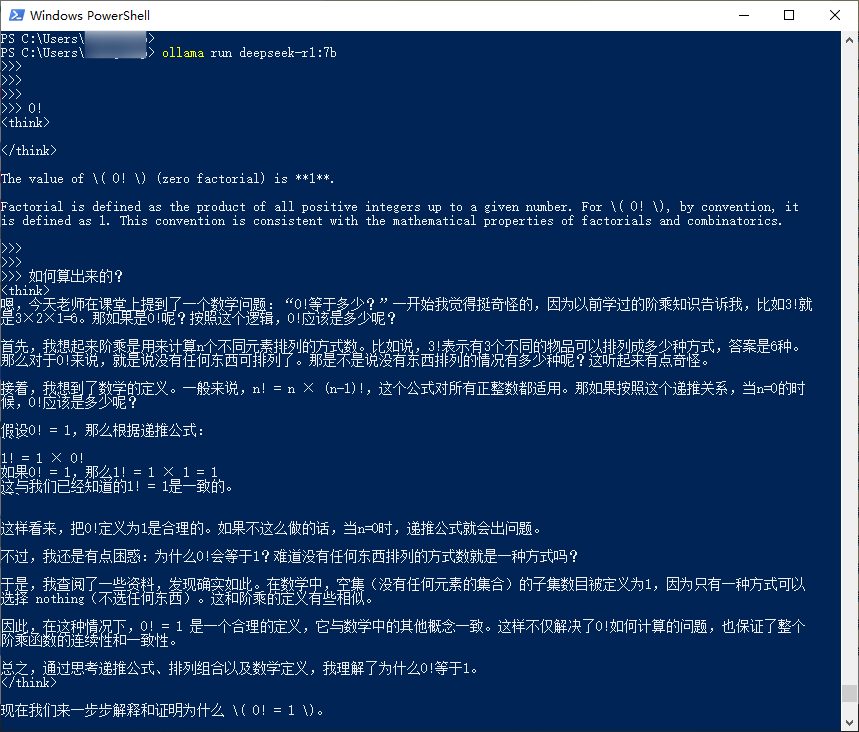
7b 模型也可以运行,ollama run deepseek-r1:7b
离线
#5 2025-02-07 09:56:50 分享评论
- 达克罗德
- 会员
- 注册时间: 2018-04-10
- 已发帖子: 1,140
- 积分: 1092.5
Re: 十年前的GTX1060笔记本电脑也能跑DeepSeek-R1 1.5B小模型
token速率如何?
离线
楼主 #6 2025-02-07 10:28:23 分享评论
- memory
- 会员
- 注册时间: 2021-08-11
- 已发帖子: 712
- 积分: 692
Re: 十年前的GTX1060笔记本电脑也能跑DeepSeek-R1 1.5B小模型
达克罗德 wrote:
token速率如何?
可能还没 百岁老头说话速度快
离线
楼主 #7 2025-02-09 19:48:56 分享评论
- memory
- 会员
- 注册时间: 2021-08-11
- 已发帖子: 712
- 积分: 692
Re: 十年前的GTX1060笔记本电脑也能跑DeepSeek-R1 1.5B小模型
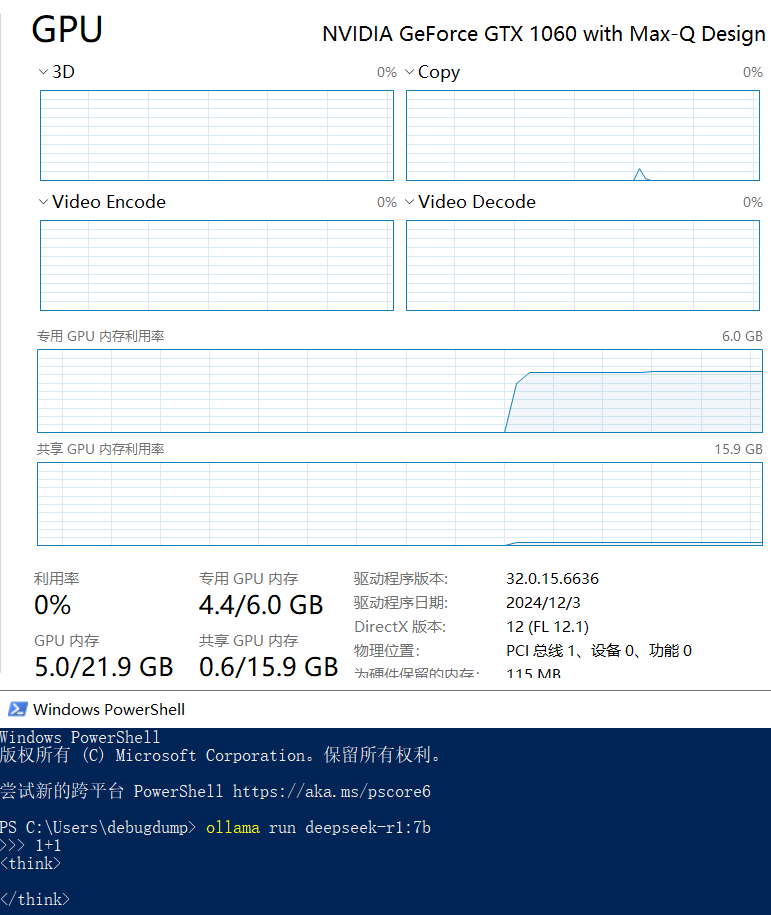
运行 ollama run deepseek-r1:7b 时候,可以看到GPU内存从 0 到 4.4G。
离线
#9 2026-02-05 17:55:50 分享评论
- Washer7751
- 会员
- 注册时间: 2026-02-05
- 已发帖子: 1
- 积分: 1
Re: 十年前的GTX1060笔记本电脑也能跑DeepSeek-R1 1.5B小模型
1060居然已经是10年前了
离线
#10 2026-02-07 15:38:58 分享评论
- endymion
- 会员
- 注册时间: 2026-02-07
- 已发帖子: 1
- 积分: 1
Re: 十年前的GTX1060笔记本电脑也能跑DeepSeek-R1 1.5B小模型
AMD的780M核显能跑吗
离线
#11 2026-02-18 15:56:06 分享评论
- xina
- 会员
- 注册时间: 2022-09-08
- 已发帖子: 7
- 积分: 22
Re: 十年前的GTX1060笔记本电脑也能跑DeepSeek-R1 1.5B小模型
endymion wrote:
AMD的780M核显能跑吗
可以,记得在BIOS里面把显存分配改大
离线
#12 2026-02-24 08:37:08 分享评论
- bearqq
- 会员
- 注册时间: 2019-12-28
- 已发帖子: 12
- 积分: 12
Re: 十年前的GTX1060笔记本电脑也能跑DeepSeek-R1 1.5B小模型
额,其实手机也能跑,跑的比1060快,搜MNN chat
另外提一嘴,deepseek-r1:1.5b和deepseek是两码事,7b也一样,性能也很差,在当时就很差,那个模型基于早期的qwen,实际性能还不如原模型。小模型可以直接玩qwen。
离线
#13 2026-04-05 21:30:33 分享评论
- IThaozi
- 会员
- 注册时间: 2024-10-11
- 已发帖子: 6
- 积分: 1
Re: 十年前的GTX1060笔记本电脑也能跑DeepSeek-R1 1.5B小模型
bearqq wrote:
额,其实手机也能跑,跑的比1060快,搜MNN chat
另外提一嘴,deepseek-r1:1.5b和deepseek是两码事,7b也一样,性能也很差,在当时就很差,那个模型基于早期的qwen,实际性能还不如原模型。小模型可以直接玩qwen。
手机这个应该算是针对手机优化的一个精简模型吧
离线
感谢为中文互联网持续输出优质内容的各位老铁们。
QQ: 516333132, 微信(wechat): whycan_cn (哇酷网/挖坑网/填坑网) service@whycan.cn
东莞哇酷科技有限公司开发
东莞哇酷科技有限公司开发