楼主 #1 2019-08-25 20:09:26 分享评论
- bunny
- 会员
- 注册时间: 2020-05-23
- 已发帖子: 154
- 积分: 154
fft又来了,这次更简单,代码才30行
static double buffer[N]; // N = 2^(k+1)
void fft(const double* src_x, const double* src_y, double* dst_x, double* dst_y, int k) {
int i, n;
double temp, temp_x, temp_y;
if (0 == k) {
*dst_x = *src_x;
*dst_y = *src_y;
return;
}
n = 1 << (k - 1);
for (i = 0; i < n; i++) {
buffer[i] = src_x[i * 2];
buffer[i + n] = src_y[i * 2];
buffer[i + 2 * n] = src_x[i * 2 + 1];
buffer[i + 3 * n] = src_y[i * 2 + 1];
}
fft((const double*)buffer + 2 * n, (const double*)buffer + 3 * n, dst_x, dst_y, k - 1);
fft((const double*)buffer, (const double*)buffer + n, (double*)buffer + 2 * n, (double*)buffer + 3 * n, k - 1);
for (i = 0; i < n; i++) {
temp = i * M_PI / n;
temp_x = cos(temp);
temp_y = sin(temp);
buffer[i] = dst_y[i] * temp_y + dst_x[i] * temp_x;
buffer[i + n] = dst_y[i] * temp_x - dst_x[i] * temp_y;
dst_x[i] = buffer[i + 2 * n] + buffer[i];
dst_y[i] = buffer[i + 3 * n] + buffer[i + n];
dst_x[i + n] = buffer[i + 2 * n] - buffer[i];
dst_y[i + n] = buffer[i + 3 * n] - buffer[i + n];
}
}函数使用说明:
void fft(const double src_x, const double src_y, double dst_x, double dst_y, int k)
src_x:输入数据实部
src_y:输入数据虚部
dst_x:输出数据实部
dst_y:输出数据虚部
k:表征fft点数为2^k,比如1024点的fft,k=10;4096点的fft,k=12;
离线
#2 2019-08-25 20:18:27 分享评论
- 超级萌新
- 会员
- 注册时间: 2018-05-04
- 已发帖子: 408
- 积分: 407
Re: fft又来了,这次更简单,代码才30行
牛叉, 递归调用, 路过学习
离线
楼主 #3 2019-08-25 21:25:31 分享评论
- bunny
- 会员
- 注册时间: 2020-05-23
- 已发帖子: 154
- 积分: 154
Re: fft又来了,这次更简单,代码才30行
超级萌新 wrote:
牛叉, 递归调用, 路过学习
不优雅的代码也不敢往晕哥的坑网里塞啊
离线
#5 2020-02-26 09:07:35 分享评论
- sea18c
- 会员
- 注册时间: 2019-08-05
- 已发帖子: 230
- 积分: 222.5
Re: fft又来了,这次更简单,代码才30行
坑网有你更精彩,谢谢大神优秀的代码
离线
#6 2020-02-26 09:14:05 分享评论
- 我心飞翔
- 会员
- 注册时间: 2019-12-25
- 已发帖子: 82
- 积分: 82
Re: fft又来了,这次更简单,代码才30行
长期和楼主混在一个QQ群,微信群, 数学牛逼得一塌糊涂。
离线
#7 2020-02-26 10:21:59 分享评论
- 小丸子
- 会员
- 注册时间: 2019-09-26
- 已发帖子: 44
- 积分: 3
Re: fft又来了,这次更简单,代码才30行
学习了学习了
离线
#8 2020-02-26 10:25:02 分享评论
- jiangchun9981
- 会员
- 注册时间: 2019-07-31
- 已发帖子: 170
- 积分: 130.5
Re: fft又来了,这次更简单,代码才30行
M_PI 是3.14159这样定义吗?
能贴个完整的工程最好,实在太菜鸟了这个
离线
#9 2020-02-26 10:53:26 分享评论
- gui401
- 会员
- 注册时间: 2019-10-25
- 已发帖子: 45
- 积分: 29.5
Re: fft又来了,这次更简单,代码才30行
效率怎样呢?个人觉得float精度足够了,旋转因子可以预先算好 这样也能减少点开销
离线
#10 2020-02-27 01:36:14 分享评论
- 854619267
- 会员
- 注册时间: 2019-06-05
- 已发帖子: 16
- 积分: 10.5
Re: fft又来了,这次更简单,代码才30行
Mark-FFT
离线
#11 2020-02-27 12:28:33 分享评论
- k455619
- 会员
- 注册时间: 2018-07-29
- 已发帖子: 151
- 积分: 70
Re: fft又来了,这次更简单,代码才30行
真的羡慕 数学高手。。。。。。。。
离线
#12 2020-03-31 10:51:56 分享评论
- flex-A
- 会员

- 注册时间: 2019-08-27
- 已发帖子: 51
- 积分: 146.5
Re: fft又来了,这次更简单,代码才30行
请问有大佬测试过这个代码吗,我自己写的的计算出来全是0
int main()
{
double x[16],y[16];
int i=0;
for(i=0;i<16;i++)
{
y[i]=0;
x[i]=0;
}
x[0]=1.0;
x[1]=1.0;
double dx[16]={0},dy[16]={0};
fft(x,y,dx,dy,4);
for (i = 0; i < 16; i++) {
printf((const char*)"dat[%d] = %f + %f * i\n", i, dx[i], dy[i]);
}
return 0;
}最近编辑记录 flex-A (2020-03-31 10:55:24)
离线
#13 2020-03-31 11:45:31 分享评论
- BugActiveDaughter
- 会员
- 注册时间: 2017-10-17
- 已发帖子: 118
- 积分: 117.5
Re: fft又来了,这次更简单,代码才30行
风骚兔
离线
楼主 #14 2020-03-31 22:57:34 分享评论
- bunny
- 会员
- 注册时间: 2020-05-23
- 已发帖子: 154
- 积分: 154
Re: fft又来了,这次更简单,代码才30行
flex-A wrote:
请问有大佬测试过这个代码吗,我自己写的的计算出来全是0
int main() { double x[16],y[16]; int i=0; for(i=0;i<16;i++) { y[i]=0; x[i]=0; } x[0]=1.0; x[1]=1.0; double dx[16]={0},dy[16]={0}; fft(x,y,dx,dy,4); for (i = 0; i < 16; i++) { printf((const char*)"dat[%d] = %f + %f * i\n", i, dx[i], dy[i]); } return 0; }
你的测试是没问题的,是我代码的疏漏,出现了内存区域的覆盖,第一版本中使用malloc free,没有这个问题,后来改成静态内存的时候逻辑没理顺,出现的内存覆盖的BUG,由于未经严格测试,没有发现这个BUG,经你提醒才抓出来
上传最早的版本(引用了malloc free函数)
void fft(const double* src_x, const double* src_y, double* dst_x, double* dst_y, int k) {
int i, n;
double temp, temp_x, temp_y;
double* buffer;
if (0 == k) {
*dst_x = *src_x;
*dst_y = *src_y;
return;
}
n = 1 << (k - 1);
buffer = (double*)malloc(4 * n * sizeof(double));
for (i = 0; i < n; i++) {
buffer[i] = src_x[i * 2];
buffer[i + n] = src_y[i * 2];
buffer[i + 2 * n] = src_x[i * 2 + 1];
buffer[i + 3 * n] = src_y[i * 2 + 1];
}
fft((const double*)buffer + 2 * n, (const double*)buffer + 3 * n, dst_x, dst_y, k - 1);
fft((const double*)buffer, (const double*)buffer + n, (double*)buffer + 2 * n, (double*)buffer + 3 * n, k - 1);
for (i = 0; i < n; i++) {
temp = i * M_PI / n;
temp_x = cos(temp);
temp_y = sin(temp);
buffer[i] = dst_y[i] * temp_y + dst_x[i] * temp_x;
buffer[i + n] = dst_y[i] * temp_x - dst_x[i] * temp_y;
dst_x[i] = buffer[i + 2 * n] + buffer[i];
dst_y[i] = buffer[i + 3 * n] + buffer[i + n];
dst_x[i + n] = buffer[i + 2 * n] - buffer[i];
dst_y[i + n] = buffer[i + 3 * n] - buffer[i + n];
}
free(buffer);
}离线
楼主 #15 2020-03-31 23:04:42 分享评论
- bunny
- 会员
- 注册时间: 2020-05-23
- 已发帖子: 154
- 积分: 154
Re: fft又来了,这次更简单,代码才30行
更新的fft函数测试截图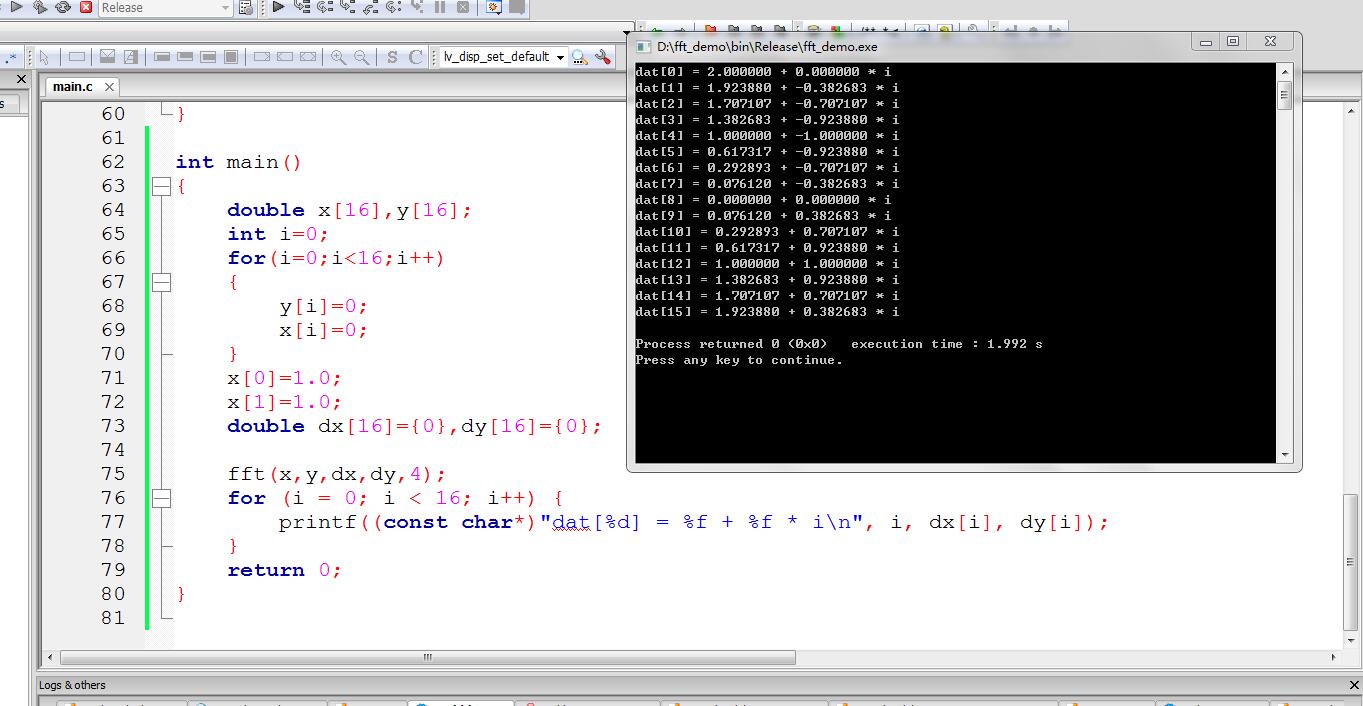
离线
#16 2020-04-03 10:16:37 分享评论
- flex-A
- 会员
- 注册时间: 2019-08-27
- 已发帖子: 51
- 积分: 146.5
Re: fft又来了,这次更简单,代码才30行
可以了,多谢大佬:D
离线
楼主 #17 2020-04-03 10:18:25 分享评论
- bunny
- 会员
- 注册时间: 2020-05-23
- 已发帖子: 154
- 积分: 154
Re: fft又来了,这次更简单,代码才30行
flex-A wrote:
可以了,多谢大佬:D
也谢谢你帮我抓BUG
离线
#18 2020-05-03 19:32:39 分享评论
- jiangshan00000
- 会员
- 注册时间: 2019-12-05
- 已发帖子: 10
- 积分: 0
Re: fft又来了,这次更简单,代码才30行
是fft么,怎么感觉计算挺复杂的?
离线
#19 2026-05-10 17:26:07 分享评论
- dykxjh
- 会员
- 注册时间: 2020-03-25
- 已发帖子: 190
- 积分: 150
Re: fft又来了,这次更简单,代码才30行
怎么全是浮点运算呢,整形更常用
离线
东莞哇酷科技有限公司开发