楼主 # 2021-06-22 17:36:56 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 362
- 积分: 367.5
RISC-V代码密度相比Cortex-M差距明显
自己的Xboot工程,在ARM的M0/M3/M4/M23/M33平台下面,全部可以在7kB闪存以内实现,几个架构差异不大,7kB闪存普遍剩余一两百个字节。
最近把它移植到RISC-V上,芯片型号GD32VF103CBT6,同样的一套代码,使用gcc编译,-Os面积优化,固件尺寸11520字节。超过11kB了,速度优化代码尺寸超过16kB。
ARM算7kB,两者对比,7*1024/11520*100%=62.2%,也就是说,同样的功能,Cortex-M只需要RISC-V六成多一点的代码就能实现。
当然还有一个变量要考虑,ARM使用AC6编译,RISC-V使用gcc编译,编译器的效率也会有一定差异。
调试方面RISC-V只能用JTAG(GDLink可以支持),相比之下Cortex-M的SWD调试用起来更方便一些。
至此GD32家的M3/M4/M23/M33/RISC-V五种核心全部盘完了。
离线
#1 2021-06-22 17:45:09 分享评论
- cube
- 会员
- 注册时间: 2021-03-11
- 已发帖子: 288
- 积分: 202.5
Re: RISC-V代码密度相比Cortex-M差距明显
压缩指令选项应该开了吧?RISCV指令精简程度比ARM更高,大一点也不奇怪。
离线
#2 2021-06-22 18:06:04 分享评论
- kekemuyu
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 853
- 积分: 694
Re: RISC-V代码密度相比Cortex-M差距明显
这样比没有用的,编译器的因素影响太大。都用汇编还好点,不过理论上thum2的代码密度确实比riscv的精简指令要高。
最近编辑记录 kekemuyu (2021-06-22 18:07:49)
离线
楼主 #3 2021-06-22 19:59:40 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 362
- 积分: 367.5
Re: RISC-V代码密度相比Cortex-M差距明显
差了近40%,这个差距十分明显了,同样核心芯片都是按照FLASH容量定价格的,核心省下来的授权费说不定还不够买多用的FLASH。
还是Cortex-M香。
离线
楼主 #4 2021-06-22 20:00:51 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 362
- 积分: 367.5
Re: RISC-V代码密度相比Cortex-M差距明显
压缩指令选项应该开了吧?RISCV指令精简程度比ARM更高,大一点也不奇怪。
差了近40%,不是不能算是“一点”了。10%以内的话还可以接受。
离线
楼主 #5 2021-06-22 20:02:20 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 362
- 积分: 367.5
Re: RISC-V代码密度相比Cortex-M差距明显
这样比没有用的,编译器的因素影响太大。都用汇编还好点,不过理论上thum2的代码密度确实比riscv的精简指令要高。
RISC-V目前除了GCC还有其它编译器支持吗?
离线
#6 2021-06-22 20:05:22 分享评论
- cube
- 会员
- 注册时间: 2021-03-11
- 已发帖子: 288
- 积分: 202.5
Re: RISC-V代码密度相比Cortex-M差距明显
kekemuyu 说:这样比没有用的,编译器的因素影响太大。都用汇编还好点,不过理论上thum2的代码密度确实比riscv的精简指令要高。
RISC-V目前除了GCC还有其它编译器支持吗?
据说IAR支持了。
离线
楼主 #7 2021-06-22 20:19:32 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 362
- 积分: 367.5
Re: RISC-V代码密度相比Cortex-M差距明显
echo 说:kekemuyu 说:这样比没有用的,编译器的因素影响太大。都用汇编还好点,不过理论上thum2的代码密度确实比riscv的精简指令要高。
RISC-V目前除了GCC还有其它编译器支持吗?
据说IAR支持了。
https://www.iar.com/products/architectures/risc-v/iar-embedded-workbench-for-risc-v/
In current version of the toolchain, code density is already small comparing to other available tools
看来代码密度确实是RISC-V的大问题,IAR这里 other available tools 指的应该就是GCC。
离线
#8 2021-07-11 00:09:15 分享评论
- 3DA502
- 会员
- 注册时间: 2018-08-18
- 已发帖子: 18
- 积分: 12.5
Re: RISC-V代码密度相比Cortex-M差距明显
标准版的rv32imac指令集比arm差的比较多。简单的例子,没有地址自增指令
arm在漫长的历史上,吸收了一些复杂指令集的骚操作,例如ldm 加载多个寄存器
以后,riscv指令集会有很多魔改扩展出现的,riscv已经预留了魔改的空间
离线
#9 2021-07-16 15:38:27 分享评论
- xiaohui
- 会员

- 注册时间: 2019-01-15
- 已发帖子: 259
- 积分: 122.5
Re: RISC-V代码密度相比Cortex-M差距明显
之前看到有大佬讨论说,gcc编译risc-v的代码的时候负优化挺严重的,关掉优化可能会有意想不到的效果
离线
#10 2021-08-04 16:31:27 分享评论
- Xiagb
- 会员
- 注册时间: 2020-03-29
- 已发帖子: 22
- 积分: 36
Re: RISC-V代码密度相比Cortex-M差距明显
沁恒的riscv ch573支持swd,不过用的是他们自己的WCHLink
离线
#11 2021-08-04 17:45:39 分享评论
- XIVN1987
- 会员
- 注册时间: 2019-08-30
- 已发帖子: 266
- 积分: 327.5
Re: RISC-V代码密度相比Cortex-M差距明显
这篇文章说用Segger的库和连接器可以大幅减小代码,,楼主可以试下
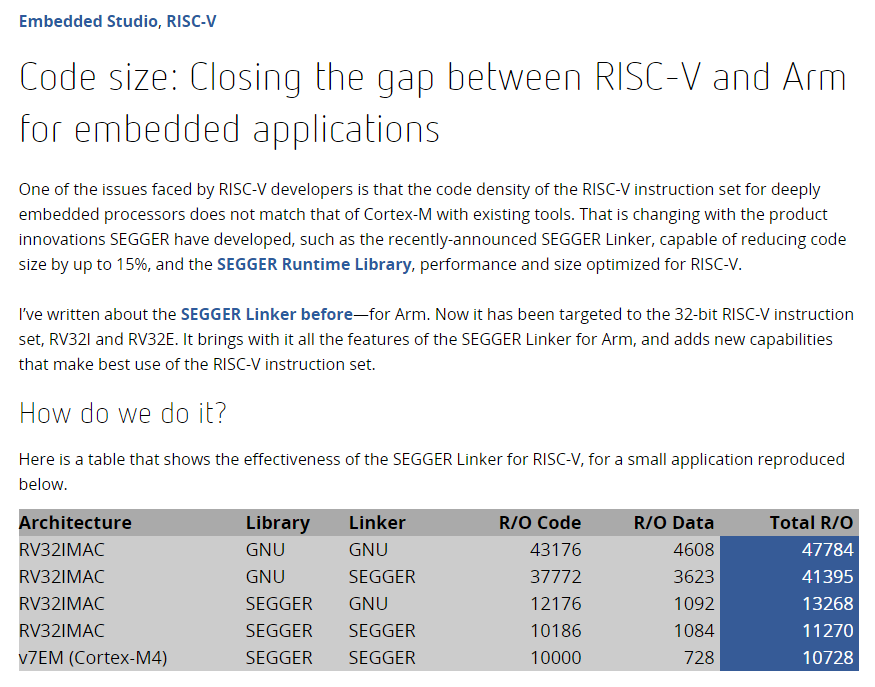
https://blog.segger.com/code-size-closing-the-gap-between-risc-v-and-arm-for-embedded-applications/
离线
楼主 #12 2021-08-05 22:16:54 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 362
- 积分: 367.5
Re: RISC-V代码密度相比Cortex-M差距明显
从这个结果来看,GCC实在是太拉胯了。感觉SEGGER在黑GCC。
最近编辑记录 echo (2021-08-05 23:49:25)
离线
#13 2021-10-30 19:56:52 分享评论
- alexyzhov
- 会员
- 注册时间: 2018-09-04
- 已发帖子: 2
- 积分: 3
Re: RISC-V代码密度相比Cortex-M差距明显
提一点,GCC的rw段在binary里是不压缩的,启动时做全量拷贝。Keil的话,无论compiler V5还是V6,都会压缩rw段,__main函数里会调__decompress做解压,IAR/Segger/Green Hill/Ti的工具链也会做类似优化。考虑到多数全局变量只需要做部分初始化(比如一个大描述符中的个别初始化字段),rw段里是有非常多的zeros可以被优化掉的。如果固件里的rw segment size不小,工具链不做压缩带来的size overhead会非常多。楼主可以在AC5/AC6的link flag里添加 --datacompressor off 再和GCC固件比对下体积。
我做过调研,根据rw段的实际使用情况,仅使用zero-rle压缩就可以做到7%~20%的压缩比。
也就是说,假设rw segment有10K,做rw压缩可以减少固件7~9K的size。对mcu firmware来说,这个收益是相当可观的。
GCC Toolchain没有集成rw压缩功能,但是可以插postbuild流程,结合重写的startup load code手动实现。
最近编辑记录 alexyzhov (2021-10-30 20:44:21)
离线
#14 2022-10-07 12:09:42 分享评论
- Copper
- 会员

- 注册时间: 2021-12-29
- 已发帖子: 31
- 积分: 61
Re: RISC-V代码密度相比Cortex-M差距明显
@echo
编译时候的目标risc-v指令集具体有哪些模块?
离线
楼主 #15 2022-10-10 22:29:21 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 362
- 积分: 367.5
Re: RISC-V代码密度相比Cortex-M差距明显
目前使用gcc 8.2.0,打开-flto选项可以大大减小代码体积,不过代码行为似乎不太正常,会有莫名其貌的问题。
离线
#16 2022-10-11 09:41:43 分享评论
- liyucai
- 会员
- 注册时间: 2019-12-06
- 已发帖子: 57
- 积分: 34
Re: RISC-V代码密度相比Cortex-M差距明显
ARM 也用 gcc 来编译,这样比较才有意义。
离线
楼主 #17 2022-10-11 14:40:04 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 362
- 积分: 367.5
Re: RISC-V代码密度相比Cortex-M差距明显
ARM 也用 gcc 来编译,这样比较才有意义。
这样没意义,好比两军交战,甲方坦克飞机大炮,乙方方砍刀长矛盾牌,乙方输了说你们甲方也要用砍刀长矛盾牌才有意义。乙方不是不想用坦克飞机大炮,是没有。
离线

#19 2024-05-18 10:38:19 分享评论
- aquasnake
- 会员
- 注册时间: 2024-01-09
- 已发帖子: 111
- 积分: 513
Re: RISC-V代码密度相比Cortex-M差距明显
为什么我对risc v不感冒?我宁愿用cortex m系列,早就知道这个问题了,对于代码的空间效率问题,国内一众的risc v架构,再过15年都追不上现在arm的效率
最近编辑记录 aquasnake (2024-05-18 10:38:35)
离线
#20 2024-05-18 10:45:22 分享评论
- aquasnake
- 会员
- 注册时间: 2024-01-09
- 已发帖子: 111
- 积分: 513
Re: RISC-V代码密度相比Cortex-M差距明显
很多人觉得用国产的基于risc v某某32应该很容易替换掉stm32,其实对于学院派来说可以,但是对于对cost追求刀刀见血的商业化方案公司,未必能代替。单一看芯片价格不足以评估成本,要从整个bom看。
所以我还是觉得做risc v的国内芯片设计公司,你们应该把片上flash配置到2倍stm32的程度
离线
#21 2024-05-18 13:15:10 分享评论
- kekemuyu
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 853
- 积分: 694
Re: RISC-V代码密度相比Cortex-M差距明显
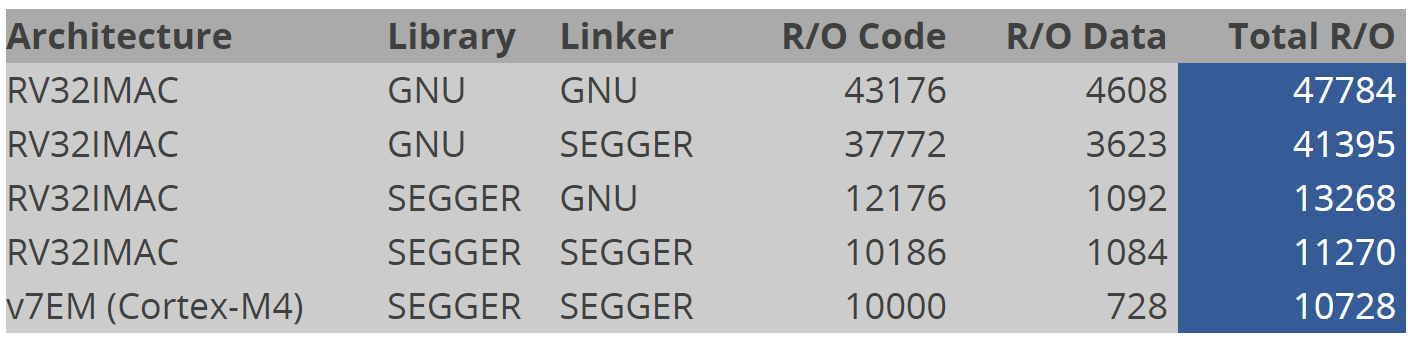
离线
#22 2024-05-19 23:48:24 分享评论
- haohop
- 会员
- 注册时间: 2023-05-28
- 已发帖子: 4
- 积分: 4
Re: RISC-V代码密度相比Cortex-M差距明显
这个才有说服力,之前看过用Segger和AC6编译对比,好像AC6效率更高
离线
#23 2024-05-20 10:17:28 分享评论
- 老发
- 会员
- 注册时间: 2018-03-15
- 已发帖子: 31
- 积分: 31
Re: RISC-V代码密度相比Cortex-M差距明显
从这个结果来看,就是编译器对arm优化得比较到位,对riscv还有较大的优化空间而已。
离线
#24 2024-05-20 11:58:43 分享评论
Re: RISC-V代码密度相比Cortex-M差距明显
这个测试其实有问题,测试代码全部是调用math.h库函数。而不同编译器所用库是不同的,即本质上各个测试用例的测试代码并不全部相同。
最近编辑记录 海石生风 (2024-05-20 12:00:43)
离线
#25 2024-05-20 13:28:37 分享评论
- aquasnake
- 会员
- 注册时间: 2024-01-09
- 已发帖子: 111
- 积分: 513
Re: RISC-V代码密度相比Cortex-M差距明显
不光编译器,还有toolchain和sdk的差异,不说链接库了,不同的库实现同样功能产生的代码不同,例如有的库自带log信息,有的库没有stack check,不带trace log,可以最大化提升空间效率
最近编辑记录 aquasnake (2024-05-20 13:29:02)
离线
#26 2024-05-20 13:31:08 分享评论
- aquasnake
- 会员
- 注册时间: 2024-01-09
- 已发帖子: 111
- 积分: 513
Re: RISC-V代码密度相比Cortex-M差距明显
更有部分sdk使用了压缩存储,把RO的data压缩,运行的时候临时加载到RAM
离线
#27 2024-05-20 19:28:38 分享评论
- nongxiaoming
- 会员
- 注册时间: 2019-12-23
- 已发帖子: 15
- 积分: 4
Re: RISC-V代码密度相比Cortex-M差距明显
你得用相同编译器相同的c库编译链接对比啊,你这样不是耍流氓吗?这样子指令集根本就不会背锅的。比如说,你买了两辆车,然后直接对比油耗,结果A车比B车耗油了不少,结果你的结论是A车的发动机太耗油了,A车发动机不行。这完全就没有说服力。
离线
楼主 #28 2024-05-21 10:35:35 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 362
- 积分: 367.5
Re: RISC-V代码密度相比Cortex-M差距明显
@nongxiaoming
RISC-V有AC6编译器吗?编译器是指令集和芯片的重要组成部分,没有编译器支持,MCU芯片就是块废铁。
离线
楼主 #29 2024-05-21 10:36:41 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 362
- 积分: 367.5
Re: RISC-V代码密度相比Cortex-M差距明显
不光编译器,还有toolchain和sdk的差异,不说链接库了,不同的库实现同样功能产生的代码不同,例如有的库自带log信息,有的库没有stack check,不带trace log,可以最大化提升空间效率
RISC-V和Cortex-M目前的差距是全方面的,当然只要RISC-V的芯片够便宜,我还是会选RISC-V芯片。
离线
#31 2024-05-22 14:13:02 分享评论
- aquasnake
- 会员
- 注册时间: 2024-01-09
- 已发帖子: 111
- 积分: 513
Re: RISC-V代码密度相比Cortex-M差距明显
不同链接库,无法同日而语.
当然,库本身精简一下是可以压出很多空间来的,有些库可以裁减
最近编辑记录 aquasnake (2024-05-22 14:15:28)
离线
#32 2024-05-23 17:27:08 分享评论
Re: RISC-V代码密度相比Cortex-M差距明显
参照上面SEGGER那个非常有问题的测试对比文章,我用Zig写了类似的测试源码,其中两个测试结果:
$ zig build size --release -Dtarget=arm-freestanding-gnueabi -Dcpu=cortex_m23
text data bss dec hex filename
28828 16 0 28844 70ac /home/chenss/workspace/zig/code_size/zig-out/bin/code_size$ zig build size --release -Dtarget=riscv32-freestanding-gnueabi -Dcpu=sifive_e34
text data bss dec hex filename
31326 232 0 31558 7b46 /home/chenss/workspace/zig/code_size/zig-out/bin/code_size跑了多个测试发现RISC-V跟ARM的代码密码其实差不多(Zig对RISC-V32的支持要弱于ARM32)
详情参见这里:https://gitee.com/ufbycd/code_size
离线
#33 2024-12-08 20:54:23 分享评论
- Copper
- 会员
- 注册时间: 2021-12-29
- 已发帖子: 31
- 积分: 61
Re: RISC-V代码密度相比Cortex-M差距明显
这张图放映的实际上是编译器和链接器之间,对不同指令集优化的巨大差异。
离线
#34 2024-12-23 18:57:51 分享评论
- lcfmax
- 会员
- 注册时间: 2018-04-13
- 已发帖子: 329
- 积分: 272.5
Re: RISC-V代码密度相比Cortex-M差距明显
ARM 用GCC编译器编译出来的尺寸,也是比AC6大很多的。在AC6上面 27KB,但是GCC上面,63KB。所以GCC编译器也是很大原因。
离线