楼主 # 2021-12-03 09:02:29 分享评论
- xboot
- 会员
- 注册时间: 2019-10-15
- 已发帖子: 725
- 积分: 458
开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
嵌入式开发中,2D图形渲染是永远绕不过去的问题,传统的绘图,都是丑的要命,灵活性很低。高质量渲染除了大型图形库,小型系统基本无缘。
这里开源一个6000行的2D高质量矢量图形库,你没看错,就是6000行,2个C文件,核心部分是扣的freetype实现,原理就是利用freetype的软渲,来实现灵活的2D矢量渲染。
API接口模仿cairo,基本cairo的demo,拿来就跑,行为基本一致。
https://github.com/xboot/libcg
最近编辑记录 xboot (2021-12-03 09:03:27)
离线
楼主 #1 2021-12-03 09:06:16 分享评论
- xboot
- 会员
- 注册时间: 2019-10-15
- 已发帖子: 725
- 积分: 458
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。













离线
#2 2021-12-03 09:32:32 分享评论
- 夏雨夜寐
- 会员

- 注册时间: 2019-08-23
- 已发帖子: 85
- 积分: 74.5
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
6了6了,大佬就是大佬
离线
#3 2021-12-03 09:44:41 分享评论
- lyon1998
- Moderator
- 注册时间: 2021-12-01
- 已发帖子: 146
- 积分: 155
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
赞!github已星
离线
#4 2021-12-03 12:25:06 分享评论
- novice
- 会员
- 注册时间: 2019-07-26
- 已发帖子: 126
- 积分: 107
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
坐标如果是整数就完美了,double类型的坐标数值对于那些没有硬件浮点数的MCU来说是不小的负担。
离线
#5 2021-12-03 17:00:22 分享评论
- novice
- 会员
- 注册时间: 2019-07-26
- 已发帖子: 126
- 积分: 107
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
今日特意测试了一下这份代码,把它移植到了VC++上面跑了一下。
代码大致没有什么问题,但是建议考虑一下不同编译器之间的兼容性。
移植到VC上时为了方便把库代码改成了CPP后缀,并且改动了一些地方。
1、改成CPP是因为函数内变量声明位置比较随意,标准C不通过。
2、cg_array_ensure由宏改成了模板函数,因为VC++里面malloc需要强制转换。
3、min/max宏改了。
4、SW_FT_MSB用VC++的intrinsic改写了。
5、库代码当中所有malloc的地方加了强制类型转换。

最近编辑记录 novice (2021-12-03 17:33:46)
离线
#6 2021-12-03 17:33:54 分享评论
- jiaowoxiaolu
- 会员
- 注册时间: 2021-08-27
- 已发帖子: 50
- 积分: 66
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
大佬牛逼了
离线
#7 2021-12-03 23:34:01 分享评论
- sblpp
- 会员
- 注册时间: 2018-02-14
- 已发帖子: 165
- 积分: 40
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
这个大大的赞~~~
离线
楼主 #8 2021-12-04 09:08:04 分享评论
- xboot
- 会员
- 注册时间: 2019-10-15
- 已发帖子: 725
- 积分: 458
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
@novice
很不错,镜像才64KB,够小,简单看了下代码,有个地方需要注意下,因为多种测试用例用的同一个cg_ctx_t,而这个上下文在不同测试项里,某些属性是会变化的,而这些属性并没有恢复,所以渲染时会出现跟标准demo表现不一致的现象,最简单的处理方法,就是所有测试用例加上cg_save()和cg_restore(),就可以规避这个问题。
离线
楼主 #9 2021-12-04 11:06:54 分享评论
- xboot
- 会员
- 注册时间: 2019-10-15
- 已发帖子: 725
- 积分: 458
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
修改了一处libcg与cairo行为不一致的地方,就是默认miter limit,cairo默认是10,而libcg默认是4,打个补丁就可以修复此问题,修改后fill_and_stroke这个测试用例的渲染效果就跟cairo完全一致了,还发现了一些其他行为不一致的现象,比如点划线的偏移参数为负时,fill_style测试用例,gradient测试用例,这些表现都跟cairo不一致,这些都需要慢慢修复。
diff --git a/cg.c b/cg.c
index 8e39f2c..cbb6ddf 100644
--- a/cg.c
+++ b/cg.c
@@ -2297,7 +2297,7 @@ static struct cg_state_t * cg_state_create(void)
cg_matrix_init_identity(&state->matrix);
state->winding = XVG_FILL_RULE_WINDING;
state->stroke.width = 1.0;
- state->stroke.miterlimit = 4.0;
+ state->stroke.miterlimit = 10.0;
state->stroke.cap = XVG_LINE_CAP_BUTT;
state->stroke.join = XVG_LINE_JOIN_MITER;
state->stroke.dash = NULL;离线
#10 2021-12-04 12:29:57 分享评论
- novice
- 会员
- 注册时间: 2019-07-26
- 已发帖子: 126
- 积分: 107
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
@xboot
为大佬点赞!
离线
楼主 #11 2021-12-04 19:59:07 分享评论
- xboot
- 会员
- 注册时间: 2019-10-15
- 已发帖子: 725
- 积分: 458
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。

不可能做到完全一致,具体接口上,还是有些差异的,毕竟如此精简了,也不能要求太多。
增加了一些测试demo,图片裁剪,旋转缩放,拼图等相关测试用例
最近编辑记录 xboot (2021-12-04 20:00:36)
离线
#12 2021-12-04 22:52:05 分享评论
- armstrong
- 会员

- 注册时间: 2019-04-10
- 已发帖子: 295
- 积分: 189.5
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
xboot大佬出品都是精品!
离线
楼主 #13 2021-12-07 12:17:06 分享评论
- xboot
- 会员
- 注册时间: 2019-10-15
- 已发帖子: 725
- 积分: 458
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
增加9个硬件加速接口,方便用汇编代码来优化渲染效率。
void cg_memfill32(uint32_t * dst, uint32_t val, int len);
void cg_comp_solid_source(uint32_t * dst, int len, uint32_t color, uint32_t alpha);
void cg_comp_solid_source_over(uint32_t * dst, int len, uint32_t color, uint32_t alpha);
void cg_comp_solid_destination_in(uint32_t * dst, int len, uint32_t color, uint32_t alpha);
void cg_comp_solid_destination_out(uint32_t * dst, int len, uint32_t color, uint32_t alpha);
void cg_comp_source(uint32_t * dst, int len, uint32_t * src, uint32_t alpha);
void cg_comp_source_over(uint32_t * dst, int len, uint32_t * src, uint32_t alpha);
void cg_comp_destination_in(uint32_t * dst, int len, uint32_t * src, uint32_t alpha);
void cg_comp_destination_out(uint32_t * dst, int len, uint32_t * src, uint32_t alpha);离线
楼主 #14 2021-12-07 19:17:49 分享评论
- xboot
- 会员
- 注册时间: 2019-10-15
- 已发帖子: 725
- 积分: 458
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
libcg性能测试,纯C版,未启用任何汇编加速。
cairo默认配置,采用pixman做底层加速。
xvg为xboot的候补渲染接口实现,全部贝塞尔化,效率较低。
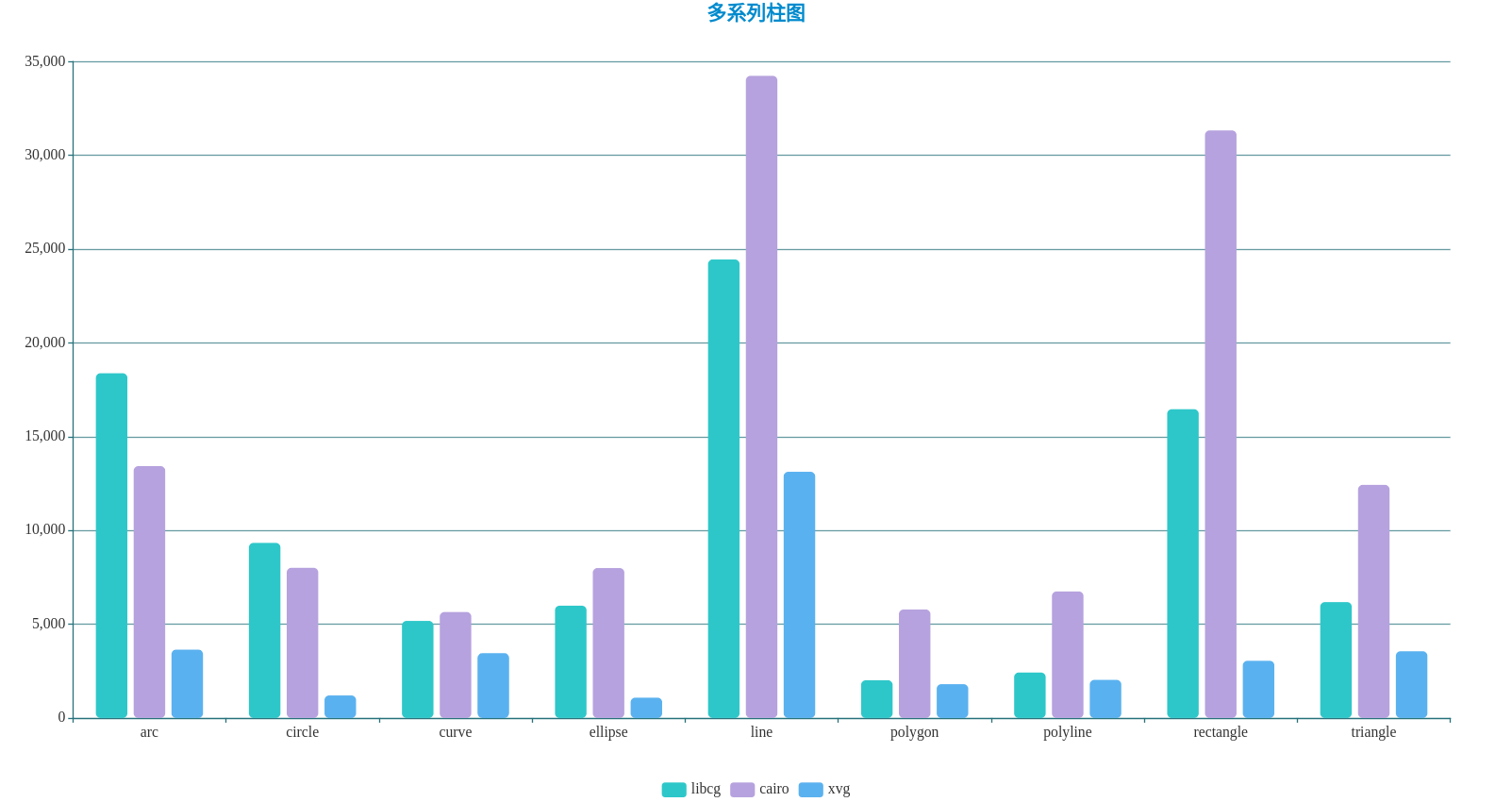
详情见这个链接。
https://www.tubiaoxiu.com/p.html?s=1f5dd669953369e8&isChart=true
最近编辑记录 xboot (2021-12-07 19:22:42)
离线
楼主 #15 2021-12-09 11:11:58 分享评论
- xboot
- 会员
- 注册时间: 2019-10-15
- 已发帖子: 725
- 积分: 458
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
上面为X86平台上的测试结果,下面为F133裸奔测试结果。
可以看到,相对关系还是比较稳定的,跟平台关系不大,cairo的整体表现还是略胜一筹。
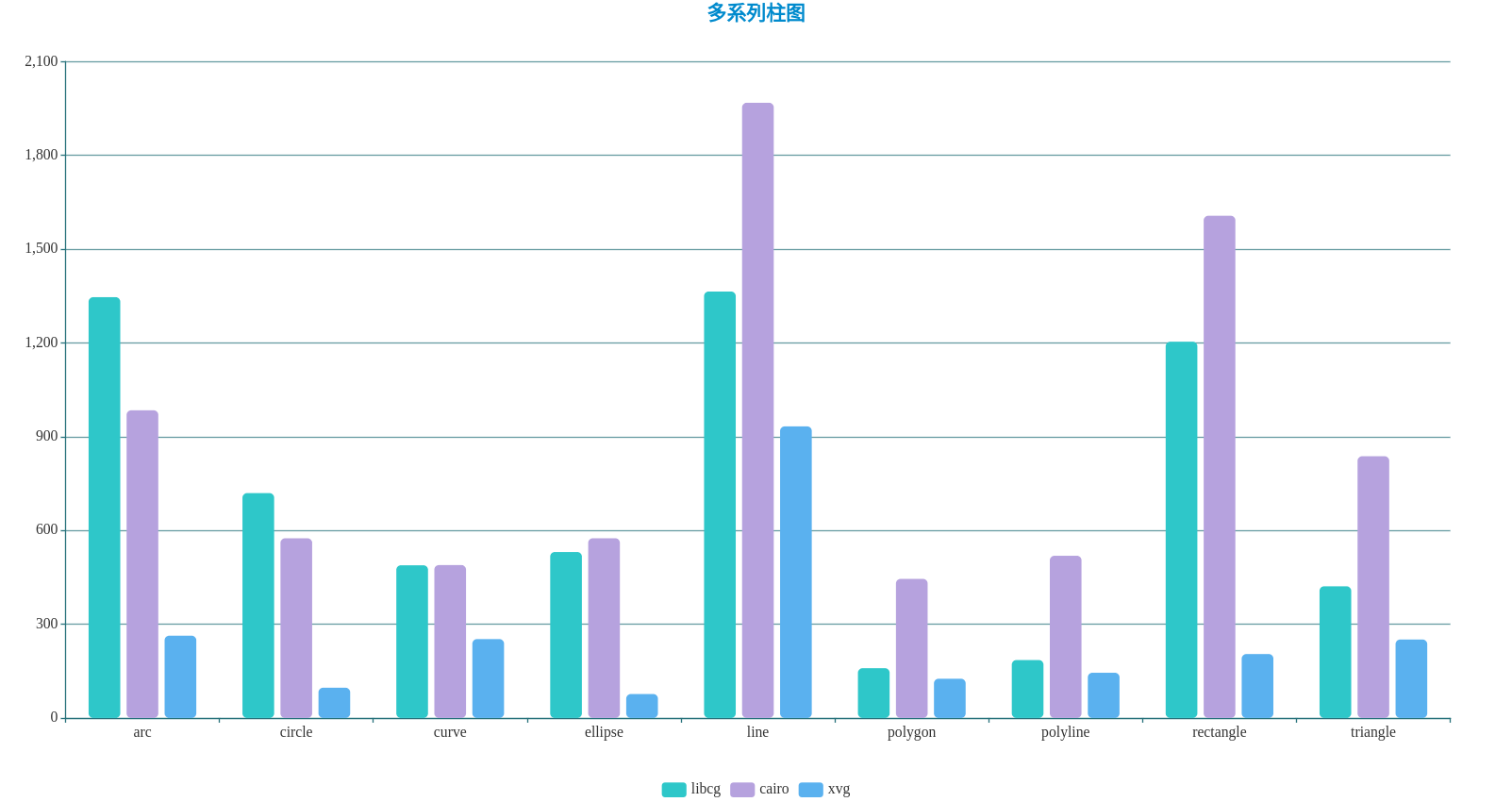
https://www.tubiaoxiu.com/p.html?s=8a307d36a77ae6fd&isChart=true
由这两个图互相对比,也能发现一个相对性指标,F133跟X86平台性能相差巨大,平均下来大概有个10几倍的性能差距,一个数量级了,RISCV任重道远。
离线
#16 2021-12-09 13:26:03 分享评论
- 吴助建
- 会员
- 注册时间: 2021-12-08
- 已发帖子: 116
- 积分: 19
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
离线
- 不通过:其他
#17 2022-02-09 10:14:04 分享评论
- mengxp
- 会员
- 注册时间: 2021-10-07
- 已发帖子: 68
- 积分: 152
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
程序本身就使用了freetype的情况下那个 swft是不是就可以不要了,移植一下cg使用freetype的内部函数?
离线
楼主 #18 2022-02-09 14:39:15 分享评论
- xboot
- 会员
- 注册时间: 2019-10-15
- 已发帖子: 725
- 积分: 458
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
直接用freetype的内部函数,几乎没有可行性,现在的freetype没那么灵活,需要修改freetype的代码,想直接用内部函数,几乎不可行。
离线
#19 2022-03-04 21:32:24 分享评论
- dykxjh
- 会员
- 注册时间: 2020-03-25
- 已发帖子: 192
- 积分: 152
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
@xboot
void cg_memfill32(uint32_t * dst, uint32_t val, int len);
void cg_comp_solid_source(uint32_t * dst, int len, uint32_t color, uint32_t alpha);
void cg_comp_solid_source_over(uint32_t * dst, int len, uint32_t color, uint32_t alpha);
void cg_comp_solid_destination_in(uint32_t * dst, int len, uint32_t color, uint32_t alpha);
void cg_comp_solid_destination_out(uint32_t * dst, int len, uint32_t color, uint32_t alpha);
void cg_comp_source(uint32_t dst, int len, uint32_t src, uint32_t alpha);
void cg_comp_source_over(uint32_t dst, int len, uint32_t src, uint32_t alpha);
void cg_comp_destination_in(uint32_t dst, int len, uint32_t src, uint32_t alpha);
void cg_comp_destination_out(uint32_t dst, int len, uint32_t src, uint32_t alpha);
以上9个用例,我全部重写了,但是测试完所有例程,却只调用到3个,分别是:
cg_memfill32
cg_comp_solid_source_over
cg_comp_source_over
不知道剩下的那些怎么样才能用到。
离线
楼主 #20 2022-03-05 13:31:29 分享评论
- xboot
- 会员
- 注册时间: 2019-10-15
- 已发帖子: 725
- 积分: 458
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
void cg_set_operator(struct cg_ctx_t * ctx, enum cg_operator_t op);enum cg_operator_t {
CG_OPERATOR_SRC = 0, /* r = s * ca + d * cia */
CG_OPERATOR_SRC_OVER = 1, /* r = (s + d * sia) * ca + d * cia */
CG_OPERATOR_DST_IN = 2, /* r = d * sa * ca + d * cia */
CG_OPERATOR_DST_OUT = 3, /* r = d * sia * ca + d * cia */
};调用cg_set_operator可以设定合成模式,测试用例没有覆盖所有模式。
离线
#22 2022-09-23 13:52:59 分享评论
- arcj
- 会员
- 注册时间: 2022-01-10
- 已发帖子: 3
- 积分: 3
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
牛逼,以前我也是自己撸过类似的,除了划线,polygon,不规则渐变填充外,都写完,但效率不太行
离线
#23 2023-02-06 14:30:13 分享评论
- wkhfb838985
- 会员
- 注册时间: 2023-02-06
- 已发帖子: 2
- 积分: 2
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
图形质量非常好
离线
#24 2023-02-06 16:24:54 分享评论
- dykxjh
- 会员
- 注册时间: 2020-03-25
- 已发帖子: 192
- 积分: 152
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
缺点是全浮点运算。如果改成定点数运算就完美了。
离线
#25 2023-04-04 22:07:12 分享评论
- Amias
- 会员
- 注册时间: 2023-04-04
- 已发帖子: 1
- 积分: 1
Re: 开源一个6000行的2D矢量图形库libcg,零依赖,API接口类似cairo,在某些场景可以代替cairo,特别适合裸奔场景。
感觉和plutovg有点像,但确实好用。希望能添加对fix16的支持
离线
东莞哇酷科技有限公司开发