- 首页
- » 上海航芯
- » 大家一起来研究ACM32F4芯片
楼主 # 2022-07-09 11:55:36 分享评论
- shaoxi2010
- 会员
- 注册时间: 2019-06-13
- 已发帖子: 400
- 积分: 339
大家一起来研究ACM32F4芯片
最近在尝试ACM32F4遇到两个头大的问题,航芯的FAE估计不对个人服务,没通过只好靠自己尝试解决下。
CMSIS的pack内的SVD文件不带寄存器位描述,rust包无法获取到位级别,欢迎大家一起补充。
解决方案:使用svdtools对官方文件进行描述补丁,在使用svd2rust进行解析。
项目地址: https://github.com/shaoxi2010/acm32f4
点灯项目: https://github.com/shaoxi2010/acm32f4-rs
更新了基本库使用和ICACHE的反编译代码。ACM32F4在文档内提到一个非常有意思的东西L1Cache,之前接触到的Cache都是在有MMU环境下,这个
不带MMU环境的Cache还是第一次见,故对其产生了研究兴趣,因为手册上没有任何地方提及到cache使用,
但在其accelerate.a中观察到其实现。
首先是当前能获取到信息:L1Cache位于Bus matrix之上,也就是C-AHB连接到ICache,S-AHB连接到了DCache
AHB1 和 AHB2 的时钟频率一致且等于系统频率,且处理器可以以 180MHz 的系统频率无等待地访问 SRAM。
并未提及eFlash和SRAM有相同访问周期,故可能有延迟。
从库函数解析上看,也实现了clean、invalid方法,但是在enable时没看到DCache的逻辑。
根据上述信息可以得出几个推论:同周期访问SRAM不就是Cache的功能么,那么DCache应该不需要连接到SRAM,大概率是外部内存。
当然我也没看到哪里支持外部内存,可能是为后续产品实现准备的。不知道DCache实现了标记内存为写透还是缓存的模型,按照现有给出来的数据,SRAM等外设进行cache
感觉就是画蛇添足。感觉大概率也是外部存储区域会使用Cache,其他都不用来减少编码复杂度,期待FAE
解答下。ICache部分看上去只能与ROM和eFlash相连了,这部分的Cache应能提高程序执行性能,并且并不会影响
到代码的复杂度,感觉就ACM32F4目前状态而言,打开ICache将优化指令访问性能,提高执行效率。根据前面的推导和猜测可以大致猜想到,ACM32F4的cache模型应该与stm32l5的模型非常近似,可能这就是
对标产品。不确定仅猜测,附上stm32l5对L1Cache的解释说明。
an5212-using-stm32-cache-to-optimize-performance-and-power-efficiency-stmicroelectronics.pdf
所有时钟保持下载默认状态下,不开启ICache下执行eFlash Checksum时间约10s,打开ICache后提升到约4s。
证明ICache对eFlash的程序访问提升还是相当明显的。项目工程就是点灯工程。
测试日志如下:
11:43:54.997 checksum code without cache :start
11:44:04.945 checksum code without cache:end 517fa2f0
11:44:04.945 checksum code with cache :start
11:44:08.556 checksum code with cache:end 517fa2f0
11:44:09.058 blink led!目前发现程序断电后,直接插入后执行时常和效率完全不匹配明显慢了很多,估计是时钟源变了,需要继续分析下。
离线

楼主 #3 2022-07-10 12:22:42 分享评论
- shaoxi2010
- 会员
- 注册时间: 2019-06-13
- 已发帖子: 400
- 积分: 339
Re: 大家一起来研究ACM32F4芯片
@海石生风
提升慢速IO的方法用cache是没错的,因为一般SOC设计下会出现片内SRAM并非与高速总线连接的现象。
在A64做裸机内存测试就发现,其片内SRAM连接的是AHB1的总线上IO性能也低到离谱。但是同样在不开启
MMU环境下在DDR上测试反而还好些。在此时如果在打开cache,两者差距其实并不明显,确实也能说明
都是由于低速IO引起。。
AXI本身就是低延迟高带宽的片内总线,它的访问速度应该是略慢于cpu的cache访问的,但是这个针对的是
高性能CPU本身而言,其cache的是位于CPU装载单元前。参考M7的内核结构图也能看出。这部分Cache
的SRAM访问速度肯定是略快于AXI总线的,不知道我理解有没有什么问题。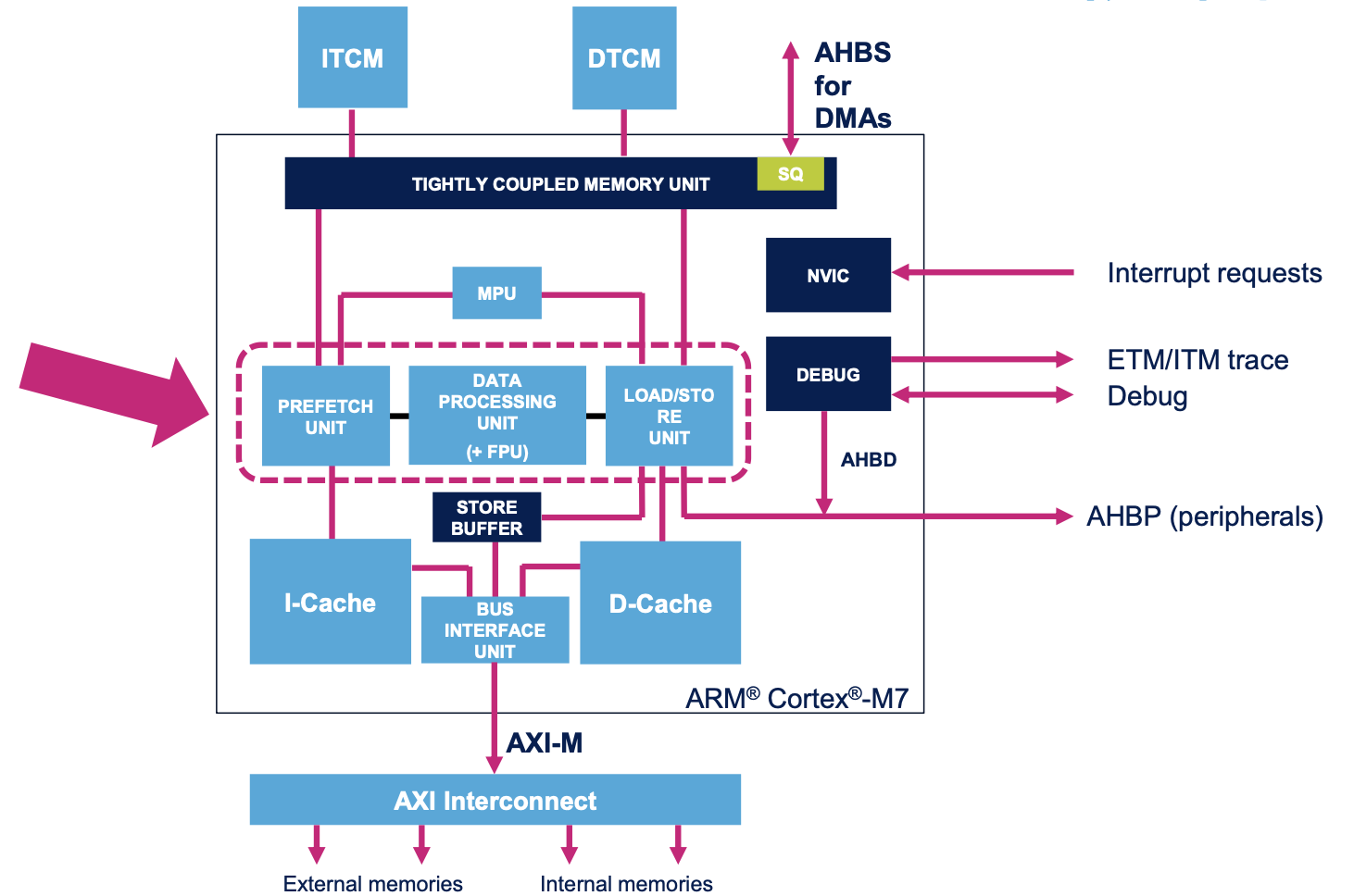
而片内SRAM其本身也未必是个慢速设备,M7的TCM号称0访问延迟,在NXP的RT1xxxx上也是使用的片内SRAM
实现,只是通过不同配置连接不同总线,依旧可以实现低延迟的传输,看起来应该与cache同级别,这个偏题了。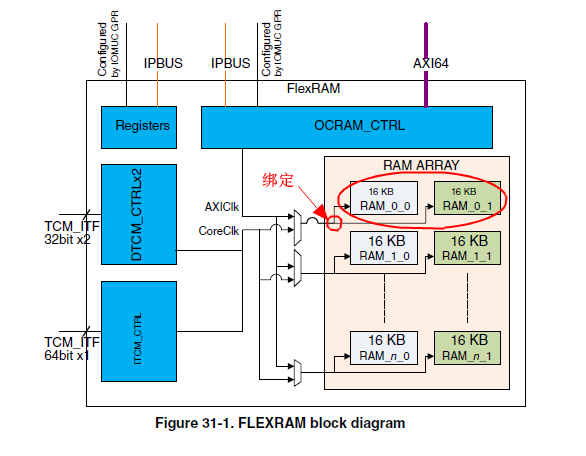
回到这个ACM32F4的芯片上,M33并没有在IP上设计cache,我也认为这个应该是SOC厂商自己加的,它应该属于
片外cache这种机制。即在原有的C-AHB和S-AHB总线上连接了一个cache,再由这个cache去控制慢速IO状态。
这个应该类似于STM32L5对外部cache的设计。而ACM32F4在SRAM的描述上提到了访问可以无延迟,所以对于
这样一个SOC的SRAM再做一个DCache确实也没什么意义。当然这也只是猜测,最好还是希望FAE能开放下这部分。
离线
#5 2022-07-10 23:32:07 分享评论
- musich
- 会员
- 注册时间: 2018-04-17
- 已发帖子: 261
- 积分: 293
Re: 大家一起来研究ACM32F4芯片
想要推广, 应该多放些资料出来, 瞎猜太费工夫. 而且同类的又很多
离线
- 首页
- » 上海航芯
- » 大家一起来研究ACM32F4芯片
东莞哇酷科技有限公司开发