楼主 # 2022-08-01 00:52:23 分享评论
- 游乐场
- 会员
- 注册时间: 2022-07-29
- 已发帖子: 56
- 积分: 174
【代码分享】利用内核定时器做通用delay函数
void delay_us(u32 nus)
{
u32 ticks;
u32 told,tnow,tcnt=0;
GET_CORE_CNT(told); //读取内核定时器数值
ticks=nus*48; //目标延时节拍数=需要延时时间(us)*CORE_CLK(MHz)/4
while(1)
{
GET_CORE_CNT(tnow);
if(tnow!=told)
{
if(tnow<told)tcnt=0xFFFFFFFF-told+tnow; //CORE_CNT递增32位,计算已延时节拍数
else tcnt=tnow-told;
if(tcnt>=ticks)break; //延时完成
}
};
}
离线
楼主 #1 2022-08-01 01:14:46 分享评论
- 游乐场
- 会员
- 注册时间: 2022-07-29
- 已发帖子: 56
- 积分: 174
Re: 【代码分享】利用内核定时器做通用delay函数
内核定时器频率为内核时钟的1/4
离线
#2 2022-08-01 12:10:46 分享评论
- support_gxchip
- Moderator
- 注册时间: 2022-07-26
- 已发帖子: 58
- 积分: 103
Re: 【代码分享】利用内核定时器做通用delay函数
感谢分享
离线
楼主 #3 2022-08-01 16:08:39 分享评论
- 游乐场
- 会员
- 注册时间: 2022-07-29
- 已发帖子: 56
- 积分: 174
Re: 【代码分享】利用内核定时器做通用delay函数
如果用y=kx+b的方式表示延时曲线,假设准确延时为直线y=x,实测内部192M时钟源情况下,12M线程延时大概是y=0.99415x+1.245,x为期望延时,y为实测延时。
根据经验分析,k值应该是时钟误差,换用外部晶振可以减小。b值则是调用函数、取值、译码、计算等造成的,线程频率越高,误差越小。
在以上猜测基础上,10us以内延时用本代码没有什么精确性可言,且各线程误差受线程频率影响较大。不考虑时钟误差的情况下,延时越长越精确,不同频率的线程延时结果越接近,如果是ms级延时,则可以认为是通用延时。
我脑补了半天也没想到10us以内的通用延时怎么写。
离线

#5 2022-08-02 14:05:49 分享评论
- miaoguoqiang
- 会员
- 注册时间: 2022-08-02
- 已发帖子: 3
- 积分: 3
Re: 【代码分享】利用内核定时器做通用delay函数
GET_CORE_CNT 宏展开是什么
离线
楼主 #6 2022-08-03 09:03:07 分享评论
- 游乐场
- 会员
- 注册时间: 2022-07-29
- 已发帖子: 56
- 积分: 174
Re: 【代码分享】利用内核定时器做通用delay函数
miaoguoqiang wrote:
GET_CORE_CNT 宏展开是什么
是读取内核定时器的计数器,取一个指针的值
离线
楼主 #7 2022-08-18 14:41:24 分享评论
- 游乐场
- 会员
- 注册时间: 2022-07-29
- 已发帖子: 56
- 积分: 174
Re: 【代码分享】利用内核定时器做通用delay函数
群里的青菜大佬vegetableswim给出了一个更优的解决方案,在100us内延时比原版代码更优,2us延时误差减小超过10%,以下是两种代码
原版:
void delay_us(u32 nus)
{
u32 ticks;
u32 told, tnow, tcnt = 0;
GET_CORE_CNT(told); //读取内核定时器数值
ticks = nus * SYS_CORE_CLK_MHZ/4; //目标延时节拍数=需要延时时间(us)*CORE_CLK(MHz)/4
while (1)
{
GET_CORE_CNT(tnow);
if (tnow != told)
{
if (tnow < told)tcnt = 0xFFFFFFFF - told + tnow; //CORE_CNT递增32位,计算已延时节拍数
else tcnt = tnow - told;
if (tcnt >= ticks)break; //延时完成
}
};
}优化版:
void delay_us(u32 nus)
{
u32 start,stop,ticks;
start=CORE_CNT;
ticks = nus * SYS_CORE_CLK_MHZ/4;
if(0xFFFFFFFF-start>=ticks){
stop=start+ticks;
while(CORE_CNT<stop && CORE_CNT>start){}
}
else{
stop=ticks-(0xFFFFFFFF-start);
while(CORE_CNT>start){}
while(CORE_CNT<stop){}
}
}离线
楼主 #8 2022-08-31 09:13:03 分享评论
- 游乐场
- 会员
- 注册时间: 2022-07-29
- 已发帖子: 56
- 积分: 174
Re: 【代码分享】利用内核定时器做通用delay函数
由于每次调用该延时都有几us的误差,所以做长延时尽量不要使用循环。
//ms延时
void HAL_Delay(u32 Delay)
{
delay_us(Delay*1000); //误差更小
}
void HAL_Delay(u32 Delay)
{
while(Delay--){
delay_us(1000);
}
}离线
楼主 #9 2022-09-06 14:34:40 分享评论
- 游乐场
- 会员
- 注册时间: 2022-07-29
- 已发帖子: 56
- 积分: 174
Re: 【代码分享】利用内核定时器做通用delay函数
今天又发现一个简单的延时,叫他版本3吧,代码如下:
版本3
void delay_us(u32 nus)
{
u32 start,stop,ticks;
start=CORE_CNT;
ticks = nus * SYS_CORE_CLK_MHZ/4;
while(CORE_CNT-start<ticks){}
}顺手测了一下误差。结果如下: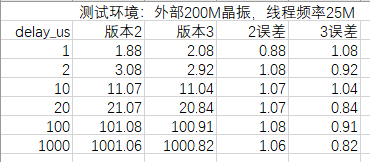
3比2少了一个判断和一个加减语句,但是每次循环多一个减法语句,误差不如2稳定,但是代码量小,用哪个大家自己决定。
离线
楼主 #10 2022-09-06 14:36:31 分享评论
- 游乐场
- 会员
- 注册时间: 2022-07-29
- 已发帖子: 56
- 积分: 174
Re: 【代码分享】利用内核定时器做通用delay函数
又修改了一下ms级延时,以支持0xFFFFFFFFms的延时。
void HAL_Delay(u32 Delay)
{
while(Delay>80000){
delay_us(80000*1000);
Delay-=80000;
}
delay_us(Delay*1000);
}离线
感谢为中文互联网持续输出优质内容的各位老铁们。
QQ: 516333132, 微信(wechat): whycan_cn (哇酷网/挖坑网/填坑网) service@whycan.cn
东莞哇酷科技有限公司开发
东莞哇酷科技有限公司开发