楼主 # 2021-12-21 14:56:44 分享评论
- bigmagic
- 会员

- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54

MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
最近在研究riscv的底层,包括riscv的bkpv扩展,riscv工具链,riscv的qemu,看到D1的硬件性能还不错,结合自己的研究方向,在实际的芯片上做实验更加有效果。加上平头哥的C906已经开源了,这确实是一个选择底层研究riscv不错的硬件平台。
之前研究过一段时间的树莓派baremeta,觉得d1-nezha也是完全可以研究baremetal的
https://github.com/bigmagic123/d1-nezha-baremeta
实验基于全志的soc,目前已经实现了clint,plint等中断系统,还有riscv system timer, soft interrupt等实验,拿到MangoPi-MQ后,也进行led的点灯实验。后期也会逐渐完善i2c,spi, sdio 等等,还有精力的话实现更加高级的外设。
1.startup
2.vector_example
3.uart
4.soft_intrrupt
5.timer
6.plint
7.led
8.input
另外,也适配了rt-thread系统,当前rt-thread是系统运行在riscv machine mode下,因为是实验平台,实现最新版本的rt-thread的适配,后期会结合baremetal做更多有趣的应用。
离线
楼主 #6 2022-01-06 23:46:52 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
d1s rt-thread led实验记录
当前d1s的gpio驱动已经对接到rt-thread的驱动框架上了。
现在描述一下在麻雀派上的点灯操作以及原理分析。
LED对应的引脚是PD22
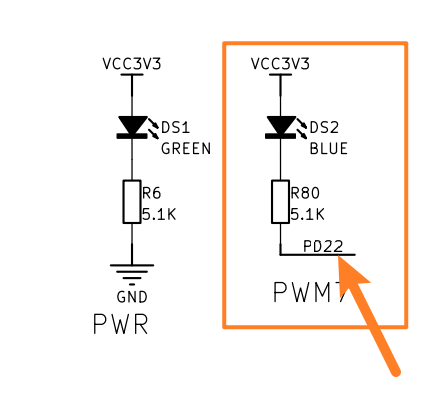
这时对接rt-thread的pin框架,可以按照下面的方式进行
首先需要实现rt-thread pin 框架的ops
static const struct rt_pin_ops ops =
{
d1s_pin_mode,
d1s_pin_write,
d1s_pin_read,
d1s_pin_attach_irq,
d1s_pin_detach_irq,
d1s_pin_irq_enable,
d1s_pin_get,
};实现上述的几个函数的功能,然后将上述的结构体注册进去
rt_device_pin_register("gpio", &ops, RT_NULL);当前只实现了读,写操作,关于中断的操作目前还没有实现。
在操作的代码中,可以通过下面的操作进行
int main(void)
{
printf("Hello RISC-V!\n");
int led_pin = rt_pin_get("PD.22");
rt_pin_mode(led_pin, PIN_MODE_OUTPUT);
while(1)
{
rt_pin_write(led_pin, 1);
rt_thread_mdelay(500);
rt_pin_write(led_pin, 0);
rt_thread_mdelay(500);
}
return 0;
}最后就可以实现点灯操作。
离线
楼主 #7 2022-01-07 18:02:41 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
探索麻雀D1s上的RVV
关键点在于设置VS标志位
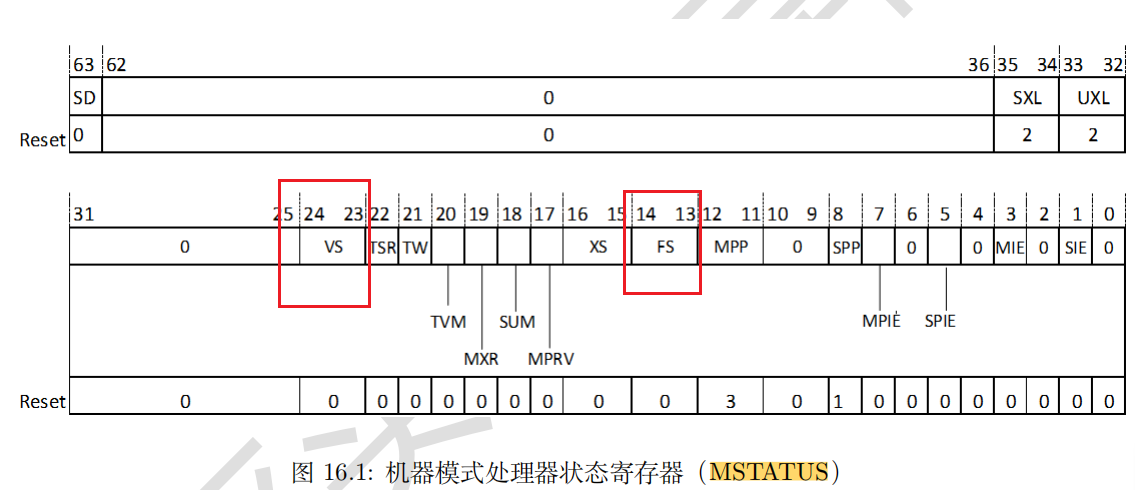
VS位于MSTATUS寄存器的23到24位。但是需要注意的是,当使用RVV时,需要开启浮点寄存器(FS),不然会报错。
同时在编译选项中添加
-march=rv64gcvxtheadc -mabi=lp64d -mtune=c906关于测试的例子,可以参考
https://github.com/T-head-Semi/csi-nn2这是平头哥开源的神经网络库,里面又有一些操作函数,只简单测试一下性能
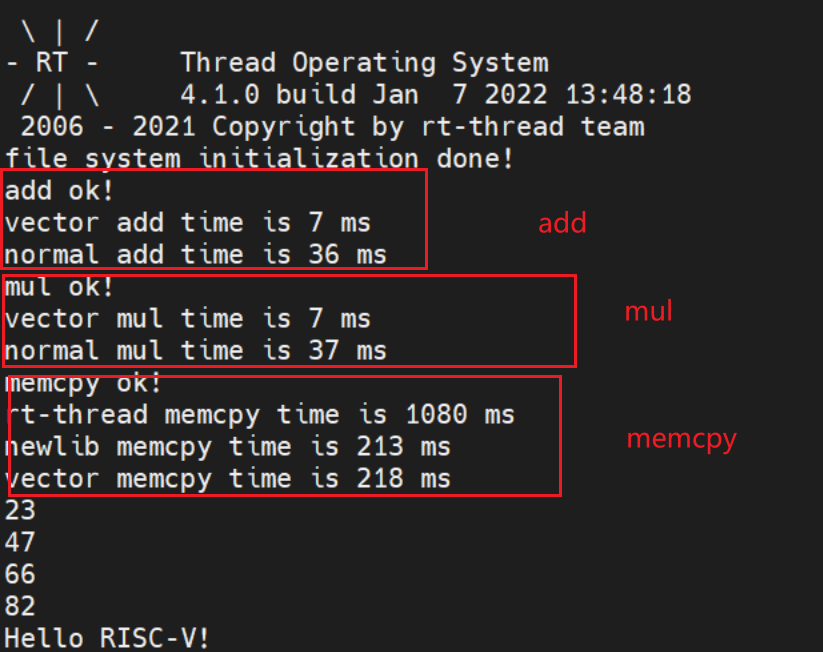
测试结果可以看出,浮点加法,乘法性能还是可以的,但是memcpy还是newlib中优化的较好。
代码可以参考
https://github.com/bigmagic123/d1-nezha-rtthread/blob/main/bsp/d1-nezha/applications/vector.c
离线
楼主 #8 2022-01-25 16:50:11 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
完成了麻雀riscv d1s上的rt-thread 适配lvgl功能
刷新率还算可以,通过demo上测试的平均帧率在38fps,当然这个不是很可信,基本还算流畅吧。应该还有优化空间,现在开源,起到抛砖引玉的作用。
开源代码
https://github.com/bigmagic123/d1-nezha-rtthread
打开env功能
输入
C:\work\work\d1\d1-nezha-rtthread\bsp\d1-nezha
> pkgs --update
==============================> LVGL update done
==============================> lv_music_demo update done
Operation completed successfully.然后输入scons开始编译
最后通过fex工具下载固件到d1s的板子上就可以看到了。
当前gt911触摸驱动已经ok,还没完全适配到lvgl上
离线
楼主 #9 2022-01-25 18:34:57 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
d1s 上的运行rt-thread 上的lvgl 触摸功能也正常了,现在实现的gt911触摸驱动比较粗糙,没有按下移动事件,这里基本对接到lvgl的indev设备,后续有需求再完善功能。
离线
楼主 #10 2022-01-26 11:32:20 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
关于平头哥开源的DSP RVV intrinsic
似乎很久没有维护了,其自带的编译器中是,就拿官网上下载的riscv gcc来看
riscv64-elf-mingw\lib\gcc\riscv64-unknown-elf\8.4.0\include
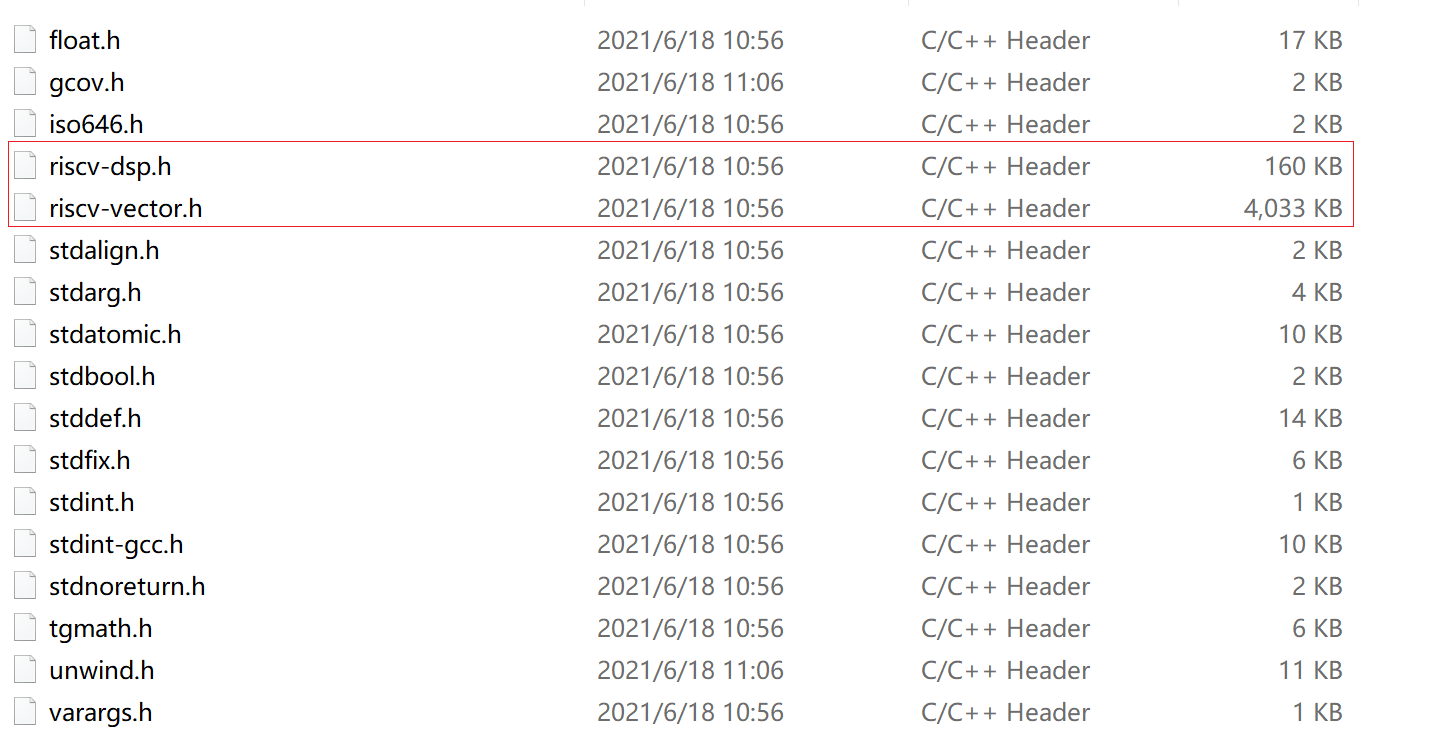
其gcc的版本为8.4.0,平头哥开源出来的gcc版本为10.2.
https://github.com/T-head-Semi/xuantie-gnu-toolchain
其版本号不一样,而且riscv-vector.h和riscv-dsp.h的intrinsic也不一样。这样就有可能平头哥内部维护一个版本的gcc,而开源的又是另外一个版本。
这两个版本的intrinsic应该都不会被gcc上游接纳,所以编译模型也会非常奇怪,感觉这部分不会被启用了。
不过这个也没办法,做芯片相关gcc都会这样搞,就像当年苹果维护gcc一样。后续感觉平头哥对维护自己的开源的xuantie-gnu-toolchain,也会显得有心无力啊。
离线
楼主 #11 2022-01-26 12:16:12 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
d1上的向量自动化
由于d1支持rvv扩展,如果写汇编比较麻烦,用intrinsic比较简单,但是问题是也需要查手册,而且平头哥rvv0.71版本并不在上游支持的范围了。
如果直接写c函数,编译器能够自动优化并且自动向量化,这样才是最智能的方式。
首先需要开启rvv的扩展,并且在gcc编译器中使能rvv支持。这部分可以看我移植的rtt的代码实现。
直接看效果。
#include <riscv-vector.h>
vuint8m8_t test_auto_vand(vuint8m8_t a, vuint8m8_t b)
{
return a & b;
}
int main(void)
{
vuint8m8_t aa = {0};
vuint8m8_t bb = {0};
test_auto_vand(aa,bb);
}通过反汇编可以看到已经自动向量化了

一次性可以将一个数组的变量进行and操作。
这是一个很好的优化特性,如果做代码优化和速度优化,将会很实用。但是需要注意的是,硬件也应该开启rvv支持,否则编译器做了优化,而应该没有开启,会导致系统崩溃。
离线
楼主 #13 2022-01-27 10:07:37 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
@smiletiger
如果是cache问题,那么就flush fb那一块的cache,帧率上不去,就用双缓冲buffer。cache一致性问题不一定是使用了dma。经过研究,在c906中,特别开启了O2优化,很多函数写法都会引起编译器自动优化调用thead自定义指令,虽然可以提高系统性能和速度,但是最好还是注意一下cache问题,另外就是内存不经过分配直接使用,可能会多出ebreak的指令操作。O0优化基本没这个问题,但是性能有所下降,你自己做取舍。
最近编辑记录 bigmagic (2022-01-27 10:07:56)
离线
楼主 #14 2022-01-27 11:24:13 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
riscv编译器中,不同的选项组合对于系统性能的影响非常严重。我们往往会通过优化来进行code size和性能的提升,这里不仅仅涉及到内存访问速度,更多是底层算数或者逻辑操作的优化,这一点点优化空间对于系统的影响是非常大的。下面列出几个例子。以下测试都是基于开启O2优化后进行的测试。
https://github.com/bigmagic123/d1-nezha-rtthread/blob/main/bsp/d1-nezha/rtconfig.py
DEVICE = ' -march=rv64gcvxtheadc -mabi=lp64d -mtune=c906 -fno-omit-frame-pointer '
CFLAGS = DEVICE + ' -ffreestanding -fno-common -ffunction-sections -fdata-sections -fstrict-volatile-bitfields '-fno-omit-frame-pointer
开启这个选项,可以增加fp的功能,也就具备栈回溯的功能。
https://pdos.csail.mit.edu/6.828/2019/lec/l-riscv.txt
其栈的分布如下:
Stack
.
.
+-> .
| +-----------------+ |
| | return address | |
| | previous fp ------+
| | saved registers |
| | local variables |
| | ... | <-+
| +-----------------+ |
| | return address | |
+------ previous fp | |
| saved registers | |
| local variables | |
+-> | ... | |
| +-----------------+ |
| | return address | |
| | previous fp ------+
| | saved registers |
| | local variables |
| | ... | <-+
| +-----------------+ |
| | return address | |
+------ previous fp | |
| saved registers | |
| local variables | |
$fp --> | ... | |
+-----------------+ |
| return address | |
| previous fp ------+
| saved registers |
$sp --> | local variables |
+-----------------+同样写一个函数
unsigned long test_addsl(unsigned long b,unsigned long c)
{
unsigned long a;
a = b + (c << 2);
return a;
}当带有fno-omit-frame-pointer时,其生成的汇编如下:
00000000400000f0 <test_addsl>:
400000f0: 1141 addi sp,sp,-16
400000f2: e422 sd s0,8(sp)
400000f4: 0800 addi s0,sp,16
400000f6: 6422 ld s0,8(sp)
400000f8: 04b5150b addsl a0,a0,a1,2
400000fc: 0141 addi sp,sp,16
400000fe: 8082 ret
...如果不需要栈回溯,则不添加该指令
00000000400000d0 <test_addsl>:
400000d0: 04b5150b addsl a0,a0,a1,2
400000d4: 8082 ret
...可以看到优化很多,条指令,减少了内存读写次数。可见其优化的力度还是很大的。有时候费尽心力的去优化驱动提高性能,而再编译器层面,却一个选项就可以让性能提高非常大。
-ffunction-sections -fdata-sections
减少code size的选项,如果gcc选项中添加这个,将会让代码函数进行调用优化,如果没使用到的函数则不会被链接进去。并且函数的链接形式也会发生一些改变。
也就是说可能通过objdump再也通过函数名字找到某些函数的反汇编代码了。
离线
楼主 #15 2022-01-27 11:45:53 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
f133 && d1 平头哥自定义扩展指令的调用与研究
想要发挥出riscv极致的性能特性,少不了对riscv指令的扩展,这里除了通用的bkpv指令的扩展外,c906也自己定义了自己的指令实现。这部分可以参考《玄铁C906_R1S0用户手册》,但是这部分的优化,要想使用的好,必须对gcc有一定的了解,由于平头哥、全志对这部分的资料如何使用,放出来的并不多,完全没法将其性能发挥到极致。作为gcc的开发者和研究者,对这部分可以做一个简单的说明。
文档说扩展指令必须在mxstatus.theadisaee==1时才能够执行,半精度指令在mstatus.fs!=2'00时才能正常执行,否则会产生非法指令的异常。这是硬件的限制,下面来看一下算数运算指令。
在编译器选项的优化中,需要开启O2优化,此时才能让编译器去优化特定的操作,例如
ADDSL
寄存器位移
rd <- rs1+rs2 << imm2
unsigned long test_addsl(unsigned long b,unsigned long c)
{
unsigned long a;
a = b + (c << 2);
return a;
}这个是一个很典型的位移后再加的操作。
如果不开启O2优化,采用O0优化,则生成汇编代码如下
000000004000c5a0 <test_addsl>:
4000c5a0: 7179 addi sp,sp,-48
4000c5a2: f422 sd s0,40(sp)
4000c5a4: 1800 addi s0,sp,48
4000c5a6: fca43c23 sd a0,-40(s0)
4000c5aa: fcb43823 sd a1,-48(s0)
4000c5ae: fd043783 ld a5,-48(s0)
4000c5b2: 078a slli a5,a5,0x2
4000c5b4: fd843703 ld a4,-40(s0)
4000c5b8: 97ba add a5,a5,a4
4000c5ba: fef43423 sd a5,-24(s0)
4000c5be: fe843783 ld a5,-24(s0)
4000c5c2: 853e mv a0,a5
4000c5c4: 7422 ld s0,40(sp)
4000c5c6: 6145 addi sp,sp,48
4000c5c8: 8082 ret开启O2优化后,则gcc会对指令进行优化,采用平头哥自定义指令。
0000000040000500 <test_addsl>:
40000500: 04b5150b addsl a0,a0,a1,2
40000504: 8082 ret
...肉眼可见其优化力度了,这个目前在标准的riscv指令中就是B扩展,相信随着B扩展的稳定,在性能和code size上一定可以超过arm指令。
类似的还有
MULA
乘法累加
MULS
乘法累减
左移右移操作,FF快速查找等等。
这些并不需要使用者去写汇编指令,只需要开启编译选项,编译器会自动优化,这对于程序的执行效率将会非常大的影响。
需要注意的是,想要使用平头哥自定义的扩展指令,必须开启MXSTATUS的THEADISAEE位。

离线
楼主 #18 2022-01-27 14:39:15 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
@smiletiger
开启优化选项,并且使能了平头哥的扩展指令集或者V扩展指令,就要注意代码的规范了,说不定就优化过度了(插入了一些特殊操作),目前平头哥的riscv gcc目前仍然在编程模型上有着一定的限制,并不会如arm编译器一样稳定,特别是开启优化后,就要十分注意了。可以通过empc地址跟踪一下函数的报错地方,看看反汇编是否正常。
离线
楼主 #19 2022-01-27 15:52:19 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
E906的自动压栈机制
最近研究平头哥开源的gcc编译器,发现其针对MCU系列,也有硬件自动压栈指令

自动生成ipush和ipop的方式也有意思
匹配条件
-march=xtheade,开启O2优化
#include <string.h>
#include <stdio.h>
__attribute__((interrupt)) void func(void)
{
}
void main(void)
{
func();
}然后编译
riscv64-unknown-elf-gcc -march=rv64gcxtheade -mabi=lp64d -ffreestanding -fno-common applications\test\test_thead.c -o aaa
反汇编该文件
000000000001018e <func>:
1018e: 0040000b ipush
10192: 1141 addi sp,sp,-16
10194: e422 sd s0,8(sp)
10196: 1100 addi s0,sp,160
10198: 0001 nop
1019a: 6422 ld s0,8(sp)
1019c: 0141 addi sp,sp,16
1019e: 0050000b ipop这就意味着,在MCU层面,使用向量中断,不用考虑中断的压栈和出栈问题,大大提高MCU的实时性。该机制非常重要,但是对于D1这种高性能的MPU,并没有这种特性,更多的灵活性在编程者手中。
离线
楼主 #20 2022-01-27 16:18:02 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
玄铁C900系列工具链更新了
https://occ.t-head.cn/community/download?id=3996672928124047360
终于更新到10.2版本了
Thread model: single
Supported LTO compression algorithms: zlib zstd
gcc version 10.2.0 (Xuantie-900 elf newlib gcc Toolchain V2.2.4 B-20211227)
很显然,平头哥内部还在积极的向上游的riscv gcc保持统一的,这对riscv发展来说是件好事。通过对其关注,发现平头哥确实在riscv gcc的上游rvv上提供了不少的patch。但是并非开放在xuantie gcc中,社区和内部还是有所保留。
https://github.com/riscv-collab/riscv-gcc/issues/320
There is a guy at rivai.ai who claims to be working on gcc rvv 1.0 support for mainline FSF gcc, so maybe in a few months we will have something usable. Rivai is in Shenzhen.如果可能,是不是能够在今年见的完整的商业可用的riscv rvv指令支持呢?期待完成向量支持,这样riscv将会在桌面,AI,高性能上大有可为
离线
楼主 #25 2022-02-23 09:56:06 分享评论
- bigmagic
- 会员
- 注册时间: 2018-02-23
- 已发帖子: 31
- 积分: 54
Re: MangoPi-MQ 麻雀D1s && D1 Nezha 裸机实验 && rtos实验
@zhong
编译器需要支持V扩展,另外编译器选项-march=rv64gcvxtheadc -mabi=lp64d,其中的v表示告诉编译器开启v扩展指令
离线
东莞哇酷科技有限公司开发