楼主 #1 2018-02-18 22:00:03 分享评论
- 晕哥
- 管理员

- 所在地: wechat: whycan_cn
- 注册时间: 2017-09-06
- 已发帖子: 9,492
- 积分: 9207
编译glfw 的演示程序试一试
http://www.glfw.org/docs/latest/quick.html
#include <glad/glad.h>
#include <GLFW/glfw3.h>
#include "linmath.h"
#include <stdlib.h>
#include <stdio.h>
static const struct
{
float x, y;
float r, g, b;
} vertices[3] =
{
{ -0.6f, -0.4f, 1.f, 0.f, 0.f },
{ 0.6f, -0.4f, 0.f, 1.f, 0.f },
{ 0.f, 0.6f, 0.f, 0.f, 1.f }
};
static const char* vertex_shader_text =
"uniform mat4 MVP;\n"
"attribute vec3 vCol;\n"
"attribute vec2 vPos;\n"
"varying vec3 color;\n"
"void main()\n"
"{\n"
" gl_Position = MVP * vec4(vPos, 0.0, 1.0);\n"
" color = vCol;\n"
"}\n";
static const char* fragment_shader_text =
"varying vec3 color;\n"
"void main()\n"
"{\n"
" gl_FragColor = vec4(color, 1.0);\n"
"}\n";
static void error_callback(int error, const char* description)
{
fprintf(stderr, "Error: %s\n", description);
}
static void key_callback(GLFWwindow* window, int key, int scancode, int action, int mods)
{
if (key == GLFW_KEY_ESCAPE && action == GLFW_PRESS)
glfwSetWindowShouldClose(window, GLFW_TRUE);
}
int main(void)
{
GLFWwindow* window;
GLuint vertex_buffer, vertex_shader, fragment_shader, program;
GLint mvp_location, vpos_location, vcol_location;
glfwSetErrorCallback(error_callback);
if (!glfwInit())
exit(EXIT_FAILURE);
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 2);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 0);
window = glfwCreateWindow(640, 480, "Simple example", NULL, NULL);
if (!window)
{
glfwTerminate();
exit(EXIT_FAILURE);
}
glfwSetKeyCallback(window, key_callback);
glfwMakeContextCurrent(window);
gladLoadGLLoader((GLADloadproc) glfwGetProcAddress);
glfwSwapInterval(1);
// NOTE: OpenGL error checks have been omitted for brevity
glGenBuffers(1, &vertex_buffer);
glBindBuffer(GL_ARRAY_BUFFER, vertex_buffer);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
vertex_shader = glCreateShader(GL_VERTEX_SHADER);
glShaderSource(vertex_shader, 1, &vertex_shader_text, NULL);
glCompileShader(vertex_shader);
fragment_shader = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragment_shader, 1, &fragment_shader_text, NULL);
glCompileShader(fragment_shader);
program = glCreateProgram();
glAttachShader(program, vertex_shader);
glAttachShader(program, fragment_shader);
glLinkProgram(program);
mvp_location = glGetUniformLocation(program, "MVP");
vpos_location = glGetAttribLocation(program, "vPos");
vcol_location = glGetAttribLocation(program, "vCol");
glEnableVertexAttribArray(vpos_location);
glVertexAttribPointer(vpos_location, 2, GL_FLOAT, GL_FALSE,
sizeof(float) * 5, (void*) 0);
glEnableVertexAttribArray(vcol_location);
glVertexAttribPointer(vcol_location, 3, GL_FLOAT, GL_FALSE,
sizeof(float) * 5, (void*) (sizeof(float) * 2));
while (!glfwWindowShouldClose(window))
{
float ratio;
int width, height;
mat4x4 m, p, mvp;
glfwGetFramebufferSize(window, &width, &height);
ratio = width / (float) height;
glViewport(0, 0, width, height);
glClear(GL_COLOR_BUFFER_BIT);
mat4x4_identity(m);
mat4x4_rotate_Z(m, m, (float) glfwGetTime());
mat4x4_ortho(p, -ratio, ratio, -1.f, 1.f, 1.f, -1.f);
mat4x4_mul(mvp, p, m);
glUseProgram(program);
glUniformMatrix4fv(mvp_location, 1, GL_FALSE, (const GLfloat*) mvp);
glDrawArrays(GL_TRIANGLES, 0, 3);
glfwSwapBuffers(window);
glfwPollEvents();
}
glfwDestroyWindow(window);
glfwTerminate();
exit(EXIT_SUCCESS);
}执行:
linmath.h 内容:
#ifndef LINMATH_H
#define LINMATH_H
#include <math.h>
#define LINMATH_H_DEFINE_VEC(n) \
typedef float vec##n[n]; \
static inline void vec##n##_add(vec##n r, vec##n const a, vec##n const b) \
{ \
int i; \
for(i=0; i<n; ++i) \
r[i] = a[i] + b[i]; \
} \
static inline void vec##n##_sub(vec##n r, vec##n const a, vec##n const b) \
{ \
int i; \
for(i=0; i<n; ++i) \
r[i] = a[i] - b[i]; \
} \
static inline void vec##n##_scale(vec##n r, vec##n const v, float const s) \
{ \
int i; \
for(i=0; i<n; ++i) \
r[i] = v[i] * s; \
} \
static inline float vec##n##_mul_inner(vec##n const a, vec##n const b) \
{ \
float p = 0.; \
int i; \
for(i=0; i<n; ++i) \
p += b[i]*a[i]; \
return p; \
} \
static inline float vec##n##_len(vec##n const v) \
{ \
return sqrtf(vec##n##_mul_inner(v,v)); \
} \
static inline void vec##n##_norm(vec##n r, vec##n const v) \
{ \
float k = 1.0 / vec##n##_len(v); \
vec##n##_scale(r, v, k); \
} \
static inline void vec##n##_min(vec##n r, vec##n a, vec##n b) \
{ \
int i; \
for(i=0; i<n; ++i) \
r[i] = a[i]<b[i] ? a[i] : b[i]; \
} \
static inline void vec##n##_max(vec##n r, vec##n a, vec##n b) \
{ \
int i; \
for(i=0; i<n; ++i) \
r[i] = a[i]>b[i] ? a[i] : b[i]; \
}
LINMATH_H_DEFINE_VEC(2)
LINMATH_H_DEFINE_VEC(3)
LINMATH_H_DEFINE_VEC(4)
static inline void vec3_mul_cross(vec3 r, vec3 const a, vec3 const b)
{
r[0] = a[1]*b[2] - a[2]*b[1];
r[1] = a[2]*b[0] - a[0]*b[2];
r[2] = a[0]*b[1] - a[1]*b[0];
}
static inline void vec3_reflect(vec3 r, vec3 const v, vec3 const n)
{
float p = 2.f*vec3_mul_inner(v, n);
int i;
for(i=0;i<3;++i)
r[i] = v[i] - p*n[i];
}
static inline void vec4_mul_cross(vec4 r, vec4 a, vec4 b)
{
r[0] = a[1]*b[2] - a[2]*b[1];
r[1] = a[2]*b[0] - a[0]*b[2];
r[2] = a[0]*b[1] - a[1]*b[0];
r[3] = 1.f;
}
static inline void vec4_reflect(vec4 r, vec4 v, vec4 n)
{
float p = 2.f*vec4_mul_inner(v, n);
int i;
for(i=0;i<4;++i)
r[i] = v[i] - p*n[i];
}
typedef vec4 mat4x4[4];
static inline void mat4x4_identity(mat4x4 M)
{
int i, j;
for(i=0; i<4; ++i)
for(j=0; j<4; ++j)
M[i][j] = i==j ? 1.f : 0.f;
}
static inline void mat4x4_dup(mat4x4 M, mat4x4 N)
{
int i, j;
for(i=0; i<4; ++i)
for(j=0; j<4; ++j)
M[i][j] = N[i][j];
}
static inline void mat4x4_row(vec4 r, mat4x4 M, int i)
{
int k;
for(k=0; k<4; ++k)
r[k] = M[k][i];
}
static inline void mat4x4_col(vec4 r, mat4x4 M, int i)
{
int k;
for(k=0; k<4; ++k)
r[k] = M[i][k];
}
static inline void mat4x4_transpose(mat4x4 M, mat4x4 N)
{
int i, j;
for(j=0; j<4; ++j)
for(i=0; i<4; ++i)
M[i][j] = N[j][i];
}
static inline void mat4x4_add(mat4x4 M, mat4x4 a, mat4x4 b)
{
int i;
for(i=0; i<4; ++i)
vec4_add(M[i], a[i], b[i]);
}
static inline void mat4x4_sub(mat4x4 M, mat4x4 a, mat4x4 b)
{
int i;
for(i=0; i<4; ++i)
vec4_sub(M[i], a[i], b[i]);
}
static inline void mat4x4_scale(mat4x4 M, mat4x4 a, float k)
{
int i;
for(i=0; i<4; ++i)
vec4_scale(M[i], a[i], k);
}
static inline void mat4x4_scale_aniso(mat4x4 M, mat4x4 a, float x, float y, float z)
{
int i;
vec4_scale(M[0], a[0], x);
vec4_scale(M[1], a[1], y);
vec4_scale(M[2], a[2], z);
for(i = 0; i < 4; ++i) {
M[3][i] = a[3][i];
}
}
static inline void mat4x4_mul(mat4x4 M, mat4x4 a, mat4x4 b)
{
mat4x4 temp;
int k, r, c;
for(c=0; c<4; ++c) for(r=0; r<4; ++r) {
temp[c][r] = 0.f;
for(k=0; k<4; ++k)
temp[c][r] += a[k][r] * b[c][k];
}
mat4x4_dup(M, temp);
}
static inline void mat4x4_mul_vec4(vec4 r, mat4x4 M, vec4 v)
{
int i, j;
for(j=0; j<4; ++j) {
r[j] = 0.f;
for(i=0; i<4; ++i)
r[j] += M[i][j] * v[i];
}
}
static inline void mat4x4_translate(mat4x4 T, float x, float y, float z)
{
mat4x4_identity(T);
T[3][0] = x;
T[3][1] = y;
T[3][2] = z;
}
static inline void mat4x4_translate_in_place(mat4x4 M, float x, float y, float z)
{
vec4 t = {x, y, z, 0};
vec4 r;
int i;
for (i = 0; i < 4; ++i) {
mat4x4_row(r, M, i);
M[3][i] += vec4_mul_inner(r, t);
}
}
static inline void mat4x4_from_vec3_mul_outer(mat4x4 M, vec3 a, vec3 b)
{
int i, j;
for(i=0; i<4; ++i) for(j=0; j<4; ++j)
M[i][j] = i<3 && j<3 ? a[i] * b[j] : 0.f;
}
static inline void mat4x4_rotate(mat4x4 R, mat4x4 M, float x, float y, float z, float angle)
{
float s = sinf(angle);
float c = cosf(angle);
vec3 u = {x, y, z};
if(vec3_len(u) > 1e-4) {
vec3_norm(u, u);
mat4x4 T;
mat4x4_from_vec3_mul_outer(T, u, u);
mat4x4 S = {
{ 0, u[2], -u[1], 0},
{-u[2], 0, u[0], 0},
{ u[1], -u[0], 0, 0},
{ 0, 0, 0, 0}
};
mat4x4_scale(S, S, s);
mat4x4 C;
mat4x4_identity(C);
mat4x4_sub(C, C, T);
mat4x4_scale(C, C, c);
mat4x4_add(T, T, C);
mat4x4_add(T, T, S);
T[3][3] = 1.;
mat4x4_mul(R, M, T);
} else {
mat4x4_dup(R, M);
}
}
static inline void mat4x4_rotate_X(mat4x4 Q, mat4x4 M, float angle)
{
float s = sinf(angle);
float c = cosf(angle);
mat4x4 R = {
{1.f, 0.f, 0.f, 0.f},
{0.f, c, s, 0.f},
{0.f, -s, c, 0.f},
{0.f, 0.f, 0.f, 1.f}
};
mat4x4_mul(Q, M, R);
}
static inline void mat4x4_rotate_Y(mat4x4 Q, mat4x4 M, float angle)
{
float s = sinf(angle);
float c = cosf(angle);
mat4x4 R = {
{ c, 0.f, s, 0.f},
{ 0.f, 1.f, 0.f, 0.f},
{ -s, 0.f, c, 0.f},
{ 0.f, 0.f, 0.f, 1.f}
};
mat4x4_mul(Q, M, R);
}
static inline void mat4x4_rotate_Z(mat4x4 Q, mat4x4 M, float angle)
{
float s = sinf(angle);
float c = cosf(angle);
mat4x4 R = {
{ c, s, 0.f, 0.f},
{ -s, c, 0.f, 0.f},
{ 0.f, 0.f, 1.f, 0.f},
{ 0.f, 0.f, 0.f, 1.f}
};
mat4x4_mul(Q, M, R);
}
static inline void mat4x4_invert(mat4x4 T, mat4x4 M)
{
float s[6];
float c[6];
s[0] = M[0][0]*M[1][1] - M[1][0]*M[0][1];
s[1] = M[0][0]*M[1][2] - M[1][0]*M[0][2];
s[2] = M[0][0]*M[1][3] - M[1][0]*M[0][3];
s[3] = M[0][1]*M[1][2] - M[1][1]*M[0][2];
s[4] = M[0][1]*M[1][3] - M[1][1]*M[0][3];
s[5] = M[0][2]*M[1][3] - M[1][2]*M[0][3];
c[0] = M[2][0]*M[3][1] - M[3][0]*M[2][1];
c[1] = M[2][0]*M[3][2] - M[3][0]*M[2][2];
c[2] = M[2][0]*M[3][3] - M[3][0]*M[2][3];
c[3] = M[2][1]*M[3][2] - M[3][1]*M[2][2];
c[4] = M[2][1]*M[3][3] - M[3][1]*M[2][3];
c[5] = M[2][2]*M[3][3] - M[3][2]*M[2][3];
/* Assumes it is invertible */
float idet = 1.0f/( s[0]*c[5]-s[1]*c[4]+s[2]*c[3]+s[3]*c[2]-s[4]*c[1]+s[5]*c[0] );
T[0][0] = ( M[1][1] * c[5] - M[1][2] * c[4] + M[1][3] * c[3]) * idet;
T[0][1] = (-M[0][1] * c[5] + M[0][2] * c[4] - M[0][3] * c[3]) * idet;
T[0][2] = ( M[3][1] * s[5] - M[3][2] * s[4] + M[3][3] * s[3]) * idet;
T[0][3] = (-M[2][1] * s[5] + M[2][2] * s[4] - M[2][3] * s[3]) * idet;
T[1][0] = (-M[1][0] * c[5] + M[1][2] * c[2] - M[1][3] * c[1]) * idet;
T[1][1] = ( M[0][0] * c[5] - M[0][2] * c[2] + M[0][3] * c[1]) * idet;
T[1][2] = (-M[3][0] * s[5] + M[3][2] * s[2] - M[3][3] * s[1]) * idet;
T[1][3] = ( M[2][0] * s[5] - M[2][2] * s[2] + M[2][3] * s[1]) * idet;
T[2][0] = ( M[1][0] * c[4] - M[1][1] * c[2] + M[1][3] * c[0]) * idet;
T[2][1] = (-M[0][0] * c[4] + M[0][1] * c[2] - M[0][3] * c[0]) * idet;
T[2][2] = ( M[3][0] * s[4] - M[3][1] * s[2] + M[3][3] * s[0]) * idet;
T[2][3] = (-M[2][0] * s[4] + M[2][1] * s[2] - M[2][3] * s[0]) * idet;
T[3][0] = (-M[1][0] * c[3] + M[1][1] * c[1] - M[1][2] * c[0]) * idet;
T[3][1] = ( M[0][0] * c[3] - M[0][1] * c[1] + M[0][2] * c[0]) * idet;
T[3][2] = (-M[3][0] * s[3] + M[3][1] * s[1] - M[3][2] * s[0]) * idet;
T[3][3] = ( M[2][0] * s[3] - M[2][1] * s[1] + M[2][2] * s[0]) * idet;
}
static inline void mat4x4_orthonormalize(mat4x4 R, mat4x4 M)
{
mat4x4_dup(R, M);
float s = 1.;
vec3 h;
vec3_norm(R[2], R[2]);
s = vec3_mul_inner(R[1], R[2]);
vec3_scale(h, R[2], s);
vec3_sub(R[1], R[1], h);
vec3_norm(R[2], R[2]);
s = vec3_mul_inner(R[1], R[2]);
vec3_scale(h, R[2], s);
vec3_sub(R[1], R[1], h);
vec3_norm(R[1], R[1]);
s = vec3_mul_inner(R[0], R[1]);
vec3_scale(h, R[1], s);
vec3_sub(R[0], R[0], h);
vec3_norm(R[0], R[0]);
}
static inline void mat4x4_frustum(mat4x4 M, float l, float r, float b, float t, float n, float f)
{
M[0][0] = 2.f*n/(r-l);
M[0][1] = M[0][2] = M[0][3] = 0.f;
M[1][1] = 2.*n/(t-b);
M[1][0] = M[1][2] = M[1][3] = 0.f;
M[2][0] = (r+l)/(r-l);
M[2][1] = (t+b)/(t-b);
M[2][2] = -(f+n)/(f-n);
M[2][3] = -1.f;
M[3][2] = -2.f*(f*n)/(f-n);
M[3][0] = M[3][1] = M[3][3] = 0.f;
}
static inline void mat4x4_ortho(mat4x4 M, float l, float r, float b, float t, float n, float f)
{
M[0][0] = 2.f/(r-l);
M[0][1] = M[0][2] = M[0][3] = 0.f;
M[1][1] = 2.f/(t-b);
M[1][0] = M[1][2] = M[1][3] = 0.f;
M[2][2] = -2.f/(f-n);
M[2][0] = M[2][1] = M[2][3] = 0.f;
M[3][0] = -(r+l)/(r-l);
M[3][1] = -(t+b)/(t-b);
M[3][2] = -(f+n)/(f-n);
M[3][3] = 1.f;
}
static inline void mat4x4_perspective(mat4x4 m, float y_fov, float aspect, float n, float f)
{
/* NOTE: Degrees are an unhandy unit to work with.
* linmath.h uses radians for everything! */
float const a = 1.f / tan(y_fov / 2.f);
m[0][0] = a / aspect;
m[0][1] = 0.f;
m[0][2] = 0.f;
m[0][3] = 0.f;
m[1][0] = 0.f;
m[1][1] = a;
m[1][2] = 0.f;
m[1][3] = 0.f;
m[2][0] = 0.f;
m[2][1] = 0.f;
m[2][2] = -((f + n) / (f - n));
m[2][3] = -1.f;
m[3][0] = 0.f;
m[3][1] = 0.f;
m[3][2] = -((2.f * f * n) / (f - n));
m[3][3] = 0.f;
}
static inline void mat4x4_look_at(mat4x4 m, vec3 eye, vec3 center, vec3 up)
{
/* Adapted from Android's OpenGL Matrix.java. */
/* See the OpenGL GLUT documentation for gluLookAt for a description */
/* of the algorithm. We implement it in a straightforward way: */
/* TODO: The negation of of can be spared by swapping the order of
* operands in the following cross products in the right way. */
vec3 f;
vec3_sub(f, center, eye);
vec3_norm(f, f);
vec3 s;
vec3_mul_cross(s, f, up);
vec3_norm(s, s);
vec3 t;
vec3_mul_cross(t, s, f);
m[0][0] = s[0];
m[0][1] = t[0];
m[0][2] = -f[0];
m[0][3] = 0.f;
m[1][0] = s[1];
m[1][1] = t[1];
m[1][2] = -f[1];
m[1][3] = 0.f;
m[2][0] = s[2];
m[2][1] = t[2];
m[2][2] = -f[2];
m[2][3] = 0.f;
m[3][0] = 0.f;
m[3][1] = 0.f;
m[3][2] = 0.f;
m[3][3] = 1.f;
mat4x4_translate_in_place(m, -eye[0], -eye[1], -eye[2]);
}
typedef float quat[4];
static inline void quat_identity(quat q)
{
q[0] = q[1] = q[2] = 0.f;
q[3] = 1.f;
}
static inline void quat_add(quat r, quat a, quat b)
{
int i;
for(i=0; i<4; ++i)
r[i] = a[i] + b[i];
}
static inline void quat_sub(quat r, quat a, quat b)
{
int i;
for(i=0; i<4; ++i)
r[i] = a[i] - b[i];
}
static inline void quat_mul(quat r, quat p, quat q)
{
vec3 w;
vec3_mul_cross(r, p, q);
vec3_scale(w, p, q[3]);
vec3_add(r, r, w);
vec3_scale(w, q, p[3]);
vec3_add(r, r, w);
r[3] = p[3]*q[3] - vec3_mul_inner(p, q);
}
static inline void quat_scale(quat r, quat v, float s)
{
int i;
for(i=0; i<4; ++i)
r[i] = v[i] * s;
}
static inline float quat_inner_product(quat a, quat b)
{
float p = 0.f;
int i;
for(i=0; i<4; ++i)
p += b[i]*a[i];
return p;
}
static inline void quat_conj(quat r, quat q)
{
int i;
for(i=0; i<3; ++i)
r[i] = -q[i];
r[3] = q[3];
}
static inline void quat_rotate(quat r, float angle, vec3 axis) {
vec3 v;
vec3_scale(v, axis, sinf(angle / 2));
int i;
for(i=0; i<3; ++i)
r[i] = v[i];
r[3] = cosf(angle / 2);
}
#define quat_norm vec4_norm
static inline void quat_mul_vec3(vec3 r, quat q, vec3 v)
{
/*
* Method by Fabian 'ryg' Giessen (of Farbrausch)
t = 2 * cross(q.xyz, v)
v' = v + q.w * t + cross(q.xyz, t)
*/
vec3 t;
vec3 q_xyz = {q[0], q[1], q[2]};
vec3 u = {q[0], q[1], q[2]};
vec3_mul_cross(t, q_xyz, v);
vec3_scale(t, t, 2);
vec3_mul_cross(u, q_xyz, t);
vec3_scale(t, t, q[3]);
vec3_add(r, v, t);
vec3_add(r, r, u);
}
static inline void mat4x4_from_quat(mat4x4 M, quat q)
{
float a = q[3];
float b = q[0];
float c = q[1];
float d = q[2];
float a2 = a*a;
float b2 = b*b;
float c2 = c*c;
float d2 = d*d;
M[0][0] = a2 + b2 - c2 - d2;
M[0][1] = 2.f*(b*c + a*d);
M[0][2] = 2.f*(b*d - a*c);
M[0][3] = 0.f;
M[1][0] = 2*(b*c - a*d);
M[1][1] = a2 - b2 + c2 - d2;
M[1][2] = 2.f*(c*d + a*b);
M[1][3] = 0.f;
M[2][0] = 2.f*(b*d + a*c);
M[2][1] = 2.f*(c*d - a*b);
M[2][2] = a2 - b2 - c2 + d2;
M[2][3] = 0.f;
M[3][0] = M[3][1] = M[3][2] = 0.f;
M[3][3] = 1.f;
}
static inline void mat4x4o_mul_quat(mat4x4 R, mat4x4 M, quat q)
{
/* XXX: The way this is written only works for othogonal matrices. */
/* TODO: Take care of non-orthogonal case. */
quat_mul_vec3(R[0], q, M[0]);
quat_mul_vec3(R[1], q, M[1]);
quat_mul_vec3(R[2], q, M[2]);
R[3][0] = R[3][1] = R[3][2] = 0.f;
R[3][3] = 1.f;
}
static inline void quat_from_mat4x4(quat q, mat4x4 M)
{
float r=0.f;
int i;
int perm[] = { 0, 1, 2, 0, 1 };
int *p = perm;
for(i = 0; i<3; i++) {
float m = M[i][i];
if( m < r )
continue;
m = r;
p = &perm[i];
}
r = sqrtf(1.f + M[p[0]][p[0]] - M[p[1]][p[1]] - M[p[2]][p[2]] );
if(r < 1e-6) {
q[0] = 1.f;
q[1] = q[2] = q[3] = 0.f;
return;
}
q[0] = r/2.f;
q[1] = (M[p[0]][p[1]] - M[p[1]][p[0]])/(2.f*r);
q[2] = (M[p[2]][p[0]] - M[p[0]][p[2]])/(2.f*r);
q[3] = (M[p[2]][p[1]] - M[p[1]][p[2]])/(2.f*r);
}
#endif参考这里:
https://whycan.cn/t_764.html#p2949
sudo apt-get install cmake
cd /tmp
git clone https://github.com/glfw/glfw.git
cd glfw
cmake CMakeLists.txt
make
sudo make install
把上面的代码拷到 glfw/examples目录
执行编译指令:
gcc -o test test.c -lglfw3 -lGLEW -lGL -lX11 -lXi -lXrandr -lXxf86vm -lXinerama -lXcursor -lrt -lm -pthread -ldl -I../deps/ ../deps/glad.c
运行结果: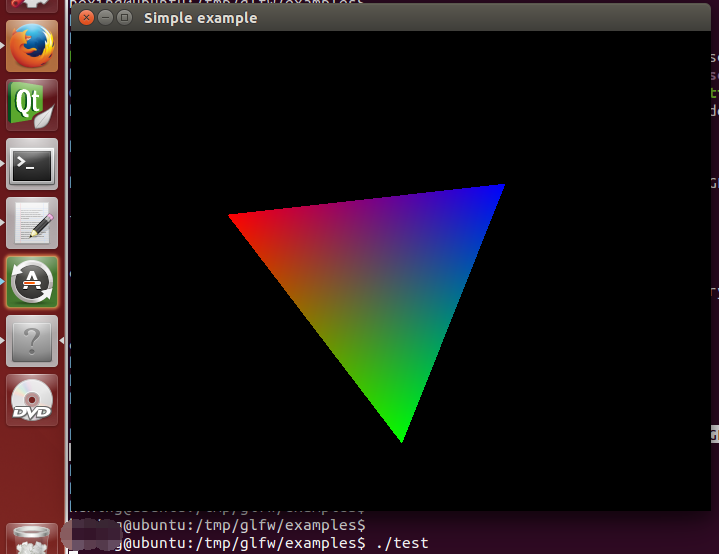
离线
感谢为中文互联网持续输出优质内容的各位老铁们。
QQ: 516333132, 微信(wechat): whycan_cn (哇酷网/挖坑网/填坑网) service@whycan.cn
东莞哇酷科技有限公司开发
东莞哇酷科技有限公司开发