楼主 # 2022-03-11 22:25:18 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 366
- 积分: 372.5
WCH的RISC-V居然跑出了3.84DMIPS/MHz的成绩...
测试了CH32V103和CH573的Dhrystone的成绩,发现一个非常奇怪的现象:使用-flto优化以后,CH32V103在8M主频时居然18.55ms就跑完了测试,性能达到了3.84DMIPS/MHz,这个成绩比ARM最新的Cortex-M33还要快得多,感觉可能性不大,同样8M主频,关闭-flto优化以后用时53.15ms,对应1.34DMIPS/MHz,感觉这个数据更真实一些,一个-flto优化不大可能把性能提高几倍,更大的可能性是-flto优化导致GCC哪里出错了。
附CH32V103和CH573的Dhrystone测试数据表格。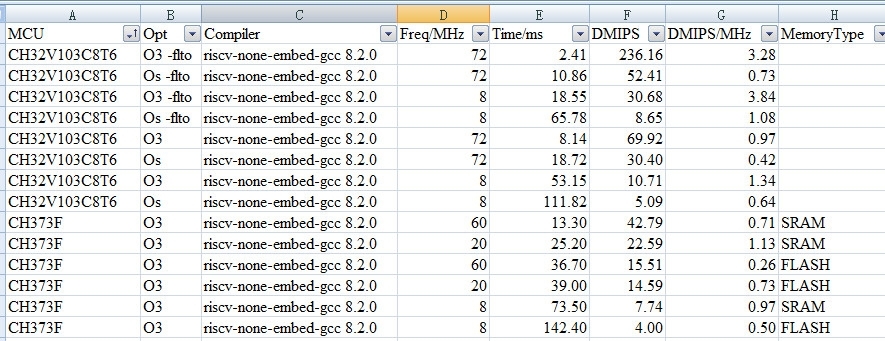
离线
楼主 #3 2022-03-12 09:31:26 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 366
- 积分: 372.5
Re: WCH的RISC-V居然跑出了3.84DMIPS/MHz的成绩...
abutter wrote:
Dhrystone 用强优化是作弊,所以现在很少做 CPU 的 benchmark。
试试 coremark。
开不开优化,结果差异巨大,不同编译器差异也巨大。ArmClang也是强优化,完全没问题。看起来是GCC的锅。
离线
楼主 #4 2022-03-12 09:42:32 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 366
- 积分: 372.5
Re: WCH的RISC-V居然跑出了3.84DMIPS/MHz的成绩...
aozima wrote:
换个版本编译器
目前WCH只提供了riscv-none-embed-gcc 8.2.0这一个版本的编译器,
实测GD32VF103使用的riscv-nuclei-elf-gcc 9.2.0没有这个问题,
更老的7.2.0也有这个问题。
离线
楼主 #7 2022-03-12 11:21:48 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 366
- 积分: 372.5
Re: WCH的RISC-V居然跑出了3.84DMIPS/MHz的成绩...
aozima wrote:
只要标准指令本身没特殊,就可以用通用编译器。
WCH对RISC-V指令有扩展,标准指令应该没有差别。还是丢给WCH让他们去定位吧。
离线
楼主 #8 2022-03-12 11:23:12 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 366
- 积分: 372.5
Re: WCH的RISC-V居然跑出了3.84DMIPS/MHz的成绩...
@Blueskull
那解释下同样的代码用nuclei 的9.2.0版本的GCC加-flto编译就没问题。到底是GCC不行还是clang不行。
最近编辑记录 echo (2022-03-12 11:25:14)
离线
楼主 #9 2022-03-12 11:30:19 分享评论
- echo
- 会员
- 注册时间: 2020-04-16
- 已发帖子: 366
- 积分: 372.5
Re: WCH的RISC-V居然跑出了3.84DMIPS/MHz的成绩...
@Blueskull WCH官方人员确认了GCC的这个问题。他们也是“持续关注GCC对此类问题的更新情况”
https://bbs.21ic.com/icview-3204494-1-1.html
而且有朋友也用7.2.0版本的GCC发现了同样的问题。
https://zhuanlan.zhihu.com/p/478423323
-flto选项对RISC-V还是很重要的,因为RISC-V的代码密度本身就非常拉胯
最近编辑记录 echo (2022-03-12 11:34:36)
离线
东莞哇酷科技有限公司开发