- 首页
- » 搜索
- » aquasnake 发表的帖子
页次: 1
#2 Re: RISC-V » 刚收到货的 诛仙剑 C-SKY Linux 开发板 » 2024-11-20 13:49:57
#3 Re: RISC-V » 刚收到货的 诛仙剑 C-SKY Linux 开发板 » 2024-11-20 13:46:05
#4 Re: RISC-V » 刚收到货的 诛仙剑 C-SKY Linux 开发板 » 2024-11-20 13:42:24
#5 Re: RISC-V » 国产riscv芯片汇总 » 2024-11-20 10:53:56
#7 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-10-27 19:50:08
again wrote:
@aquasnake
之前10K,16K的不是号称99%吗,这个2K的怎么差这么多
我怀疑agrv2k就是一个16K LUTs的cyclone IV clone.
内建一个RISC V的软核.极限跑200多M频率吧.只是猜测.
如果真的是软核,那就还有继续反向的动力,要是能更进一步皮角掉Supra的fitter工具,甚至能释放出完整的LUT出来
可玩性比安路更高,适合极客有具有完全脱离原厂支持以及有深度自我想法的开发者用. 如果商业应用,开发时间会比其他家的长点,主要工具链和SDK上不如别家做的完善.但是这些东西做太完善了就玩不出花了,如果你要以最小的系统成本,做尽可能大的活, rv2k可能有惊喜
同时,我希望能精简risc v部分,释放出部分LUT出来给PL用,能做到4K用户LUT,那就太好了
#9 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-08-21 13:55:53
瞬时启动以及上电配置时间超过500us, 无法胜任某些应用
这个芯片说是cpld,其实核心是fpga,而且瞬时启动没有做好,上电时间超altera, lattice等友商
上电延迟我用图表来表示不同方案的差异
传统altera, lattice的实现流程
power up VCC----LDO(fixed delay 200us)----POR(insertion delay 150-250us)----configulation and initialization time(
unknown, ???us)--->init done, GPIOs restore to user's setting
AGRV2K实现将ARM和CPLD的 POR都统一, 然后合并到外部的RESET脚,这个脚有上拉电阻到vcc,监视VCC实现启动延迟
但是问题来了,如果要将CPLD和ARM的POR都接到一起,那么只能按照最长上电需求的器件去做,显然CPLD这里不是卡时间部分,ARM才是那个需要更久上电时间的.而且内部还带了PLL, PLL输出LOCK后才能让ARM脱离RESET,因此估计PLL的LOCK信号内部也是通过与门连接进去了.
如果单独使用CPLD和ARM,CPLD会在ARM RESET之前完成它自己的POR和配置,即CPLD比ARM更早READY,按说应该采用这样的多芯片上电流程思想.
但是在AGRV2K,以上无法实现,CPLD的上电时间被ARM拖累,上电时间将突破500us,这限制了很多有瞬时上电要求的应用.
#11 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-07-13 12:26:09
关于非易失性配置的fpga/cpld的瞬时启动性能的讨论
我对这个指标特别关注,因为在一些用途中,必须要求fpga/cpld具有瞬时启动特性.
那么我来分析下怎么设计能尽量缩短master boot模式下fpga/cpld的上电配置时间.
一些原本基于fpga架构,然后使用spi flash设计的架构,它在boot的时候,要将spi flash先倒到内部sram中去配置,这种上电配置时间较长,因为spi flash无法片上执行.
一些基于并口nor flash的架构,上电配置时间几乎不存在,因为一上电就直接可以nor flash片上执行.
我怀疑rv2k就是内部的spi flash boot模式,因此需要上电配置时间.
上电配置时间的存在会带来什么问题?
在配置期间,fpga的gpio保持高阻态,开机后是无法立即驱动外围设备的.
但是原则上,fpga设计公司应该有一种方法,可以通过初始配置上下拉电阻,来让fpga配置期间内保持gpio的电平状态.而这种对pin脚上下拉电阻的配置,则必须写到内部nor falsh中(具有立即片上执行性能),也就是说,对于pin脚的配置,不能写到spi flash中,而应该写到boot loader代码部分的nor falsh中.
AMD总裁提出的5% rules哲学也包括了此类,也就是说,看起来两个差不多的东西,好的设计体现在95%以上的部分.而好的应用,在于你是否用到了95%以上
#13 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-07-11 12:01:55
OD和上拉配置应该这样设置:
define open-drain output pins
set_instance_assignment -name ENABLE_OPEN_DRAIN -to PIN_XX~output true
define pull-up pins
set_instance_assignment -name WEAK_PULL_UP_RESISTOR ON -to PIN_XX
现在我已经抛弃了SDK那种在用户项目之外再套个顶层的代码架构,退回到ag1280那种传统.保持用户顶层的可编辑性,这样管脚配置输出z不会因为模块间接口传递的问题都丢失
基本上已经调通,但是距离量产还有距离,还有不少坑.
无法完全替代MAX II或Lattice MACH XO2
主要以下几点要求比较苛刻:
内部 RC-OSC对电压要求苛刻
芯片上电配置时间比友商的同类规模cpld长
内部PLL的LOCK稳定更加长了上电配置时间.
所以,保持最高可移植度的使用方法是,不要去用他这个RC-OSC, 最好不要去用PLL.
当然,用来代替小规模fpga使用是没有问题的,因为本身FPGA配置时间就相对长. 但是如果是之前作为cpld使用,而cpld是master设备的话,这个上电配置时间必须有要求,它只能满足于小于外围被测量设备的上电时间.
#14 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-07-07 09:20:42
为什么无法定义pin脚输出z的猜测
我试验了在我项目module里对一个output变量直接赋值z,传递到顶层相应pin脚是可以的。
但是如果写的复杂点,对这个output写一个判断的逻辑,例如a = b ? 1'b0 : 1'bz;
然后top里面对这个module调用,参数传递过去后逻辑就改变了。
原则上综合器并不会接受这种写法,固定的z能传递只是因为是固定值z,综合器把一个wire型变量赋值固的z,优化为unused,因此传递到顶层,真正的物理pin脚就理解为不使用,不使用的io默认状态就是z。
但是如果是有相应逻辑而非固定z,那么在其他module中的端口wire型变量赋值组合逻辑表达式中出现z就会被传递错误的值,通常综合器碰到含有z的逻辑表达式直接理解为false,那么这个wire型端口传到顶层就是0。
因此,rv2k sdk中将用户module之外再套一个top层的自动代码,我真的有点反感,因为你要定义含有z的组合逻辑到一个io,你必须写到顶层,只有顶层才是真正对物理pin脚做定义。那么这个自动产生的top module,到头来还是要手动去改,于是自动生成的top顶层意义在哪里?
因此还是回到前面的贴子中所提出的观点,我还是需要对项目文件结构做一个重写,顶层自动分配pin脚这种方法,是有问题的,应该做根据用户顶层而产生 .asf的自动python脚本,而不是去将用户module之外产生一个top.
#15 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-07-04 16:40:47
RV2K到底能不能支持weak pull-up端口IO配置?
在logic_design.asf(默认top.asf文件)中把需要的pin脚设置上拉
set_instance_assignment -name WEAK_PULL_UP_RESISTOR ON -to PIN_xx
然后重新全部跑一遍logic的综合和fitter
下载后实际开机运行结果并没有上拉
在.\Supra\etc\af_quartus.qsf中开放全局上拉设置
set_global_assignment -name WEAK_PULL_UP_RESISTOR ON
然后重新全部跑一遍logic的综合和fitter
下载后实际开机运行结果还是并没有上拉
代码都是原来跑在altera max II系列上的同样代码
由此,我怀疑,RV2K的fitter是否真正能配置weak pull-up?
#17 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-07-01 10:54:01
还有一个告诉fitter配置成OD输出口的约束
在.ve里面,logic配置output(或inout)口后面加限定!PIN_xx_out_data
这个方法我还没有检验,这个是直接把io的输出口的上mos管直接干掉,不管你verilog怎么写,哪怕你写了输出1,这么干了以后,输出1等于Z,同样,如果驱动脚外面没有上拉电阻的话,内部最好配置弱上拉,因为Z的作用,其实是降功耗,而不是意图让后级或总线电平悬空。
公开release版本的supra或者AgRV_pio SDK,在默认全局约束(__design__.qsf)里面还有一些需要客户根据自己项目修改的,按照官方release出来的设置,产生的自动化quartus项目,跑出来部分管脚是不可使用的
#18 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-06-30 15:28:39
RV2K到底能不能支持open-drain输出配置?
在Supra\etc\__design__.qsf中
修改这一行set_global_assignment -name AUTO_OPEN_DRAIN_PINS OFF,将OFF改为ON
在Supra\etc\af_quartus.qsf中
增加这一行set_global_assignment -name AUTO_OPEN_DRAIN_PINS ON
重新生成项目文件,重新跑综合和布局布线
成功生成top.bin后,打开.\alta_db\alta.asf
可以看到部分OUTPUT PIN已经被设置成OD门了
前提是,因为他是自动根据综合器网表来生成的,所以Verilog代码里面,要将OD输出的PIN的高电平,写做"Z",这样配合上拉,即可以认为是1,但是功耗会比直接输出1小的多(如果前后级电平之间有压差的话),而且系统抗ESD性能也会略好些。
OD输出配合内部弱上拉,将可以有效降低系统的静态功耗,以及减少总线冲突。一般用于总线上存在两个或以上的驱动源,以及总线前后级(源端到目的端)IO电平有压差的情况下。
#20 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-06-23 21:53:16
接下来说说agrv2k最大的开发环境上的坑
1。PL部分没有自己的IDE,交叉使用supra和quartus,会丢失大量的初级用户,尤其是高等院校学生以及创业公司选用的考虑。虽然个别钉子户老顽固和开源社区是很喜欢这种基于命令行的toolchain的。此处评估拒绝了市场1/3的新进客户。
2。PS开发选用的platformIO,不得不说,这绝对是对于客户而言最失望的开发环境。而且对操作系统耦合极其强,要求win10之后。此处评估拒绝市场1/2的客户。甚至platformIO插件的安装文件夹还随时在被监视,一旦发现被修改,远程即强制你更新(重新安装,而且一更新安装即是1小时!除了360,我从未见过如此厚颜无耻之徒! 这也就是为什么PIO要求有最高Admin管理员账户权限的原因!很符合流氓特征)。虽然vscode+platformio界面看似很fashion,但是我却完全鄙视,又臭又长的东西。哪怕是cmake都要比之好10倍,更不用说keil以及其他针对嵌入式mcu的IDE了。
3。python选用版本过高,越高的python版本,意味着对windows的版本选择面越窄。虽然github上有针对win7(及以前)OS的皮角兼容DLL(呵呵,这个皮脚库其实某为内部也在用),但是对于新进客户,这将强制他们电脑系统升级到WIN10以后,在一些中大型企业中,这是绝对不能接受的!结合2,此处评估再次拒绝市场1/4的客户(尤其是大客户)
最终客户接受率估计:2/3 1/2 3/4 = 1/4
这也就是为什么我一开始就下决心要抽取SUPRA,弃用PlatformIO,自己造轮子搭建Toolchain的初衷。supra很符合开源精神,bin文件夹内的exe都可以命令行调用。PlatformIO虽然源自于开源社区,但是走在背离开源的路上(无责任猜测可能M$有背后塞金资助了,而且强推的很厉害,甚至连一些培训机构也在推广).y有时候,我仅仅需要一个轻量级别的,跨操作系统(以及跨版本的),可裁减自由定制的,拥有充分脚本扩展性和编译控制的非集成开发环境。
#22 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-06-22 21:43:00
1847123212 wrote:
aquasnake wrote:
换一个超低压降ldo,或许对校准精度有惊喜。
现在我不用改电路了。:)
为什么还要低压降啊?
官方建议3.3V后面接一个功率磁珠。我的供电是5V,然后我校准供电在ldo之前,但是jlink输出电压3.3V.这样经过一个ldo的压降就满足不了校准的需求,神奇的是除了校准,下载其他都是无问题的。
如果改板,把校准输入电压接到LDO后端,就可以了。但是这个时候,必须要保证板子不能供电。但是校准电压vcc不一定是实际工作时候的vcc.也就是说,校准相对不准。
如果改JLINK,输出5V,就不需要改板了。直接接到LDO前端,这个对校准还有好处,就是校准电压vcc就是实际工作时候的vcc。
不改JLINK,不改板,只替换ldo用超低压降的(vdrop min 0.2V),就能直接兼顾3.3V输入和5V输入。在 3.3V JLINK供电连接下,虽然处于LDO吃不饱状态,但是只要过OSC校准和下载即可。实际工作是输入5V
这就是超低压降LDO的实际作用。
#24 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-06-15 13:57:42
POR与GSR设计
POR上电即是设置的默认值,判断芯片第一次上电,可以通过读altpll这个硬IP的.locked输出信号获取状态。但是cpld无法得知硬件脚nRST的此刻状态,很可能PLL输出已经locked置位,但是MCU的nRST还没有为1(尤其是nRST脚并联一个电容的情况下)。因此,需要MCU里面boot代码开始对某个地址寄存器写状态位给CPLD。CPLD读这个寄存器(RAM)获取。
GSR仅是针对CPLD的,低有效,一旦为低,CPLD寄存器全部恢复为初始态。
AGRV2K似乎并没有GSR控制脚。因此可能需要设计一个input脚然后另写reset process block。这将降低实际CPLD的使用效率(额外占用LUTs)。
AGRV2K并不如MAX II/V以及MACH XO2好用。尤其要判断第一次上电以及已经上电后再次reset的不同状态的应用情况下,AGRV2K要写更多的初始化代码。
#25 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » 盗版CH340的被判刑了 » 2024-06-06 09:14:39
#26 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » 盗版CH340的被判刑了 » 2024-06-06 09:09:15
#27 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » AI是否能统一硬件设计行业? » 2024-06-06 08:50:26
就@海石生风天真派以为有外包厂,有自动工具,就万事大吉了,他一个做软件的自我感觉良好了,觉得自己可以full stack了.
我就问你,你到底懂不懂硬件设计?
吃素不吃荤,吃荤带吃素
同样,懂硬件的要懂软件,但是懂软件的就不懂硬件. 硬件设计gpio定义和周边通信,必须要查阅datasheet然后还要出给驱动工程师io分配表,适当的时候还要写这个文档. 软件工程师他要改io,大多数都要求硬件去改,极少可以不依赖硬件自己在gpio初始化分配表上修改的.为什么呢? 把工作推给别人做,少承担责任,比自己搞定要省力的多.硬件经常帮软件擦屁股,软件可不会给硬件兜底,出了问题全赖硬件,要重做一版!
#29 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » AI是否能统一硬件设计行业? » 2024-06-05 06:55:00
ai可以应用到商场,导购,宠物机器人,点餐等,以上这些应用,可以有足够的范本参考,即使获取答案出错,也问题不大。
但是做一个一百万种可能中只有一条正确路径的逻辑问题,ai确实不行,ai无法搜索匹配到答案。这种工作就是逻辑编程,注意逻辑编程不是软件写代码,写代码其实是逻辑编程中前端工作,而且是占用时间最少的过程,一个代码,写出来的时间远远小于调试时间。调试就是电影《原代码》里面不断出错一次又一次尝试直到最终通过的无数次试探。 找到代码范本,只要能连网搜索可以到处找的到,但是要让这段代码嵌入到自己项目中并调试出来,才是真正的功力所在。
很多小白觉得,他fork别人一个代码库,就认为他胜任了他觉得都是可以这么抄出来了,但是抄是最不缺乏的也是占用开发项目最小的工作。参考别人项目,移植进来可能需要1-2天搞定,但是要调通,或许10天半月都未必。
如果仅仅认为通过ai能找到范本,那他的水平大概也只能是在抄的阶段
#31 Re: Xilinx/Altera/FPGA/CPLD/Verilog » zynq7010/7020核心板众筹openzynq » 2024-06-05 02:23:26
差不多15年的时候搞了一点点机器视觉,虽然当时有点吹过火(现在也一样我认为是在吹)
双目深度视觉检测,通过像素差异,比较得到照片中央和边缘的像素偏移然后计算出拍摄物体和摄像头的之间的距离。硬件也没有什么特别的,fpga+两个摄像头。其实用手机芯片更合适,我从那时候到现在一直这么认为。
机器视觉的深度检测,到现在我还认为仅仅停留在实验室,离获得生产力太远,甚至在应用上,无法实现最后1英里突破,即面向终端用户能给他们带来什么。而大多数都是提供一些互联网公司作为招商项目,此类项目不一定是真正用于产品提高生产效率,而可能仅仅是给投资人演示获得追加投资。
因为这个行业太多的骗子以及小人,我是不会去和某些人辩论,我只会用一种特殊的,释放某些一些人自以为是看家宝的东西,成为毫无价值的public domain
#35 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » AI是否能统一硬件设计行业? » 2024-06-03 23:39:28
ai不会有什么突破,目前的ai只是基于大数据搜索的自动写作文器,他能写小作文,当然可以回答问题,回答你的都是搜索到的东西,有些东西还是错的废话连篇。
下棋目前是ai最合适的方向,因为棋盘是有限约束条件,这个有限大概是64格加上棋子的权重计算,总能算出一个最佳走步。
恩,其实fpga的布线器有点类似ai,也是通过尝试不同方向上的布线生长,来获得一个最佳走线路径,当路径走不通的时候回退再尝试另一组,不断尝试,直到最终走通。当然前提是人工需要设置好约束条件。但是通常来说走不通的概率还是很大的。 pcb layout就发散性更高了,因为还有间距的空间约束,而这个约束相对于板子面积来说,可以尝试的可能性太多,软件无法完全遍历,所以pcb layout算法并不是遍历算法,它是一种步步为营策略,它限于运算的空间和时间消耗,只能提供有限回退。
我的结论是,ai完全无法代替人工,在约束条件超过一张棋盘格的数量下。而在eda软件中,约束条件超过一个棋盘格子数量是在正常不过的了
#36 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-05-31 13:52:25

看起来fitter无法使用altclkctrl这个ip库,只能单时钟。这样就需要自己写多时钟切换代码。
逻辑很简单,在pll没有lock之前,使用HSI时钟,等PLL LOCK后,使用变频后的时钟。
自己写比较麻烦,简单的multi-plexer会有switchover glitch,一般用需要等pll lock后再加几个clock然后才能保证避免这个glitch。目前我的系统作为从设备需要检测master一个时钟输出6个clock后就要响应。
或者永远不要等PLL LOCK信号,哪怕PLL变频后一开始一段不稳定,也接受,也不切换,直接使用PLL输出,这样CPLD可以加快PLL上电瞬时性
#38 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » 有没有人想创业? » 2024-05-27 00:22:04
lcfmax wrote:
把白嫖说的这么清新脱俗,应该销售出身的吧
bingo
他就是想白飘个方案,听上去还向个小学生,看注册id和发贴量,完全不能让人对他有任何信任度. 这年头随便注册个临时账户,忽悠一下创业,就能免费获得方案了吗?
这么容易吗?真的吗?
你怎么不先墨迹个一年半载把东西板子搞出来先,再放twitter, kickstarter,taobao,咸鱼上就好了.
不能墨迹半年以上的,自己没有技术的,也没有资金的,更不要说渠道的,你创业个毛啊,说出来让人笑,白飘就白飘了,态度好点,真切一点,就说讨要个nas的方案,说不顶某大老就甩一个sourcecode和硬件pcb给你了.关键你够诚实吗?
#39 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-05-25 14:19:50
关于cpld端获取不到sys_clk的问题
在自动生成的顶层verilog代码中,定义了以下接口:
alta_gclksw gclksw_inst (
.resetn(sys_resetn),
.ena (1'b1),
.clkin0(PIN_HSI_in),
.clkin1(PIN_HSE_in),
.clkin2(PLL_CLKOUT[0]),
.clkin3(),
.select(sys_ctrl_clkSource),
.clkout(sys_clk));
这个接口的功能是系统时钟选择. 主要看输入项参数sys_ctrl_clkSource决定
在alta_sim.v中:
assign sys_ctrl_clkSource = {2{sys_ctrl_pllReady}};
意思是无论如何,只会选择2'b00或2'b11,即clkin0或clkin3. 以PLL锁定输出信号决定.
实际上正常工作应该选择到clkin2(PLL_CLKOUT[0]),由此cpld获取不到正常的sys_clk
应该改写为以下:
assign sys_ctrl_clkSource = {sys_ctrl_pllReady, 1'b0};
#41 Re: RISC-V » RISC-V代码密度相比Cortex-M差距明显 » 2024-05-22 14:13:02
不同链接库,无法同日而语.
当然,库本身精简一下是可以压出很多空间来的,有些库可以裁减
#44 Re: RISC-V » RISC-V代码密度相比Cortex-M差距明显 » 2024-05-20 13:31:08
#45 Re: RISC-V » RISC-V代码密度相比Cortex-M差距明显 » 2024-05-20 13:28:37
#46 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-05-18 13:50:10
关于RV2K能否只用CPLD的讨论
最早我问代理,给于的回复是完全可以拿它当一个纯CPLD来用。不过我总觉得似乎必须要带上片上总线AHB,即使不连接MCU不做任何事情。
在自己的项目模块中加入一坨:
`ifdef AGM_RV2K
input sys_clock,
input bus_clock,
input resetn,
input stop,
input [1:0] mem_ahb_htrans,
input mem_ahb_hready,
input mem_ahb_hwrite,
input [31:0] mem_ahb_haddr,
input [2:0] mem_ahb_hsize,
input [2:0] mem_ahb_hburst,
input [31:0] mem_ahb_hwdata,
output mem_ahb_hreadyout,
output mem_ahb_hresp,
output [31:0] mem_ahb_hrdata,
output slave_ahb_hsel,
output tri1 slave_ahb_hready,
input slave_ahb_hreadyout,
output [1:0] slave_ahb_htrans,
output [2:0] slave_ahb_hsize,
output [2:0] slave_ahb_hburst,
output slave_ahb_hwrite,
output [31:0] slave_ahb_haddr,
output [31:0] slave_ahb_hwdata,
input slave_ahb_hresp,
input [31:0] slave_ahb_hrdata,
output [3:0] ext_dma_DMACBREQ,
output [3:0] ext_dma_DMACLBREQ,
output [3:0] ext_dma_DMACSREQ,
output [3:0] ext_dma_DMACLSREQ,
input [3:0] ext_dma_DMACCLR,
input [3:0] ext_dma_DMACTC,
output [3:0] local_int,
`ifdef INT_OSC_SUPPORT
input int_clk,
`endif
`endif
然后还必须定义AHB总线待机
`ifdef AGM_RV2K
assign mem_ahb_hreadyout = 1'b1;
assign slave_ahb_hready = 1'b1;
`endif
AHB这两个信号在内部片上总线结点必须设置为高,如果不定义,悬空或者为0都将FIT不过。why? 为什么不设计的时候内部直接weak pull-up??
不知道有谁完全不带AHB就正常当cpld使用并调通的?
#47 Re: RISC-V » RISC-V代码密度相比Cortex-M差距明显 » 2024-05-18 10:45:22
#48 Re: RISC-V » RISC-V代码密度相比Cortex-M差距明显 » 2024-05-18 10:38:19
#49 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-05-18 09:45:24
AGM RV2K? 紫光PGC2K?高云Tang Nano 4K? 同台竞技
这三个都是6K LUT以下基于片上flash配置的瞬时启动CPLD的同一性能档次。
从易用性,开发友好度来说,PGC2K ~= Tang Nano 4K > RV2K
从市场采购渠道来说 RV2K >> PGC2K ~= Tang Nano
从toolchain的定制性,做差异化挖掘技术深度来说 AGM的工具简直就是Hacker最喜欢的,它等于50%皮角了quartus,而且是以命令行方式,可以集成进不同项目脚本
另外两家用的是Lattice类似的IDE,从管脚分配模块界面上可以很容易感受到Lattice的风格,完善度做的比较好,前期开发比AGM友好。
紫光预测市场化应该要比高云做的出色,高云很难真正把基于lattice的方案替换掉
#50 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-05-18 09:13:22
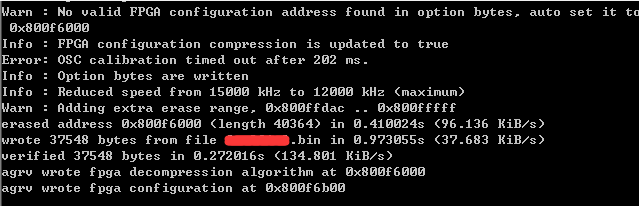
fitter效率90%的问题再次跟踪
修改两个地方
1, gen_batch脚本中找到以下这行:
logic_compress = (logic_size < (0xa000-LOGIC_ALGO_SIZE))
修改为
logic_compress = (logic_size < (0xb000-LOGIC_ALGO_SIZE))
2, af_run.tcl文件中找到以下这行:
--logic-address 0x80007000\
修改为
--logic-address 0x80006000\
以上给CPLD bin空间多分配4K以充分使用CPLD
原因是脚本限制了cpld bin size,而且脚本默认是产生加密bin,加密bin需要更多的size。如果不改,当cpld使用到超过90%就会bin超标,窗口会显示error,但是仍然生成bin。而这个超标的bin写到片子里面肯定是无法工作的
#51 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-05-16 08:24:40
RV2K的sdk实际上对于端口配置做的一点比较复杂的自动化代码。
先是用python脚本,把项目的verilog代码做了一次再封装,产生一个更高级别的顶层接口,然后把管脚定义在这个顶层接口了(我非常反对这种做法,理由下面会分析)。
接口封装了CPLD和MCU衔接的AHB总线以及DMA和他们之间的握手信号。到此为止是很好的,但是把PIN脚映射再次封装成一个更高级别顶层。这虽然解决了PIN脚配置问题,但是造成了另一个问题:
比如我换了项目的PIN脚定义,我不能简单地修改.ve,因为fitter不看.ve。你必须要重新跑一遍gen_vlog脚本产生顶层接口,然后再次重新编译项目,包括综合和布局布线全部都重来一遍!
我在想把PIN脚映射从gen_vlog剥离,直接自动化代码产生在.asf文件中,这样更改pin脚定义就不需要重编了,只让fitter看.asf就好了
很多用户在需要改pin脚的时候,都会误以为只需要改.ve文件就好了,最多重新跑一下全编。但是不行!你必须重新做初始化产生自动化代码,必须要跑gen_vlog。而gen_vlog这个环境配置,需要你重新建立一个工程,quartus工程.qpf重新产生后某些配置你必须重新再次设置(类似项目代码需要重新添加,设定verilog版本标准,再次配置仿真工具等)。尤其在类似PIO这种集成环境里面,会搞的更繁琐。我的做法是直接把gen_vlog调用写成批处理一键运行重新NEW一把。
当然,最彻底的改进是不要把pin脚映射做成顶层接口,而是让脚本自动产生.asf文件
#52 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-05-14 15:45:06
注意,仅仅是写了.ve文件中的管脚映射,也是不会导入到fitter控制中去的。
在"af_prepare.tc"中:
Run Compile
set PIN_MAP "__device_pinmap__"
set VE_FILE "__ve_file__"
if { [file exists $VE_FILE] && [file exist $PIN_MAP] } {
以上必须满足同时有.ve文件和.pinmap文件才能产生正确的.pre.asf
遗憾的是,SDK里面并没有给你包含AGRV2KLxxx.pinmap文件,这个脚本非常罗嗦,绕了一大圈最终有.asf控制,什么pre.asf都是中间临时脚本,最后统一被.asf覆盖。
而且完全可以删除xxxx.pinmap这些文件,也就是说,不管quartus ii里面的逻辑管脚映射如何,都没有意义,最后物理分配看.asf文件。甚至删除了pinmap文件还更有好处,我不需要先在quartus里面对着一个模型bga封装去虚拟分配管脚了,哪怕它是空的,也完全没有关系,彻底把管教配置和quartus剥离干净
#53 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-05-14 15:19:37
我看了几个例程,就是学生作品,把实际的物理管脚直接写到了verilog模块里面的输入输出IO上了。
这种写法,不具有模块化,耦合很强,移植需要改写很多文件。
当把IO替换成自定义信号后,fitter就丢失了管脚分配。但是fitter不会强制出错,会给你默认按管脚顺序分配,只给出warning,会顺利产生bin,当你用这个bin烧写到片子里面,管脚定义是不对的,上去很容易烧片子。(废话,假设输入被定义到输出,不就io大电流了) 这很危险。
我彻底改写了框架,要么自己写一个AGRV2KLxxx.pinmap映射表让脚本产生正确的管脚分配,要么直接粗暴地在.asf文件中定义管脚。因为.pinmap文件也只是管脚映射,没有其他上下拉,驱动力等的设置,最终也是要看.asf文件。
至于.ve,实际没有多大用处,可能对于MCU的代码有意义,类似一个define,但是管脚分配在AGM内部,尽然涉及到了3个地方(.ve,.pinmap,.asf),拉扯到最后甚至绝大多数用户都不知道怎么定义管脚!
#56 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » 是时候告别CSDN了! » 2024-05-14 10:34:49
#57 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-05-13 14:24:27
其实调用 quartus综合也可以一键批处理化
新建一个文本文档改后缀为bat文件,里面是
path = path;C:\altera\13.1\quartus\bin64
quartus_sh -t af_quartus.tcl
pause
这样就可以了。前提是先安装quartus II 13.0或者13.1
然后观察.\simulation\modelsim目录下是否产生了最新修改时间的.vo文件,有则是综合通过。
但是综合用批处理比较不直观,不能看到到底占用了大致多少的芯片资源(LUT),不适合在开发中使用,用来出版本合适。如果是前期代码编译开发,还是开quartus IDE界面比较好。
但是在fitting的过程中,会有资源占用比例显示出来,其实显示资源占用比放在综合脚本里面显示比较人性化
写脚本的方便之处是缩短了编译时间,也不用手动去选.tcl脚本,防止点错脚本。这样一键傻瓜操作,加速了对工具使用的适应磨合时间(大多数开发者,开发一个新项目开始,几乎要占用3-7天搭建环境,适应环境,并琢磨出一套开发流程,直接命令行的调用环境效率提升很明显)
#59 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-05-11 13:36:34
如果用开源的综合器产生网表,那么要做的事情很多,需要手动写 *asf
先借用quartus ii跑一遍,跑之前先assignment editor配置好虚拟的管脚约束,然后点af_quartus.tcl运行产生网表,以及altera的.qsf文件。然后跑一次fitter,会自动将altera的.qsf迁徙到AGM的 .\alta_db\alta.aqf, .\alta_db\alta.asf
但是,这两个约束并不是最终的,最后,将ur_project.asf里面的设置再次覆盖,所有的参数都是altera quartus ii里面的,因为他这个fitter是衔接quartus ii的。
假设用第三方开源的综合器产生网表,但是这些文件并不会导出,也不会是quartus ii的参数,因此会出现丢失pin脚约束和其他全局约束的情况。fitter还是会调用 .\alta_db\alta.aqf, .\alta_db\alta.asf 去约束,而这几个都是quartus ii环境下的,它与quartus ii强耦合
最乐观的情况是你上次成功编译后管脚约束是正确的,你又会手动编辑ur_project.asf。而且你的项目对于pin脚约束(上拉,OD,驱动力,滞回,延迟微调整等)不敏感
#62 Re: RISC-V » RISC-V不支持非对齐地址访问非常坑 » 2024-04-08 00:00:33
#63 Re: RISC-V » RISC-V不支持非对齐地址访问非常坑 » 2024-04-07 23:54:44
#64 Re: RISC-V » RISC-V不支持非对齐地址访问非常坑 » 2024-04-07 23:49:46
#65 Re: Xilinx/Altera/FPGA/CPLD/Verilog » 分享一个CH552可用的USB-Blaster固件 » 2024-04-07 19:30:21
echo wrote:
@jameschen
有什么理由必须要用Quartus II 18吗?ALTERA卖身好久了,市面上常见的新的器件差不多就是Cyclone4?13.0 sp1完全可以支持,老器件也是13.0sp1支持比较好。所以没什么理由用更新的Quartus版本
我一般都是把新工具降级去支持老系统,在一个系统稳定的情况下,不会刻意为了升级而升级,升级带来了一系列非预期的环境变化,没有意义的事情,升级通常只会吃掉更多系统性能,而原厂希望客户升级,因为可能涉及到一些ip产权的变更,一些合作供应商的替换,原来集成在ide里面的供应商组建需要替换.但是对于最终用户,没有这种顾虑
#67 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-04-03 19:27:44
@jiaowoxiaolu
因为控制字写在 ur_project.qsf文件中,这个文件其实也是一个脚本,会被af.exe调用
然而约束控制字都是altera的东西,你甚至可以在altera的工程目录下找到类似的.qsf文件,然后把需要约束的管脚配置字,摘抄过来
为什么agm不公开这些?因为这些东西是altera/intel的,quartus ii中用户不必关心.qsf文件,直接在assignment editor中有配置,配置完毕后会自动更新.qsf。而在agm中,是直接编辑这个.qsf文件。
我一开始也尝试去向供应商询问这些东西,但是基于某些原因,没有获得我需要的解答,因此都是自己慢慢啃生肉。当然,在此过程中已经了解为什么会不解答这些技术问题。因为这涉及到agm对altera的软硬件做了什么的问题,这些问题是不方便原厂自己公开释放的
#68 Re: 全志 SOC » 有偿求助,有一份从spiflash内dump出的(UBI)rootfs,我自己添加了东西后如何从新再打包成原来的UBI文件系统 » 2024-04-01 11:04:56
Gentlepig wrote:
那么,有什么办法防止从spi nand里读出rootfs呢?
总线xor加密,但是spi flash最好选qpi的,这样4bit data总线还能错乱一下并和一个固定字做xor,如果是标准spi,那么无法xor,除非在spi的协议上修改,做成私有协议
以下谈点个人对皮脚,加密的看法,所高级的加密就是让皮脚的人觉得他已经皮脚了出来。也就是说,不要完全封闭,不要让人dump出来一片空白,就是要能dump出来,ida pro后还是有意义的程序代码,这段代码还能开机,运行,测试短期内甚至跑起来还不错。但是,却不能让它长期稳定跑。
皮脚可能是找的第三方解密公司,他们不会给你做长期测试,也就2-3天内简单测试一下就交付了,好交付给某个老板,某个老板觉得已经dump出来了,于是开料投产,投产后顺利上市,然后出货后等个把月,就出现机器异常问题。这是最具有杀伤力的。简单完全封闭,皮脚的老板碰到钉子就觉得对方是和狠货,也就没有信心再皮脚了,就是要装做无辜小白,让对方觉得已经被拿捏住了,然后再来坑他一笔大的,叫他投资打水漂
#70 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-04-01 10:32:18
agm的toolchain其实是属于外挂,对quartus ii做了一定程度的注入,migration以后产生的quartus ii的工程文件,然后就是利用quartus ii综合,此时需要运行agm的外挂脚本(af_quartus.tcl),脚本中把综合的约束条件自动注入综合器(它会覆盖原始quartus ii中的综合setting优化设置),产生网表
然后执行agm的fitter(af.exe)去布局布线,此时注入fitter的约束条件,同时根据.ve的pin脚分配产生bin。
在利用quartus ii做综合的的时候,一旦运行了agm的脚本,如果再次去修改ide的全局综合优化设置,就会改变外挂之前设置好的参数,所以,一旦运行脚本(af_quartus.tcl)后,就不建议去做其他setting修改,这会导致产生一些非预期的问题,唯一能做的就是点箭头start compilation
如果你在次过程中,不慎修改了setting,那么最好还是再次运行一下外挂脚本(af_quartus.tcl)
由于是外挂,因此步骤上是必须严格按照顺序的,点错了,或者中间修改了ide设置,都有可能破坏注入参数
#72 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-03-29 12:19:15
fitter效率突破不了90%上限的问题,可能是无法解决的,我试图编辑.qsf文件的约束参数也没有什么优化,基本上原厂提供的配置就已经到达极限了。 也并非的工具的问题,我发现agm用的约束参数就是quartus ii兼容的(这里面很奥妙),cyclone 4架构或许就是需要剩余一部分面积才能布局布线走出来,而阉割到2K或许无法保证剩下的10%的面积连成一片,零散的10%的面积或许就是无法利用起来的,甚至无法插入一个锁存/触发模块
基于LUT结构的FPGA,Verilog代码需要写的尽量对称,所谓对称,就是if或者case语句内尽量具有相同的表达式结构,越对称,便于合并相同逻辑,综合的效率越高。同时尽量把case的所有分支都填充满,条件越详细,反而综合后分配的LUT越少。
虽然fitter的优化约束无法扣出资源,但是在综合这个步骤,通过改写代码,统一表达式结构,同样扣掉了几十个LUT出来,以前我做IC设计bring up时候的痛苦回忆又回来了,要跑通一个优化的配置,可能需要跑上百次verification. 通常效率最高的时候是在半夜,这个时候没有人和你争服务器job现程。而在白天,比如在一间科技公司,几百号人争夺代码服务器上的cpu资源,通常很难跑的快
#74 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG RV2K 调试 » 2024-03-27 10:46:14
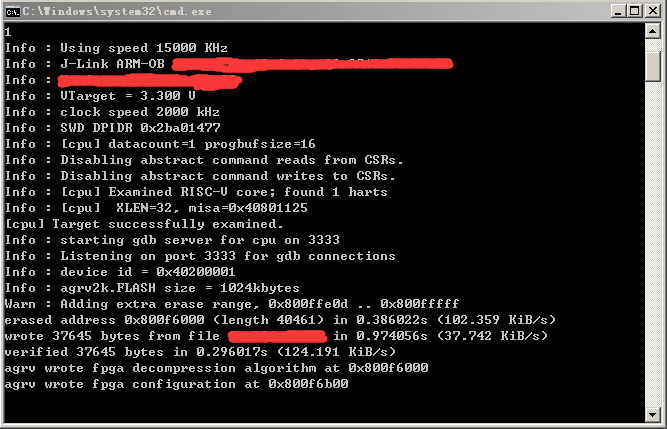
int OSC calibration失败的原因已经解决,对Jlink-OB下载线的vcc 3.3v供电很敏感. 偏差0.5V都不行。
我因为通常习惯在jtag调试器对target板供电为了防止反向灌流加个二极管,由此导致了vcc的压降,造成校准失败。
虽然我已经让校准通过,但是我对校准精度不报大的期望,当然,这个内部晶体时钟我只用来对信号延迟计数用,并不涉及其他,请不要学我,我任何时候都是把器件用到很抠门的地步,能省一颗料则省。
最后还是希望agm在这里对内部晶体供电做一个补偿,是否考虑内部供电统一安排到2.5v vcc(vddio除外),以便当用户在使用欠压下载线的时候能够保证内部晶体的稳定
#76 Re: RK3288/RK3399/RK1108 » 为什么瑞芯微公开资料这么少呢 » 2024-03-26 17:20:23
#77 Re: RK3288/RK3399/RK1108 » 为什么瑞芯微公开资料这么少呢 » 2024-03-26 17:14:18
#78 Re: RK3288/RK3399/RK1108 » 为什么瑞芯微公开资料这么少呢 » 2024-03-26 11:06:37
#79 Re: RK3288/RK3399/RK1108 » 为什么瑞芯微公开资料这么少呢 » 2024-03-26 10:53:13
#80 Re: RK3288/RK3399/RK1108 » 为什么瑞芯微公开资料这么少呢 » 2024-03-26 10:15:09
#81 Re: RK3288/RK3399/RK1108 » 为什么瑞芯微公开资料这么少呢 » 2024-03-26 10:03:42
ncer wrote:
@echo
卖产品,是要直接跟客户对接的,客户对你有要求十分正常
我就想问,个人用户是直接找芯片厂家买的芯片吗?
有些你说要买人家还不卖,要你提供公司名字,营业执照,开户行账号等等,你总不能为了要点资料就自己注册个公司开个企业账户还存进去一笔钱吧?对,某些企业的财务还会找银行核查企业账户资金,还会做背景调查查你公司的信息(当然现在网上也能查到了),查你公司规模组织架构投资者关系,查股权变更信息查有无法律纠纷等等,这一论背景调查后,觉得ok的,来签个NDA
哦,有些签NDA还有附加条件的,就是必须购买一定数额的芯片,行业叫做入门费,可以交钱货暂时留存在原厂或代理商那里,等哪天提完这批数量的货了,入门费再从以后的提货芯片购买价中打折陆续返还。
这些都是对小客户以及终端散户的限制,原厂用这些方式来筛选出符合他们要求的所谓的“大客户”,对于大客户,可以甚至直接给他们出设计,包括硬件电路设计PCB LAYOUT以及软件配套开发。
所以其实行业就是这么肥事,有些东西真的不是靠技术,人家根本不看你公司里面有没有技术牛比的人,而是看你老板有没有马内,有马内了,原厂给你包工包料做好了给你,只要你有市场渠道卖的出去就好了
#82 Re: RK3288/RK3399/RK1108 » 为什么瑞芯微公开资料这么少呢 » 2024-03-26 09:50:45
只要厂家提供文档,而不需要厂家技术支持。有问题,我更喜欢去社区寻求解决(而不是找原厂fae)
一个成熟的社区远比厂家fae更有作用。厂家只需要负责产品,文档提供。不需要对最终客户1对1的支持,真的不需要。厂家只要对top 10大客户自己支持就够,余下给到代理支持,至于个人玩家,diyer,学校的毕业设计的学生都不是厂家需要去技术支持的对象
但是对大客户支持不代表就拒绝小客户甚至终端开发者,如果这些人找原厂,应该指导他们寻求代理或者某些电商平台卖开发板的渠道寻求技术支持,当然这些代理或者开发板卖家都是原厂的下游客户,介绍了下游可能的生意,远比直接拒绝或者闷声不回复更有沟通技巧,更能获得用户支持。可能今天问你的这个人一穷二白,但是明天他可能就做起来了呢
#88 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » PCB代工厂为啥不留着多出来的PCB? » 2024-03-12 19:16:55
以上我简单理解为:
1.板厂应该把打叉板(不良pcb)一起发给客户,如果客户有能力修复打叉板,那是客户的本事(或者打叉的断线不影响某个项目的实际功能,这部分段线本来就不贴料)。板厂留了客户的打叉板也没有意义,板厂即使保留也会用良品PCB做样品,打叉板没有必要保留。以上客户得利
2.但是,某些PCB即使是做坏的,也是有价值的(回收价值),例如沉金的不良PCB,因此板厂也可能不会把这些不良pcb发给客户。工厂卖给废品公司获得收益,以上两者都没有实质损失,客户没有少板,板厂也把做坏的板子卖钱了
3.板厂发的料不够,这必须是板厂责任,任何理由都不成立,客户损失,板厂损失更大(要二次生产,二次生产需要的成本比单次多生产更高),或许板厂也可以从即将报废的垃圾堆里面找到不良pcb,然后叫维修组线上rework把不良修复,但手工修复的会影响外观, 补线的地方要重新涂光固漆, 客户不一定会接受这种板.因此如出现这种情况,板厂肯定是大损失,后续客户也可能不会再找这个板厂合作!
#91 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » 从淘宝网购买时要小心 » 2024-03-12 18:38:21
#93 Re: DIY/综合/Arduino/写字机/3D打印机/智能小车/平衡车/四轴飞行/MQTT/物联网 » 【新玩具get】AGM AGRV2K,16.8块钱的MCU+FPGA二合一芯片 » 2024-03-08 20:08:03
#94 Re: DIY/综合/Arduino/写字机/3D打印机/智能小车/平衡车/四轴飞行/MQTT/物联网 » 【新玩具get】AGM AGRV2K,16.8块钱的MCU+FPGA二合一芯片 » 2024-03-08 19:51:13
#95 Re: Xilinx/Altera/FPGA/CPLD/Verilog » 想用国产FPGA真不容易 » 2024-01-18 09:33:30
个人考虑的国产FPGA选料设定原则:
1.价格是国外同类产品的50%以下(因为国产fpga设计IDE较弱,效率低于国外同行85%,造成研发成本和周期增加,如果只是物料价格低30%,最终不见得会省成本)
2.面向社区玩家(散户)可直接公开购买(都买不到料,我设计了你进来我难道是玩B站做科普培训视频来圈粉赚钱?)
3.一个产品从面世到EOF周期需10年以上(如果我设计了一个板子,过2年就买不到料了,同样造成重复开发,研发成本上升)
4.绝对不考虑一些只面向军工或者政府单位背景的国产FPGA公司(原因不方便说,我等小民不敢去碰红线)
好像筛选一下,合适的也没多少了.我只喜欢自下而上没有政府背景依靠自身技术独立做起的公司

#97 Re: Xilinx/Altera/FPGA/CPLD/Verilog » zynq7010/7020核心板众筹openzynq » 2024-01-12 17:23:12
chxzh123 wrote:
也跟风做了一个,目前正在调试中(63mm*55mm)
/files/members/3710/zynq.jpg
我喜欢你这个布局和走线
#99 Re: Xilinx/Altera/FPGA/CPLD/Verilog » 想用国产FPGA真不容易 » 2024-01-11 13:44:29
AGM虽然用了ALTERA的QUARTUS做综合,不过这里也不算完全侵权,综合器本来是大家都可以用的,很多IDE里面带的也是第三方综合器厂商的高效产品,比自己开发综合器编译效率更高的多。这里 QUARTUS做的非常好,各种优化选项设置一下综合出来网表基本上能扣出几十个SLICE粗来。或许AGM可以通过写SHELL脚本去调用,甚至抽出IDE里面的综合器出来,把约束设置文件也抽出来,不必要开QUARTUS界面来让用户感觉是在偷用A家开发软件。
倒是AGM的FITTER做的比较菜,这个时候,完全和QUARTUS的FITTER没的比,产生出来的最终LUT占用,效率低于A家IDE的15%(area/dencity优化下),很多altera的项目用到芯片资源99%的情况下,不得不扣代码砍掉部分以让agm最终布线通过
#100 Re: Xilinx/Altera/FPGA/CPLD/Verilog » 荔枝糖 nano 入坑 » 2024-01-11 12:40:51
fpga还是有细分的,高端大规模fpga主要供应对象是芯片设计公司和国防军工单位,以及部分对算力需求大的特殊应用。这部分虽然量不多,但是利润非常大,fpga供应商不只是提供物料,更多的是提供技术服务,合作芯片开发,软硬件的一整套技术支持,甚至是为客户定制前端设计服务。这部分x厂a厂占据了绝对的江山。
中低端fpga其实才是商用/民用出货量大的地方,而低端fpga/cpld则利润已经很低。例如一些低于2美元的非易失性配置cpld,用量非常大,这部分lattice是占据了大头。中低端fpga使用灵活,价格合适,与专用asic相比价格也并非不可硬杠,依靠规模效应打击asic芯片。对于设计开发者,这种可编程器件节省了bom物料,简化了pcb布线成本,虽然提高了设计门槛,但也同时增加了产品利润空间和防盗门槛。这些还是很合适的。
如果不用cpld/fpga,一块板子能设计成巴掌大,四层,但是只需要一个io密集型的cpld,则就可以将板子走线简化到火柴盒大小的模块。
低端cpld/fpga的竞争对手,其实不是专用asic,而是另一个可怕的正在崛起的怪物,raspberry pico,其已经可以做到部分cpld能做的功能了,而且mcu内核又比某某32更强大。即使是带有硬mcu的融合型fpga,也碰到了一个强硬对手
#103 Re: Xilinx/Altera/FPGA/CPLD/Verilog » 想用国产FPGA真不容易 » 2024-01-09 17:52:41
诚然,确实有很多公司,里面不少工程师,出于对项目风险以及个人的职业安全度考量,在设计项目开端,叫原厂fae去check设计,并期望给于建议,这其实是一种职业型策略,因为项目是公司的,而个人在公司的职位晋升风险是自己的,所以多做保守的事情,把交代的事情都交代好,万一项目出现风险中途delay或者cancel也能尽最大可能让自己安全上岸,不至于为整个项目背锅。
但是,如果是个人社区玩家,他实行的是另一个策略,即我不会让你知道细节,但我只想要买你的片子。社区玩家里面部分是hacker,部分是从其他公司出来单干的,部分是从大公司退休的,他们出于更大的个人安全考虑(相对于在一家公司上班可能成为项目背锅侠而遭到老板开除,是更大的一种安全考虑,担心被某家公司告,又或者担心自己的项目被泄露而造成严重损失)。
所以,不同的开发人员,有不同的作业风格,传统的企业对企业接口需要前者策略,而个人开发者类似于象买春或者买毒一样,他不会少你的钱,但是销售不要多问,而且你不要给假货。
#105 Re: Xilinx/Altera/FPGA/CPLD/Verilog » AG1280 » 2024-01-09 14:18:28
#106 Re: Xilinx/Altera/FPGA/CPLD/Verilog » 想用国产FPGA真不容易 » 2024-01-09 14:11:44
怎么说呢,感觉用国产FPGA厂家就象是相亲,本来是不一定想用的,抱着试试看的态度尝试一下,结果跑去,人家也不拒绝,但也不主动,很冷淡,有问题想问问原厂或者代理,他们回也不愿意回,一声不想的,问他怎么搞,开发环境搭建和开发过程基本都要自己主动吭生肉,甚至有些tool chain还很不完善,不得不自己重新写。
好像是他/她明明自身条件中等甚至中下,但也看不上你,时刻端着自己摆出一副姿态的样子,结果这样反复几次,很多人玩了半月就从憧憬到放弃了。
三大厂,对于个人玩家,就象是万人迷,而我们是他的粉丝,但是人家表现出来的却是大家闺秀的感觉,资料网站上非常详细,开发工具到app note很多,而且还有社区直接Q&A,也不需要什么公司备份资料再签NDA的流程,唯一就是不对你直接支持而已。但你可以强暴,什么都不要支持,自己就玩转起来,然后从流通市场购买,甚至从灰色市场购买(翻~新~片)
而国产FPGA厂家,就象是穷精致的女孩,自己条件一搬,所以喜欢拥抱大款,对吊丝个人开发者甩也不甩,你甚至连买片子的渠道都找不到,买个把片子可以,要多,就流程来了(好像是礼金一样)。甚至你有钱你也买不到。
摆脱,我有钱,我会找你穷精致的拜金女?拜金女最合适的出路就是给大款保养做备份,同样地,国产料基本就是给大公司做2nd source,平时不用你,在某个特殊的项目上用下你。
所以基本是这个情况,好像是还没有很好定位好
页次: 1
- 首页
- » 搜索
- » aquasnake 发表的帖子
东莞哇酷科技有限公司开发