楼主 # 2021-05-27 00:45:14 分享评论
- 伍零壹
- 会员

- 注册时间: 2019-12-16
- 已发帖子: 160
- 积分: 38
KEIL开发LVGL显示汉字不能正常显示
1.keil的编码方式设置为UTF-8
2.用阿里兄弟的字体转换工具转换的库
3.keil编写代码后下载到单片机失败
4.在3的基础上删掉汉字,并且写入字符 “123456” ------->显示正常
5.在4的基础上改回汉字------->显示失败
6.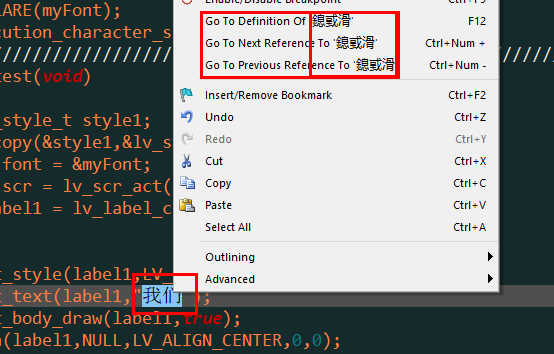
现在唯一看到的就是这个了 不知道是不是这个原因
7.KEIL改回为GB2312显示 下载代码 还是显示失败
大佬们有什么方法 求指点
离线
#1 2021-05-27 10:38:59 分享评论
- 小智
- 会员
- 注册时间: 2019-10-16
- 已发帖子: 113
- 积分: 80
Re: KEIL开发LVGL显示汉字不能正常显示
试试把字符转换成\x31 \x32这类或者\u这类,试试,这样再也不用担心编码问题了
http://www.msxindl.com/tools/unicode16.asp
http://www.ab126.com/goju/10861.html
https://the-x.cn/encodings/Hex.aspx
最近编辑记录 小智 (2021-05-27 10:54:33)
离线
#2 2021-05-27 11:29:28 分享评论
- xk100
- 会员
- 注册时间: 2018-12-13
- 已发帖子: 75
- 积分: 58.5
Re: KEIL开发LVGL显示汉字不能正常显示
应该是你文件编码方式不对。
离线
楼主 #3 2021-05-27 16:54:00 分享评论
- 伍零壹
- 会员
- 注册时间: 2019-12-16
- 已发帖子: 160
- 积分: 38
Re: KEIL开发LVGL显示汉字不能正常显示
小智 wrote:
试试把字符转换成\x31 \x32这类或者\u这类,试试,这样再也不用担心编码问题了
http://www.msxindl.com/tools/unicode16.asp
http://www.ab126.com/goju/10861.html
https://the-x.cn/encodings/Hex.aspx
这样是可以的 我试过 这种方式显示汉字是正确的 但是直接"我们"这种方式就不行了
离线
#4 2021-05-27 17:25:48 分享评论
- 小智
- 会员
- 注册时间: 2019-10-16
- 已发帖子: 113
- 积分: 80
Re: KEIL开发LVGL显示汉字不能正常显示
@伍零壹
好说,直接用记事本打开C文件,另存为,选择编码格式,搞定
离线

楼主 #6 2021-05-28 08:18:19 分享评论
- 伍零壹
- 会员
- 注册时间: 2019-12-16
- 已发帖子: 160
- 积分: 38
Re: KEIL开发LVGL显示汉字不能正常显示
小智 wrote:
@伍零壹
好说,直接用记事本打开C文件,另存为,选择编码格式,搞定
是的,我昨天晚上试了 这种方法可以,在KEIL的encoding里面设置不行。还有就是我用notepad++转为UTF-8试了不行,用记事本转的可以。不知道为什么。
离线
楼主 #7 2021-05-28 08:18:53 分享评论
- 伍零壹
- 会员
- 注册时间: 2019-12-16
- 已发帖子: 160
- 积分: 38
Re: KEIL开发LVGL显示汉字不能正常显示
kingwho wrote:
将编码格式改为utf-8后,把字符删掉,重新再打出来呢。这个我也有一个问题,就是如果汉字个数为奇数个就会报错,这个是怎么回事呢
你说的奇偶这种我么有与遇到过
离线
#8 2021-05-28 08:28:48 分享评论
- raspberryman
- 会员
- 注册时间: 2019-12-27
- 已发帖子: 503
- 积分: 465
Re: KEIL开发LVGL显示汉字不能正常显示
@伍零壹
可能是 with bom和no bom的区别,就是with bom在文件头多四个字节。
离线
#9 2021-05-28 10:10:20 分享评论
- wujique
- 会员
- 注册时间: 2018-10-30
- 已发帖子: 178
- 积分: 172
Re: KEIL开发LVGL显示汉字不能正常显示
不清楚阿里字体库跟LVGL是怎么联系的。
普通的单片机开发:
1 文件默认都是ANSI编码,内嵌的汉字用GBK编译后得到的内容是GBK。
2 程序中,也是根据GBK定位算法对字库进行寻址。
3 包含的点阵文件也是按照GBK排布。
意思是要用汉字,三方面的规格要匹配:
输入的内容,取字体算法,字体本身。
你现在用的源码文件时UTF8,编译后得到的应该是unicode,那么找字算法和字体库都要是unicode。
或者进行编码转换后再对GBK字库寻址。
http://www.wujique.com/2021/05/15/elementor-811/
http://www.wujique.com/2020/05/10/%e5%8d%95%e7%89%87%e6%9c%ba%e6%ba%90%e7%a0%81%e4%b8%ad%e6%96%87%e5%a4%9a%e5%b9%b3%e5%8f%b0%e4%b9%b1%e7%a0%81%e9%97%ae%e9%a2%98/
离线
楼主 #10 2021-05-28 11:21:07 分享评论
- 伍零壹
- 会员
- 注册时间: 2019-12-16
- 已发帖子: 160
- 积分: 38
Re: KEIL开发LVGL显示汉字不能正常显示
@wujique
大佬牛逼 我昨天在论坛找了一份GBK转unicode的C代码,现在显示汉字没什么问题了。貌似fatfs的CC936文件里面有函数支持编码转换的
离线
#11 2022-11-15 22:47:43 分享评论
- 小梁同学
- 会员
- 注册时间: 2022-11-15
- 已发帖子: 2
- 积分: 2
Re: KEIL开发LVGL显示汉字不能正常显示
你好博主,LVGL无法显示中文的问题最后你是怎么解决了,可以方便讲讲吗,微信:18312727390
离线
楼主 #12 2022-11-16 08:27:26 分享评论
- 伍零壹
- 会员
- 注册时间: 2019-12-16
- 已发帖子: 160
- 积分: 38
Re: KEIL开发LVGL显示汉字不能正常显示
小梁同学 wrote:
你好博主,LVGL无法显示中文的问题最后你是怎么解决了,可以方便讲讲吗,微信:18312727390
/files/members/10789/579c6e058ae57f077941319dce3de0a.jpg
回复你邮件了
离线
#13 2022-11-16 09:53:56 分享评论
- regbbs
- 会员
- 注册时间: 2020-04-06
- 已发帖子: 95
- 积分: 62.5
Re: KEIL开发LVGL显示汉字不能正常显示
源代码使用UTF-8带BOM的格式保存。
实在不行就转换成"\xxxx"的格式
离线

#15 2022-11-16 20:15:34 分享评论
- novice
- 会员
- 注册时间: 2019-07-26
- 已发帖子: 126
- 积分: 107
Re: KEIL开发LVGL显示汉字不能正常显示
海石生风 wrote:
99%的UI库如果支持unicode则必定是UTF-8编码。另外,UTF-8带BOM如同脱裤子放屁,多此一举。UTF-16才需要带BOM。
不能同意你这种说法,BOM非常重要,说BOM不重要的人只是没有遇到那种场景而已。
离线
#16 2022-11-17 00:09:12 分享评论
- regbbs
- 会员
- 注册时间: 2020-04-06
- 已发帖子: 95
- 积分: 62.5
Re: KEIL开发LVGL显示汉字不能正常显示
海石生风 wrote:
99%的UI库如果支持unicode则必定是UTF-8编码。另外,UTF-8带BOM如同脱裤子放屁,多此一举。UTF-16才需要带BOM。
你这是思维混乱不堪。
UI库支持UTF-8,并不表示编译器也识别源代码中的资源的编码格式。
不指定或者文件没BOM,编译器可能按照ANSI去处理,然后显示就不正常了。
这不是脱裤子放屁,而是把自己遇到的同样的问题后处理办法共享出来。
而你,浅薄或者自以为是,还粗鄙不堪。
离线
#17 2022-11-17 09:34:26 分享评论
Re: KEIL开发LVGL显示汉字不能正常显示
novice wrote:
海石生风 wrote:
99%的UI库如果支持unicode则必定是UTF-8编码。另外,UTF-8带BOM如同脱裤子放屁,多此一举。UTF-16才需要带BOM。
不能同意你这种说法,BOM非常重要,说BOM不重要的人只是没有遇到那种场景而已。
BOM是干哈用?是用来指示是小端法还是大端法的。什么情况下需要区分大小端?就是数值长度超过一个字节。UTF-8的数值都是以字节进行编排,顺序是固定的,无需再额外指示。
UTF-16这种才会出现长度超过一个字节的数值,这种数值在不同平台上的存储顺序有大小端之分,所以才需要指明。
最近编辑记录 海石生风 (2022-11-17 09:35:06)
离线
#19 2022-11-17 17:57:52 分享评论
- novice
- 会员
- 注册时间: 2019-07-26
- 已发帖子: 126
- 积分: 107
Re: KEIL开发LVGL显示汉字不能正常显示
BOM不仅用来指示大小端还用来指示文本编码。开发过文本编辑器的都有体会,如果文本文件的开头没有BOM那么就只能靠猜,当然UTF8编码总是能够猜对的,因为它有自编码规则,但是ANSI CODEPAGE和UTF16就不是那么好猜了。编辑器每次都靠从头猜到尾来判断文本编码对效率来说也不好,假如编译器每打开一个源文件就要猜一次,那编译一个大工程也是够累的,当然有些编译器不愿意去猜,只承认ANSI编码。
顺便提一下,KEIL这个IDE以前是支持BOM的,到了5.x后好像取消了对BOM的支持,这样一来用户就变得不方便了。其实检测文件头的BOM只不过是几行代码的事情,我实在想不明白为什么他们不愿意支持这个功能。Win平台上的文本编辑工具绝大多数会支持BOM,连最简单的记事本都能够支持BOM,这才是以用户为中心的做法。
离线
#20 2022-11-17 22:58:13 分享评论
Re: KEIL开发LVGL显示汉字不能正常显示
@novice
不要自以为是,不同编码都有它的规律,判断一个文件是什么编码不是靠猜的。Linux跟苹果系统都不认可BOM,照样可以正常打开各种编码的文件。另外,Linux下判断一个文件的类型也不是Windows那样通过后缀名来确定的,而是通过文件内容来确定的。
BOM是不可显示的内容,会破坏文档语法约定。
如果你不加思索地往文件加BOM,要是日后你要在其他平台使用这个文件,你会遇到很多问题。
至于为什么微软喜欢加BOM,我认为就是他们的工程师懒惰,就像简单地通过文件后缀名来确定文件类型一样!
最近编辑记录 海石生风 (2022-11-17 23:17:04)
离线
#21 2022-11-18 07:33:05 分享评论
- novice
- 会员
- 注册时间: 2019-07-26
- 已发帖子: 126
- 积分: 107
Re: KEIL开发LVGL显示汉字不能正常显示
在UNICODE文本流前面加BOM是符合UNICODE标准的,为什么符合标准仍然会被一些人指责呢?指责方无非是为了己方利益而已,说白了就是争夺话语权(加BOM还是不加BOM的事实话语权)。
从技术上看加BOM能够指示读取程序快速解码,有利于提高用户体验,用户更喜欢。不加BOM也无大碍,无非是解码时需要逐个尝试UTF8/UTF16-LE/UTF16-BE/ANSI CODEPAGE等编码方式,耗费的时间多一点而已,从这一点看加BOM是比较聪明的做法(懒的人一般更聪明😝)。
我们知道XML文件有“encoding”,HTML文件有“charset”指示符,说明了客观上是有指示读取程序如何解码的需求,在UNICODE文本流前面加入BOM是能够给与一般文本文件读取程序一定的帮助又符合UNICODE标准的做法。
不管哪个系统的文本文件读取软件都应该能够识别开头的BOM,可以不加BOM但不应该不能识别BOM,这是为了提高用户体验而不是为了程序员自身的固执偏见
离线
#23 2022-11-19 00:08:13 分享评论
- armstrong
- 会员

- 注册时间: 2019-04-10
- 已发帖子: 295
- 积分: 189.5
Re: KEIL开发LVGL显示汉字不能正常显示
这个话题根本无需争论,各执己见比较好。
离线
东莞哇酷科技有限公司开发