#2 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » AI冲击下嵌入式攻城狮还剩多少技术护城河 » 2026-04-01 18:31:38
memory wrote:
自从用了 cursor 之类的AI软件,基本不些写代码了,有bug也不看代码,直接把bug描述出来,让AI继续改。
要是勤快一点,一天烧个100刀随随便便。
一天100刀,那岂不是等于给AI打工了?!
#3 Re: RISC-V » 现在最便宜的USBHS单片机是哪个 » 2026-03-24 11:04:43
#5 Re: 全志 SOC » 屏幕内容显示超出范围,请各位大佬指点一下。 » 2026-01-25 11:07:18
#7 Re: 全志 SOC » T113的sdk开启iconv的问题 » 2026-01-15 10:47:34
#8 Re: 全志 SOC » T113的sdk开启iconv的问题 » 2026-01-14 18:21:26
#11 Re: 工业芯 匠芯创 » 仿真器能看到寄存器数值,但是就不能在线时候停止在断点处为啥? » 2025-12-18 16:32:24
#12 Re: 工业芯 匠芯创 » 关于衡山派D133EBS开发板背光电路的疑问 » 2025-12-18 11:37:10
#13 Re: 工业芯 匠芯创 » 仿真器能看到寄存器数值,但是就不能在线时候停止在断点处为啥? » 2025-12-17 17:41:20
#14 Re: 工业芯 匠芯创 » 关于衡山派D133EBS开发板背光电路的疑问 » 2025-12-17 17:33:24
#15 Re: 工业芯 匠芯创 » windows usb 驱动 demo » 2025-12-14 13:03:44
#24 Re: 全志 SOC » 淘到的二手苹果 MAC AIR 安装 Windows » 2025-09-27 10:40:37
#25 Re: 全志 SOC » 淘到的二手苹果 MAC AIR 安装 Windows » 2025-09-27 10:05:04
#26 Re: 工业芯 匠芯创 » D213的luban-lite可以用来做投屏吗? » 2025-09-26 10:43:37
#27 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » 嵌入式工程师的职业瓶颈 » 2025-09-25 17:03:33
#28 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » 嵌入式工程师的职业瓶颈 » 2025-09-24 17:54:18
#29 Re: 工业芯 匠芯创 » 匠心创原厂看过来:请问有没有BROM的接口资料? » 2025-09-11 19:49:15
#31 Re: 全志 SOC » 求问快速冷启动拍照的方案 » 2025-09-01 19:55:38
rtos启动速度200ms应该是非XIP启动的耗时,不过这个XIP启动我也没有深究。
D13x的SDK是全公开的,在这里: https://gitee.com/artinchip/luban-lite
#32 Re: 全志 SOC » 求问快速冷启动拍照的方案 » 2025-08-30 20:51:36
#33 Re: 全志 SOC » 求问快速冷启动拍照的方案 » 2025-08-30 11:10:53
#34 Re: 全志 SOC » 求问快速冷启动拍照的方案 » 2025-08-29 13:24:57
#36 Re: 全志 SOC » 求助 T113S3 LCD显示有水纹 » 2025-08-26 08:47:54
#37 Re: 全志 SOC » 求助 T113S3 LCD显示有水纹 » 2025-08-25 21:32:07
#39 Re: BLDC电机驱动 » 有专门针对步进电机的MCU芯片方案么? » 2025-08-11 11:42:33
#40 Re: 全志 SOC » T113-i与DDR3芯片地址线连接问题 » 2025-08-09 18:07:46
#41 Re: 全志 SOC » F1C100s有没有可能用有源晶振? » 2025-08-07 10:10:23
#42 Re: BLDC电机驱动 » 有专门针对步进电机的MCU芯片方案么? » 2025-08-05 18:16:10
#43 Re: 工业芯 匠芯创 » 64MB内存级别的嵌入式Linux UI开发也有类似WPF的MVVM框架了 » 2025-08-02 09:03:47
jlau wrote:
@海石生风
那部分zig代码是手写的还是工具生成的?
哪部分代码?model和view-model都是模型,都是业务代码,当然是手写的。
Zig这边的模型都是Zig结构体,而非AWTK的tk_object_t对象;这里的“封装”是将view-model结构体转换为tk_object_t对象,封装手段是泛型反射;可以理解为Zig的view-model在编译时转换成了tk_object_t对象。
在MVVM框架下,model是纯数据模型、view-mode封装了model并添加UI所需的属性和命令用于跟view交互。
而awtk-mvvm其实没有model而只有view-model,而view-model的实现方式是使用代码生成工具将C的结构体转换为tk_object_t对象。
#44 Re: BLDC电机驱动 » 有专门针对步进电机的MCU芯片方案么? » 2025-07-30 20:11:07
#45 Re: 全志 SOC » v3s怎么实现模拟i2c---荔枝派 » 2025-07-30 20:05:28
#46 Re: 全志 SOC » v3s怎么实现模拟i2c---荔枝派 » 2025-07-30 12:26:54
#49 Re: 全志 SOC » v3s怎么实现模拟i2c---荔枝派 » 2025-07-29 19:08:45
#50 Re: 工业芯 匠芯创 » 64MB内存级别的嵌入式Linux UI开发也有类似WPF的MVVM框架了 » 2025-07-29 11:03:24
上述示例工程的界面效果如下:
其中“性别平衡”的显示比较体现MVVM作为声明式框架的优势,其控件的UI描述是这样的:
<label w="30%" v-data:text="{isGenderBalance ? tr('是') : tr('否')}" />其模型代码是这样的:
// 虚拟property: isGenderBalance
pub fn getIsGenderBalance(self: Self, _: []const u8, v: *awtk.Value) c.ret_t {
var male_count: u32 = 0;
var female_count: u32 = 0;
for (self.users.models.items) |item| {
if (item.gender == .Male) {
male_count += 1;
} else {
female_count += 1;
}
}
_ = c.value_set_bool(v, male_count == female_count);
return c.RET_OK;
}代码就这么多,再没其它的了。这是个虚拟属性,当列表内容增加、减少或列表元素的性别发生变化,其值都会更新。
如果在命令式UI上实现此功能,想必需要添加比较多的事件响应函数,而且整个逻辑代码分散在多个地方,繁琐且容易出BUG.
#51 Re: BLDC电机驱动 » 有专门针对步进电机的MCU芯片方案么? » 2025-07-28 10:35:03
#52 Re: BLDC电机驱动 » 有专门针对步进电机的MCU芯片方案么? » 2025-07-26 19:46:24
#53 工业芯 匠芯创 » 64MB内存级别的嵌入式Linux UI开发也有类似WPF的MVVM框架了 » 2025-07-26 09:57:29
- 海石生风
- 回复: 10
基于Zig语言对AWTK的MVVM框架在泛型/反射特性之上进行了封装,实现了类似WPF那样方便使用的MVVM框架。因为由Zig编写,故支持64MB内存级别的嵌入式Linux UI开发。AWTK的MVVM框架使用C语言编写,但因为C语言的特性太少,直接使用这个框架的话会非常不方便,比如:要在头文件添加特定格式的注释、属性不支持多层等。使用Zig封装之后,使用的便利性基本就跟WPF的MVVM差不多了。
比如,UI声明大致如下:
<window v-model="UsersVM" >
<label v-data:text="{name}" />
<label v-data:text="{cfg.age}" />
<label v-data:text="{tr(cfg.gender.str)}" />
<button tr_text="大一岁" v-on:click="{addAge}" />
<button tr_text="小一岁" v-on:click="{subAge}" />
<button tr_text="添加" v-on:click="{append}" />
</window>对应的模型代码大致如下:实现起来是比较直观而且容易的
pub const UsersVM = struct {
name: awtk.String = undefined,
cfg: struct {
age: u8,
gender: user_model.Gender,
} = .{
.age = 0,
.gender = .Male,
},
const Self = @This();
pub fn addAge(self: *Self) !awtk.Notify {
self.cfg.age += 1;
return .PropertyChanged;
}
pub fn canAddAge(self: Self) bool {
return self.cfg.age < 5;
}
pub fn subAge(self: *Self) !awtk.Notify {
self.cfg.age -= 1;
return .PropertyChanged;
}
pub fn canSubAge(self: Self) bool {
return self.cfg.age > 0;
}
pub fn append(self: *Self) !awtk.Notify {
// 逻辑代码实现
return .ItemsChanged;
}
pub fn canAppend(self: Self) bool {
return self.name.len() > 0;
}
};项目地址在这里:https://gitee.com/ufbycd/awtk-mvvm-zig-example
目前嵌入式Linux已经在D21x平台的D213ECV-DEMO-V4开发板上验证。 另外,Zig的交叉编译也非常方便,上述项目已经内置D21x平台编译支持,编译命令为:
zig build -Dd21x该命令等效于:
zig build -Dtarget=riscv64-linux-gnu -Dcpu=generic_rv64+i+m+a+f+d+c可前往项目地址了解更多详情。
#54 Re: Cortex M0/M3/M4/M7 » 请各位推荐小体积的MCU » 2025-07-24 22:58:04
#55 Re: 全志 SOC » v3s怎么实现模拟i2c---荔枝派 » 2025-07-24 18:47:05
#56 Re: Cortex M0/M3/M4/M7 » 请各位推荐小体积的MCU » 2025-07-24 18:03:41
#60 Re: BLDC电机驱动 » 有专门针对步进电机的MCU芯片方案么? » 2025-07-23 12:24:52
#61 Re: BLDC电机驱动 » 有专门针对步进电机的MCU芯片方案么? » 2025-07-19 21:11:41
#62 Re: 全志 SOC » 请教xboot中mmu的问题 » 2025-07-09 16:18:16
#63 Re: 技术人生/软件使用技巧/破解经验/技术吐槽/灌水 » 盗版CH340的被判刑了 » 2025-07-09 13:22:01
#64 Re: 全志 SOC » F1C100S使用LVGL显示图片速度很慢,寻求优化建议 » 2025-07-07 21:21:27
#65 Re: 全志 SOC » F1C100S使用LVGL显示图片速度很慢,寻求优化建议 » 2025-07-07 21:16:28
#66 Re: 全志 SOC » F1C100S使用LVGL显示图片速度很慢,寻求优化建议 » 2025-07-07 13:46:59
#68 Re: RK3288/RK3399/RK1108 » rk3506G从入门到放弃 » 2025-06-25 12:12:57
#70 Re: 全志 SOC » T113-S3如何检测单片机是否正常运行 » 2025-06-21 13:39:29
#71 Re: 全志 SOC » T113-S3如何检测单片机是否正常运行 » 2025-06-21 11:11:05
#72 工业芯 匠芯创 » linux SDK的构建系统不要自动检测ncurses是否安装了,检测功能不准确 » 2025-06-21 10:31:40
- 海石生风
- 回复: 0
linux SDK的构建系统的自动检测ncurses是否安装功能不准确。
Manjaro Linux系统,ncurses被一大堆软件包依赖,肯定是已经安装了的
$ pacman -Q ncurses
ncurses 6.5-4$ make menuconfig
*** Unable to find the ncurses libraries or the
*** required header files.
*** 'make menuconfig' requires the ncurses libraries.
***
*** Install ncurses (ncurses-devel or libncurses-dev
*** depending on your distribution) and try again.
***
make[1]: *** [Makefile:253:/home/chenss/git/ArtInChip/d211/output/d211_D213ecvDemoV4/build/luban-config/dochecklxdialog] 错误 1
make: *** [package/Makefile.sdk:706:/home/chenss/git/ArtInChip/d211/output/d211_D213ecvDemoV4/build/luban-config/mconf] 错误 2#73 Re: 工业芯 匠芯创 » D133CBS编译会蓝屏有解决办法吗? » 2025-06-14 14:57:52
#74 Re: 全志 SOC » 荔枝派zero通过otg与PC共享网络无法实现 麻了 » 2025-06-06 18:14:47
#77 Re: ESP32/ESP8266 » 有朋友能指导一下下面的cr2032供电逻辑吗 » 2025-05-26 09:26:03
#78 Re: 全志 SOC » F1C100S驱动i8080的MCU屏画面撕裂有没有解决方法 » 2025-05-20 16:41:23
#79 Re: 全志 SOC » F1C100S驱动i8080的MCU屏画面撕裂有没有解决方法 » 2025-05-20 12:30:58
#80 Re: 全志 SOC » 荔枝派Zero为啥串口打印显示正常,但是无法输入 » 2025-05-09 11:18:36
#81 Re: DIY/综合/Arduino/写字机/3D打印机/智能小车/平衡车/四轴飞行/MQTT/物联网 » 请问这种 MT919C-00FF 36F-12646-F 红外发射芯片是哪里买的? » 2025-05-07 09:35:38
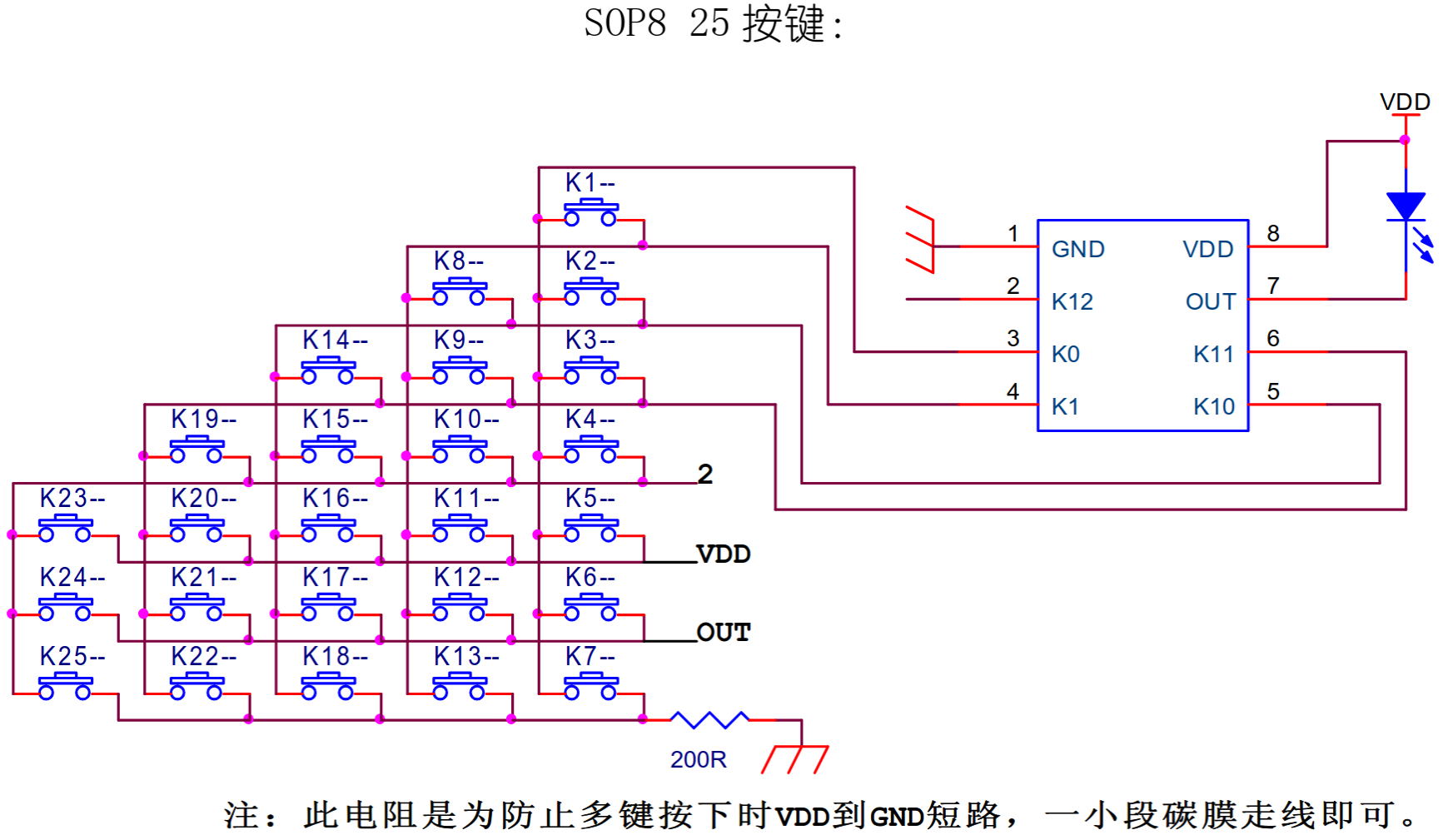
#82 Re: DIY/综合/Arduino/写字机/3D打印机/智能小车/平衡车/四轴飞行/MQTT/物联网 » 请问这种 MT919C-00FF 36F-12646-F 红外发射芯片是哪里买的? » 2025-05-06 23:12:30
#85 Re: 工业芯 匠芯创 » 编译问题 gitee下载下来的编译报 python错误 » 2025-04-27 19:52:06
#88 Re: 工业芯 匠芯创 » 衡山派sd卡挂载不正常 » 2025-04-16 12:07:39
#90 Re: 全志 SOC » EA3036 输出电压不对,想请大佬帮忙分析一下。 » 2025-04-11 23:55:41
#91 Re: DIY/综合/Arduino/写字机/3D打印机/智能小车/平衡车/四轴飞行/MQTT/物联网 » 拆了娃的故事机,发现电路板上元件不多啊。 » 2025-04-07 09:32:26
#92 Re: 工业芯 匠芯创 » 使用D12x这款芯片,现在遇到几个问题还请大佬指点 » 2025-03-24 21:49:01
bootloader主程序在 application/baremetal/bootloader/main.c的main函数内,通过调用console_set_bootcmd函数来执行不同介质的启动命令,这些命令在application/baremetal/bootloader/cmd文件夹内。
SDK文档的“SDK 编译”章节对Eclipse和VS Code均有描述
芯片ID读取可参考/bsp/artinchip/drv/efuse/drv_efuse.c(或bsp/artinchip/drv_bare/efuse/efuse.c)的drv_efuse_read_chip_id函数
#96 Re: RISC-V » rv32 cpu该怎么适配rust,试着模仿写了点但编译出错 » 2025-03-18 16:13:39
#98 Re: 工业芯 匠芯创 » luban-lite的SDK使用IDE开发 » 2025-03-18 11:04:43
regbbs wrote:
海石生风 wrote:
luban-lite是RTOS,上了OS一般都用串口调试,很少用JTAG调试了。思维要转变。
你这就是搞笑了,keil+rtx,用jtag调试不方便吗?有些数据需要查看然后手动修改看逻辑运行结果等,你也用串口?
很奇怪吗?!我裸机开发也只有初期搭最小系统才JTAG调试,绝大部分情况用串口调试。因为搞了类似RT-Thread那样的串口命令解析器。
想测什么功能就写一个单元测试的串口命令,这才是符合软件工程的开发方式。RTOS、嵌入式Linux上都有的串口终端可不是白搭的。
如果不理解串口终端、单元测试的意义,还请不要理会我的发言。
#99 Re: RISC-V » rv32 cpu该怎么适配rust,试着模仿写了点但编译出错 » 2025-03-17 16:12:05
#100 Re: 工业芯 匠芯创 » luban-lite的SDK使用IDE开发 » 2025-03-17 11:18:23
#101 Re: 工业芯 匠芯创 » 关于GUI工具的选型建议 » 2025-03-11 18:29:56
#102 Re: 工业芯 匠芯创 » D133EBS这个芯片性能如何?跟STM32哪款芯片对比呢? » 2025-03-11 15:31:37
#105 Re: 计算机图形/GUI/RTOS/FileSystem/OpenGL/DirectX/SDL2 » ArtInChip D21 基于 DRM 适配 LVGL V9 » 2025-02-19 11:36:52
#106 Re: 全志 SOC » 触摸屏提示音 » 2025-02-16 14:25:45
#107 Re: 工业芯 匠芯创 » Luban-lite rt-thread系统 在SCons4.5.2环境下编译错误的解决办法 » 2025-02-08 10:01:30
方法二改法不太妥当。新版本下,Env.get函数返回的是deque、group.get函数返回的是list,再者不能用加号来组合。最好按下述修改:将deque转为list
diff --git a/kernel/rt-thread/tools/building.py b/kernel/rt-thread/tools/building.py
index 24bcf5cc..cf329981 100644
--- a/kernel/rt-thread/tools/building.py
+++ b/kernel/rt-thread/tools/building.py
@@ -779,8 +779,8 @@ def DoBuilding(target, objects):
CFLAGS = Env.get('CFLAGS', '') + group.get('LOCAL_CFLAGS', '')
CCFLAGS = Env.get('CCFLAGS', '') + group.get('LOCAL_CCFLAGS', '')
CXXFLAGS = Env.get('CXXFLAGS', '') + group.get('LOCAL_CXXFLAGS', '')
- CPPPATH = Env.get('CPPPATH', ['']) + group.get('LOCAL_CPPPATH', [''])
- CPPDEFINES = Env.get('CPPDEFINES', ['']) + group.get('LOCAL_CPPDEFINES', [''])
+ CPPPATH = list(Env.get('CPPPATH', [''])) + group.get('LOCAL_CPPPATH', [''])
+ CPPDEFINES = list(Env.get('CPPDEFINES', [''])) + group.get('LOCAL_CPPDEFINES', [''])
ASFLAGS = Env.get('ASFLAGS', '') + group.get('LOCAL_ASFLAGS', '')
for source in group['src']:#108 Re: BLDC电机驱动 » 直流无刷电机电动工具柔性刹车 » 2025-01-24 21:43:56
#109 Re: 全志 SOC » 群里那个sd转jtag的板有做好卖的么 » 2025-01-22 16:56:21
#110 Re: 全志 SOC » 8.8元的 ML307R-DL 4G CAT.1 模块 » 2025-01-16 10:13:16
#111 Re: BLDC电机驱动 » 步进电机驱动 » 2025-01-15 22:59:03
#112 Re: 工业芯 匠芯创 » 求 D211 luban_lite mmc镜像生成配置文件或方法 » 2025-01-15 15:16:34
我之前试过是可以的,需要修改Flash设备类型及额外一些配置,参见这里:
#113 Re: 工业芯 匠芯创 » D133开发板立创衡山派更换SPI NAND后无法输出图像 » 2025-01-15 15:11:36
#114 Re: 全志 SOC » 全志f1c100s可以用于工业级应用吗? » 2025-01-14 12:09:53
#115 Re: Cortex M0/M3/M4/M7 » 稳定的jlink推荐 » 2025-01-11 15:34:36
#116 Re: 工业芯 匠芯创 » d122xx 类型产品有计划移植ardunio开发嘛 » 2024-12-31 17:14:13
#117 Re: BLDC电机驱动 » 直流无刷电机电动工具柔性刹车 » 2024-12-31 11:58:53
#120 Re: BLDC电机驱动 » 直流无刷电机电动工具柔性刹车 » 2024-12-27 11:26:39
#125 Re: 工业芯 匠芯创 » D21x 的UART的最高速度到底是多少? » 2024-12-21 00:18:15
#126 Re: 工业芯 匠芯创 » D133挂载文件失败 » 2024-12-13 21:59:59
#128 Re: 计算机图形/GUI/RTOS/FileSystem/OpenGL/DirectX/SDL2 » 基于LVGL的嵌入式声明式UI框架zdec略有小成! » 2024-12-07 13:07:42
今年年初起的这个项目至今都有任何进展,是因为还有很多细节一直没有搞定。并且LVGL的API一直都不稳定,单单是搞其API绑定层都要不少精力。
因为Zig基本上可以直接调用C,故放弃API绑定层的思路,直接在框架内调用UI库的C接口,并将框架转为MVVM。
MVVM框架本身就规定好了View跟Model的绑定规则,非常适合声明式UI框架。
目前已经基本在awtk-mvvm上添加实现了zig语言支持:https://gitee.com/ufbycd/awtk-mvvm-zig-example,在zig上实现Model要比C/C++方便很多,便捷性几乎跟javascript的差不多。
下一步,将用zig元组替换xml来实现View声明,即实现一个zig的MVVM框架:zig-mvvm
再下一步,将zig-mvvm框架推广到其它UI库,如LVGL等。
因为业余自由时间不是很多,一天至多只能抽出两三个小时,也是随缘更新。
#131 Re: BLDC电机驱动 » 有专门针对步进电机的MCU芯片方案么? » 2024-11-28 20:19:25
#133 Re: BLDC电机驱动 » 有专门针对步进电机的MCU芯片方案么? » 2024-11-26 13:33:19
#134 Re: ESP32/ESP8266 » 关于SIMD如何学习的文档 » 2024-11-22 11:37:48
#135 Re: 计算机图形/GUI/RTOS/FileSystem/OpenGL/DirectX/SDL2 » AWTK 开源智能串口屏方案发布 » 2024-11-11 10:13:29
我用AWTK有一两年了,只要在awtk.zlg.cn网站保持登录就会持续发放LIC。
不过我不怎么用AWStudio,实际项目都是手写UI描述文件XML,特别是用了MVVM的情形。即使是手写XML肯定也比LVGL好用,LVGL现在才开始搞UI描述文件。
如果对MVVM感兴趣,可以关注我这几天的研究成果,用zig写MVVM应用,利用zig的泛型/反射特性直接从Model构建出View-Model:
https://gitee.com/ufbycd/awtk-mvvm-zig-example
#136 Re: 工业芯 匠芯创 » d133裸机如何进行中文显示(不用lvgl) » 2024-11-01 17:45:56
#137 Re: 硬件设计 KiCAD/Protel/DXP/PADS/ORCAD/EAGLE » 以太网口出的信号,大家是用什么设备检测的?直接电脑ping? » 2024-10-31 13:08:53
#140 Re: 工业芯 匠芯创 » D213ECV 使用 Aiburn 无法烧录 » 2024-10-22 15:22:49
#141 Re: 工业芯 匠芯创 » D121 lvgl显示有几率显示失败 » 2024-10-17 13:12:42
#142 Re: 工业芯 匠芯创 » 请教下Linux下研发的工具和各种文档 » 2024-10-17 13:05:43
#143 Re: 计算机图形/GUI/RTOS/FileSystem/OpenGL/DirectX/SDL2 » 请教rtt目录下的menuconfig.py和python库里的menuconfig.py名字冲突了,如何解决呢? » 2024-10-14 17:02:24
#144 Re: 计算机图形/GUI/RTOS/FileSystem/OpenGL/DirectX/SDL2 » 请教rtt目录下的menuconfig.py和python库里的menuconfig.py名字冲突了,如何解决呢? » 2024-10-14 14:31:17
#145 Re: 工业芯 匠芯创 » 请教如何定位D133程序崩溃的位置 » 2024-10-12 16:42:40
#146 Re: 工业芯 匠芯创 » D133EBS LVGL 显示异常 » 2024-10-12 16:33:04
#147 Re: 工业芯 匠芯创 » D133运行流程 » 2024-10-12 16:27:30
#149 Re: 计算机图形/GUI/RTOS/FileSystem/OpenGL/DirectX/SDL2 » 关于 FreeRTOS 中 delay 函数的问题 » 2024-10-03 13:27:46
#153 Re: ESP32/ESP8266 » ESP32S3 通过USB无法烧录 » 2024-09-29 21:03:06
#155 Re: 工业芯 匠芯创 » D21x RTOS SDK 1.0.5使能AWTK并添加C++源码后系统运行异常 » 2024-09-24 19:08:05
找到问题了!D21x是64位机,C++的初始化函数表.init_array应该是8字节对齐的,而SDK的链接脚本里弄成4字节对齐了。
按以下patch将链接脚本里的改为8字节对齐即可:
diff --git a/bsp/artinchip/sys/d21x/link_script/gcc_aic.ld.S b/bsp/artinchip/sys/d21x/link_script/gcc_aic.ld.S
index 7600a467..561a79ed 100644
--- a/bsp/artinchip/sys/d21x/link_script/gcc_aic.ld.S
+++ b/bsp/artinchip/sys/d21x/link_script/gcc_aic.ld.S
@@ -149,7 +149,7 @@ SECTIONS
*(.rodata.*)
*(.srodata*)
*(.rodata.str1.4)
- . = ALIGN(0x4) ;
+ . = ALIGN(0x8) ;
PROVIDE(__ctors_start__ = .);
KEEP (*(SORT(.init_array.*)))
KEEP (*(.init_array))#156 Re: 工业芯 匠芯创 » D21x RTOS SDK 1.0.5使能AWTK并添加C++源码后系统运行异常 » 2024-09-24 16:26:12
试过将main线程栈开到4MB都一样。C++代码如下,非常简单,且只是加入编译没有在其它地方调用C++源码的函数。
发现只要用了C++的标准库就出问题,不用C++标准库就没有问题;即使能宏ENABLE_CPP_STD就会出问题
#include <stdio.h>
#define ENABLE_CPP_STD 1
#if ENABLE_CPP_STD
#include <vector>
#endif
class MyOutputStream {
public:
MyOutputStream(){}
MyOutputStream& operator<<(int v) {
printf("%d", v);
return *this;
}
MyOutputStream& operator<<(unsigned int v) {
printf("%u", v);
return *this;
}
MyOutputStream& operator<<(long int v) {
printf("%ld", v);
return *this;
}
MyOutputStream& operator<<(unsigned long int v) {
printf("%lu", v);
return *this;
}
MyOutputStream& operator<<(char v) {
printf("%c", v);
return *this;
}
MyOutputStream& operator<<(const char* v) {
printf("%s", v);
return *this;
}
MyOutputStream& operator<<(char* v) {
printf("%s", v);
return *this;
}
};
class A {
public:
A();
~A();
private:
#if ENABLE_CPP_STD
std::vector<int> vi;
#endif
MyOutputStream cout;
};
A::A()
{
cout << "A init\n";
#if ENABLE_CPP_STD
vi = {1, 2, 3};
vi.push_back(4);
vi.push_back(5);
cout << "is size:" << vi.size() << '\n';
for(auto &i: vi) {
cout << i << ", ";
}
cout << '\n';
#endif
}
A::~A()
{
cout << "A deinit\n";
}
void a_test()
{
A a;
}#157 工业芯 匠芯创 » D21x RTOS SDK 1.0.5使能AWTK并添加C++源码后系统运行异常 » 2024-09-24 13:51:35
- 海石生风
- 回复: 3
经测试AWTK和C++源码只要不是同时使能,系统都能正常运行。但两都同时使能编译在一起运行就会进入不了main函数并出现Exception如下:
CPU Exception: NO.1
x1(ra) : 00000000400361c6 x2(sp) : 00000000402de558 x3(gp) : 000000004026e530f
x5(t0) : 000000004026fef8 x6(t1) : 0000000000000002 x7(t2) : 00000000000000724
x9(s1) : 0000000040269670 x10(a0) : 0000000000000000 x11(a1) : 00000000000000008
x13(a3) : 00000000402a35a0 x14(a4) : 0000000066f25211 x15(a5) : 401f1830000000008
x17(a7) : 0000000000000064 x18(s2) : 00000000deadbeef x19(s3) : 00000000deadbeeff
x21(s5) : 00000000deadbeef x22(s6) : 00000000deadbeef x23(s7) : 00000000deadbeeff
x25(s9) : 00000000deadbeef x26(s10) : 00000000deadbeef x27(s11) : 00000000deadbeefa
x29(t4) : 0000000000000190 x30(t5) : 000000000000002d x31(t6) : 0000000000000000
mcause : 0000000000000001
mtval : 0000003000000000
mepc : 0000003000000000
mstatus : 8000000a00007880完整启动日志如下:
tinySPL [Built on Sep 11 2024 16:34:02]
[W] usbh_is_connected()105 usb 1 port change wait failed.
[E] main()172 Not find udisk.
qspi0 freq (input): 91636363Hz
qspi0 freq ( bus ): 91636363Hz
nftl vol: data, size 0
Selecting default config 'Luban-lite firmware'
spl read: 2549040 byte, 348034 us -> 7152 KB/s
Boot time:
108099 : Enter main
109631 : Clock and pinmux done
110143 : Console UART ready
111287 : Heap init done
114980 : Banner shown
204155 : UDISK checked
571345 : Run APP
Welcome to ArtInChip Luban-Lite 1.0.5 [D21x Inside]
Built on Sep 24 2024 13:43:04
09-24 13:45:53 I/PWM main: ArtInChip PWM loaded
09-24 13:45:53 I/touch main: rt_touch init success
09-24 13:45:53 I/gt911 main: touch device gt911 init success
[I] aic_find_panel()83 find panel driver : panel-lvds
[I] aicfb_probe()978 fb0 allocated at 0x42000040
[I] hal_ge_init()1620 dither line phys: 0x424B0100
[I] pcm1803a_init()22 pcm1803a init
09-24 13:45:53 I/PSADC main: ArtInChip PSADC loaded
[I] aic_sdmc_clk_init()548 SDMC1 sclk: 50400 KHz, parent clk 1008000 KHz
09-24 13:45:53 I/SDMC main: SDMC1 BW 1, sclk 50400 KHz, clk 400 KHz(406 KHz), div 2-62
[I] aic_sdmc_probe()665 SDMC1 driver loaded
qspi0 freq (input): 91636363Hz
qspi0 freq ( bus ): 91636363Hz
[I] spinand_info_read()473 find raw ID efaa2200
[I] spinand_flash_init()524 Enabled BUF, HWECC. Unprotected.
nftl vol: data, size 0
09-24 13:45:53 I/sensor main: rt_sensor[temp_tsen_cpu] init success
09-24 13:45:53 I/WDT main: ArtInChip WDT loaded
CPU Exception: NO.1
x1(ra) : 00000000400361c6 x2(sp) : 00000000402de558 x3(gp) : 000000004026e530f
x5(t0) : 000000004026fef8 x6(t1) : 0000000000000002 x7(t2) : 00000000000000724
x9(s1) : 0000000040269670 x10(a0) : 0000000000000000 x11(a1) : 00000000000000008
x13(a3) : 00000000402a35a0 x14(a4) : 0000000066f25211 x15(a5) : 401f1830000000008
x17(a7) : 0000000000000064 x18(s2) : 00000000deadbeef x19(s3) : 00000000deadbeeff
x21(s5) : 00000000deadbeef x22(s6) : 00000000deadbeef x23(s7) : 00000000deadbeeff
x25(s9) : 00000000deadbeef x26(s10) : 00000000deadbeef x27(s11) : 00000000deadbeefa
x29(t4) : 0000000000000190 x30(t5) : 000000000000002d x31(t6) : 0000000000000000
mcause : 0000000000000001
mtval : 0000003000000000
mepc : 0000003000000000
mstatus : 8000000a00007880#158 Re: DIY/综合/Arduino/写字机/3D打印机/智能小车/平衡车/四轴飞行/MQTT/物联网 » 请教,编译edge源码,报错找不到__aeabi_read_tp。 » 2024-09-20 12:23:14
#159 Re: 工业芯 匠芯创 » D133EBS使用 » 2024-09-20 11:56:19
#160 Re: 工业芯 匠芯创 » 看到gitee有D215了 » 2024-09-18 22:27:19
#161 Re: 工业芯 匠芯创 » 请教下Linux下研发的工具和各种文档 » 2024-09-18 22:03:40
其实就一个问题:烧录工具软件只支持Windows。可能是官方错认为大家都是在Windows下用虚拟机Linux做开发,实则在实体Linux下做开发的应该不在少数,MACOS也算类Linux环境。
RTOS SDK那边有Linux下的命令行烧录工具(upgcmd),但不稳定,且不支持指定分区烧录。
Linux SDK那边还没怎么研究,似乎没有Linux烧录工具。不过Linux下如果板子有网口很少在开发时直接烧录,而是通过网络共享的方式应用新固件或App,但没看到有文档介绍。板子没网口的话,也只能通过烧录来验证调试。
本人的开发环境是实体ManjaroLinux,目前用RTOS SDK做开发,SDK依赖库都能装上、源码编译无问题,唯独要时常开个Windows虚拟机来做烧录,肯定是不便利的。
#162 Re: 工业芯 匠芯创 » Linux系统驱动步进电机方案探索 » 2024-09-15 20:15:14
#163 Re: 工业芯 匠芯创 » Linux系统驱动步进电机方案探索 » 2024-09-13 17:41:36
#164 Re: 工业芯 匠芯创 » Linux系统驱动步进电机方案探索 » 2024-09-13 17:24:57
#165 Re: 工业芯 匠芯创 » Linux系统驱动步进电机方案探索 » 2024-09-13 17:17:12
#166 工业芯 匠芯创 » Linux系统驱动步进电机方案探索 » 2024-09-13 10:32:43
- 海石生风
- 回复: 12
目前手上有个带7寸显示屏和步进电机的新项目,用的是D21x单主控方案。步进电机只需控制AB点往返,但需要加减速控制,而Linux的PWM不支持细粒度控制,所以选了RTOS SDK进行开发,UI用AWTK。也是第一次用RT-Thread,但发现其代码质量和功能都要弱于Linux,后续还是打算切换到Linux,这就需要搞定Linux下的步进电机的加减速控制。
之前已经研究过播放wav音频 + 音频功放驱动步进电机是可行的,参见这里:
https://www.bilibili.com/video/BV1nj411D754
然而D21x的音频输出信号不是模拟信号而是PWM信号,是否可以参考上述方案用这个PWM实现step/dir接口的步进电机驱动?或者是否有其它更好的单主控驱动方案?
#167 Re: 工业芯 匠芯创 » AiBurn制作SD启动卡失败!什么原因? » 2024-09-04 13:05:26
#168 Re: 工业芯 匠芯创 » d133裸机如何进行中文显示(不用lvgl) » 2024-09-03 17:07:18
#169 Re: 全志 SOC » 三张Linux I2S声卡可以玩 5.1杜比音效吗? » 2024-09-01 17:30:46
#171 Re: 全志 SOC » linux 6怎么操作全志的GPIO呢? » 2024-08-30 22:52:37
#172 Re: 全志 SOC » linux 6怎么操作全志的GPIO呢? » 2024-08-30 17:29:37
#173 Re: 全志 SOC » ubuntu 22.03不能显示中文是哪里不对啊? » 2024-08-28 17:17:16
#174 Re: 全志 SOC » ubuntu 22.03不能显示中文是哪里不对啊? » 2024-08-28 17:07:11
#176 Re: 工业芯 匠芯创 » AWTK UI在D21x RTOS SDK平台上性能非常差,平移动画非常卡!什么原因? » 2024-08-28 09:48:38
再次测试chart demo,可以肯定,是移植有问题:打开宏ENABLE_PERFORMANCE_PROFILE后,在demo主界面只有顶部app bar的时间在按秒更新,其它元素静止时,时间每更新一次就会有以下打印信息:
packages/third-party/awtk-ui/awtk/src/base/lcd_profile.c:322
-------------------------------------
total_cost=490
draw_image_cost=4 times=6
draw_text_cost=0 times=26
fill_cost=3 times=4
stroke_cost=0 times=0
end_frame_cost=4
-------------------------------------其中 total_cost 指的是界面刷新耗时毫秒数,这里要490ms,太离谱!
上述调试说明参见这里: https://gitee.com/zlgopen/awtk/blob/master/docs/optimation.md#%E4%BA%8C%E5%B7%A5%E5%85%B7
根据上述信息可以得出UI性能弱鸡原因:
局部text更新触发整屏刷新
整屏刷新耗时半秒
每一条都是逆天般的存在!
再细看源码,LCD显存只开了双buffer没有开三buffer,AWTK官方说三buffer可以大大提高帧率。
像D21x这样的MPU HMI芯片只支持LVGL是不够的,LVGL的中文输入都是个问题,这个问题我另外发帖说明。
#177 Re: 工业芯 匠芯创 » d122串口升级失败 » 2024-08-27 16:57:53
#178 Re: 工业芯 匠芯创 » D2X怎么构建自己的工程? » 2024-08-26 15:00:11
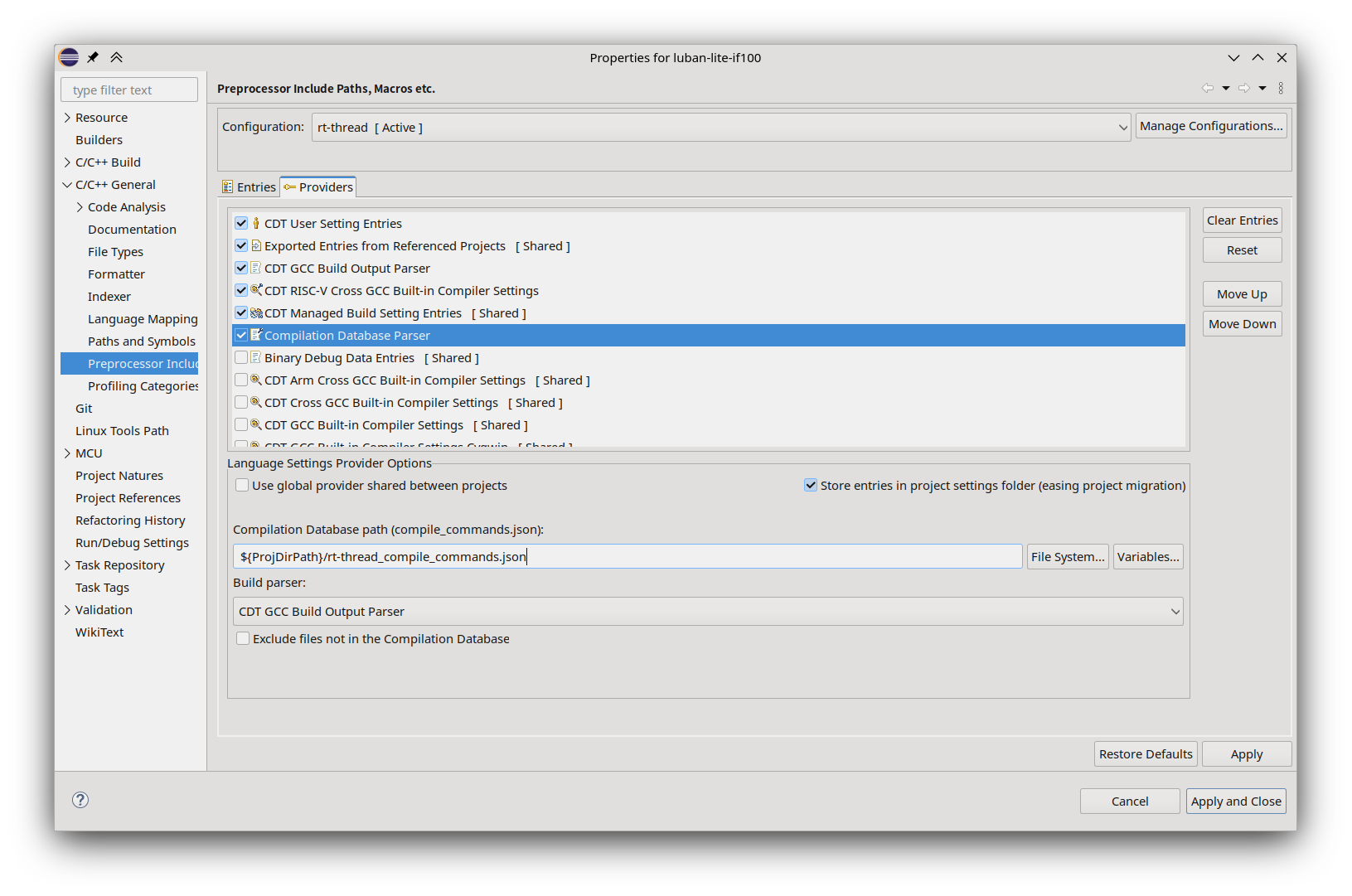
按上述改动后不知为何每次编译都更新compile_commands文件,导致编译时间变长好多。于是按下述修改,改为只有添加命令行参数时才更新:scons --cdb
# compilation database
AddOption('--cdb', dest='cdb', action='store_true', default=False, help='generate compilation database')
if GetOption('cdb'):
env.Tool('compilation_db')
compilation_db_file_name = PRJ_KERNEL + '_compile_commands.json'
env.CompilationDatabase(compilation_db_file_name)#179 Re: 工业芯 匠芯创 » d122串口升级失败 » 2024-08-26 14:54:35
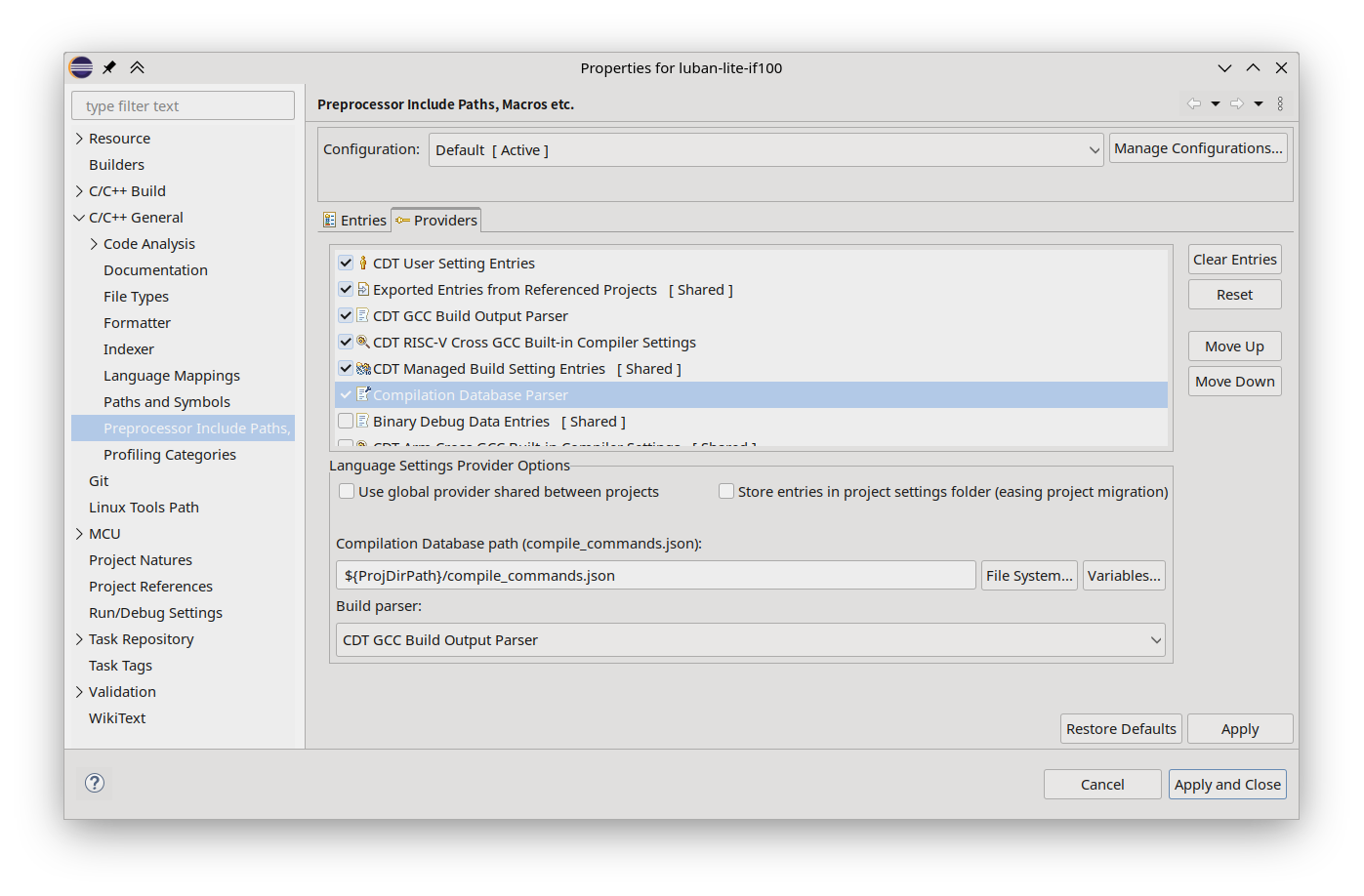
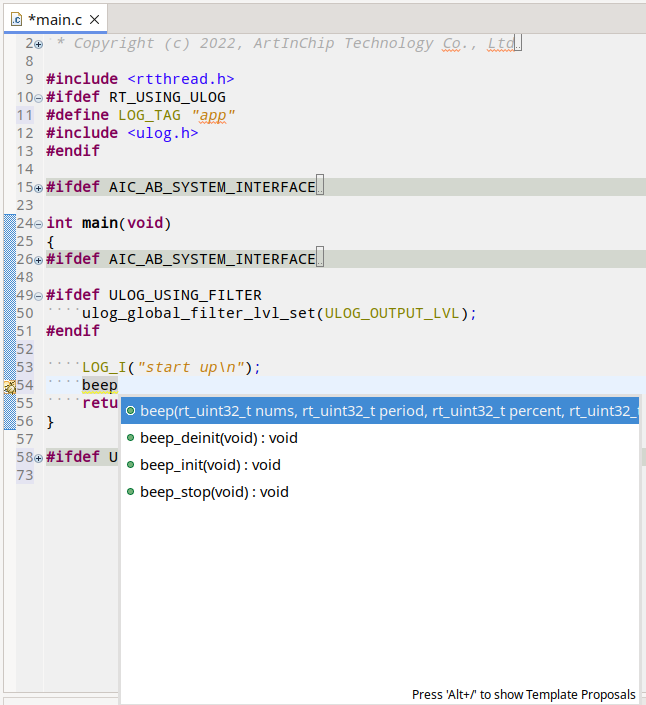
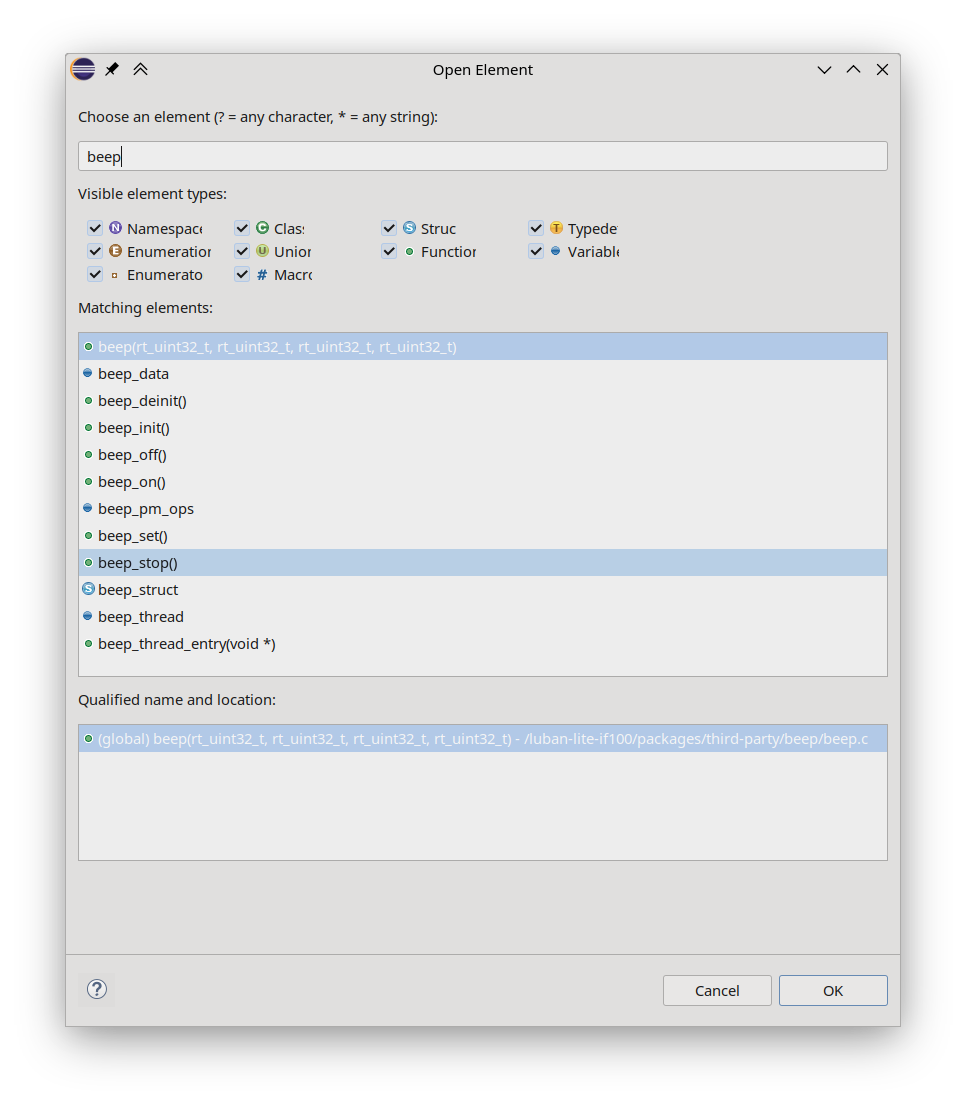
#180 Re: 工业芯 匠芯创 » D2X怎么构建自己的工程? » 2024-08-23 13:48:30
又有新发现,scons本身就可以生成compile_commands.json文件。按下述diff修改SDK根目录上的SConstruct文件:
diff --git a/SConstruct b/SConstruct
index 9750ab30..a51b0846 100644
--- a/SConstruct
+++ b/SConstruct
@@ -102,6 +102,11 @@ env['ASCOM'] = env['ASPPCOM']
# signature database
env.SConsignFile(PRJ_OUT_DIR + ".sconsign.dblite")
+# compilation database
+env.Tool('compilation_db')
+compilation_db_file_name = PRJ_KERNEL + '_compile_commands.json'
+env.CompilationDatabase(compilation_db_file_name)
+
Export('RTT_ROOT')
Export('rtconfig')编译boot时会生成baremetal_compile_commands.json
编译rt-thread时会生成rt-thread_compile_commands.json
那么搞两个项目Configuration分别叫boot和rt-thread分别各自使用上面的json db文件就可以灵活地对boot和rtos码字时进行完满的代码补全和阅读跳转了。
#181 Re: 全志 SOC » T113的tina编译gtk报错 » 2024-08-23 09:40:11
#183 Re: 全志 SOC » 有没有tf卡座接口的sd芯片啊? » 2024-08-20 09:34:22
#185 Re: 工业芯 匠芯创 » 52位的GTC计时器数值为什么要特意转成格雷码?根本没法用! » 2024-08-13 14:36:47
#186 Re: 工业芯 匠芯创 » 52位的GTC计时器数值为什么要特意转成格雷码?根本没法用! » 2024-08-13 12:05:51
#187 Re: 工业芯 匠芯创 » 52位的GTC计时器数值为什么要特意转成格雷码?根本没法用! » 2024-08-11 15:37:40
发现RTOS SDK里有这个API:aic_get_time_us,其实现就是读time寄存器,于是找到上面问题的原因了。
我用的芯片是D21x,其CSR寄存器time是64位的,所以此芯片应该没有timeh寄存器,只需读time寄存器即可。
那么,基本上只需两条指令就能获取分辨率为1us的时基,不错!
最后D21x上读取内核时基的函数如下,D13x等32位MCU就没那么便利了:要读取寄存器2次且需处理读取过程中的进位情况
static inline uint64_t _read_csr_time(void)
{
uint64_t value;
__asm__ __volatile__ ("csrr %0, time\n\t"
: "=r" (value) :
: "memory");
return value;
}PS:RTOS SDK里d13x、d12x等读取系统时基的函数 aic_get_ticks,没有处理读取过程中可能出现的进位情况(读取时低32位寄存器发生32位进位),是否是一个BUG?!
u64 aic_get_ticks(void)
{
return (((u64)csi_coret_get_valueh() << 32U) | csi_coret_get_value());
}#188 Re: 工业芯 匠芯创 » 52位的GTC计时器数值为什么要特意转成格雷码?根本没法用! » 2024-08-11 10:31:59
@xdlkliang
感谢解答。我上面的需求说法有误,我要的是分辨率为1us,精度是us级(10us左右)的时基计时。
我测试了第二种方式,发现读取timeh寄存器时会再现cpu异常。寄存器读取函数如下:
static inline uint32_t _read_csr_time_lo(void)
{
uint32_t value;
__asm__ __volatile__ ("csrr %0, time\n\t"
: "=r" (value) :
: "memory");
return value;
}
static inline uint32_t _read_csr_time_hi(void)
{
uint32_t value;
__asm__ __volatile__ ("csrr %0, timeh\n\t"
: "=r" (value) :
: "memory");
return value;
}RTOS SDK 1.0.5下经测试读寄存器time没有问题,读寄存器timeh时出现cpu异常:
CPU Exception: NO.2
x1(ra) : 00000000400338b8 x2(sp) : 000000004022d2c8 x3(gp) : 00000000401ba318 x4(tp) : 00000000deadbeef
x5(t0) : 00000000401bbef8 x6(t1) : 0000000000000001 x7(t2) : 00000000deadbeef x8(s0/fp): 0000000000000006
x9(s1) : 00000000400bb7e0 x10(a0) : 0000000000000001 x11(a1) : 000000004022d2e8 x12(a2) : ffffffff00000000
x13(a3) : 0000000040223228 x14(a4) : 0000000000000000 x15(a5) : 0000000000000000 x16(a7) : 0000000000000009
x17(a7) : 0000000040223228 x18(s2) : 0000000040223222 x19(s3) : 0000000040150570 x20(s4) : 00000000401829f8
x21(s5) : 0000000040150900 x22(s6) : 000000004015bd28 x23(s7) : 00000000401c2400 x24(s8) : 000000000000000d
x25(s9) : 0000000040223222 x26(s10) : 0000000040222dd0 x27(s11) : 00000000deadbeef x28(t3) : 0000000000000022
x29(t4) : 000000000000005c x30(t5) : 000000000000000a x31(t6) : 00000000deadbeef
mcause : 0000000000000002
mtval : 00000000c8102773
mepc : 00000000400bb7f0
mstatus : 8000000a00007880什么问题?
#189 Re: 工业芯 匠芯创 » 匠芯创 D211,7寸mipi屏核心板 » 2024-08-09 17:51:00
#191 Re: 工业芯 匠芯创 » 匠芯创 D211,7寸mipi屏核心板 » 2024-08-09 14:47:04
#194 工业芯 匠芯创 » RTOS SDK的Dynamic Module 添加C++编译选项失败 » 2024-08-07 18:01:19
- 海石生风
- 回复: 3
按照10.1. Dynamic Module 使用指南生成的aic-dm-apps默认编译及运行测试都没问题。
在尝试测试C++编译,添加C++编译选项时编译失败:
编译配置文件 aic-dm-apps/hello/SConscript 添加 CXXFLAGS
from building import *
src = Glob('*.c') + Glob('*.cpp')
cwd = GetCurrentDir()
CPPPATH = [cwd]
CXXFLAGS = ' -std=c++11'
group = DefineGroup('', src, depend = [''], CPPPATH=CPPPATH, CXXFLAGS=CXXFLAGS)
Return('group')编译输出:
$ scons --app=hello
scons: Reading SConscript files ...
args.outfile: /home/chenss/projects/test/source/luban-lite/partition_table.h
scons: done reading SConscript files.
scons: Building targets ...
CXX hello/cpp_test.o
riscv-none-embed-g++: error: -std=c++11: No such file or directory
scons: *** [hello/cpp_test.o] Error 1
scons: building terminated because of errors.#195 Re: 工业芯 匠芯创 » D2X怎么构建自己的工程? » 2024-08-02 15:33:40
#199 Re: 全志 SOC » V3s/S3/f1c100s通过USB启动Linux,并把SD NAND/TF卡挂载为U盘, 可以dd或Win32DiskImager任烧写 » 2024-07-28 12:26:13
#200 Re: DIY/综合/Arduino/写字机/3D打印机/智能小车/平衡车/四轴飞行/MQTT/物联网 » 单片机IO如何控制24V正输出? » 2024-07-28 10:16:00
saub wrote:
海石生风 wrote:
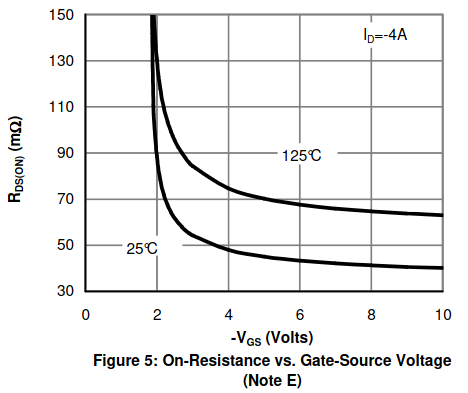
PMOS开关电路,很常见呀。不过要注意VGS数值不要超过12V
/files/members/1798/屏幕截图_20240722_122744.png这个电路有问题,这个GS上并一个这么大的电容,这个PMOS大负载的时候分分钟烧掉
GS并联电容是为了减小驱动容性负载导通时的瞬时电流,使其不超过MOS管的最大漏极电流,起到保护作用。实在想不出哪里会烧掉。
东莞哇酷科技有限公司开发